







系列文章目录
“光晰本质,谱见不同”,光谱作为物质的指纹,被广泛应用于成分分析中。伴随微型光谱仪/光谱成像仪的发展与普及,基于光谱的分析技术将不只停留于工业和实验室,即将走入生活,实现万物感知,见微知著。本系列文章致力于光谱分析技术的科普和应用。
前言
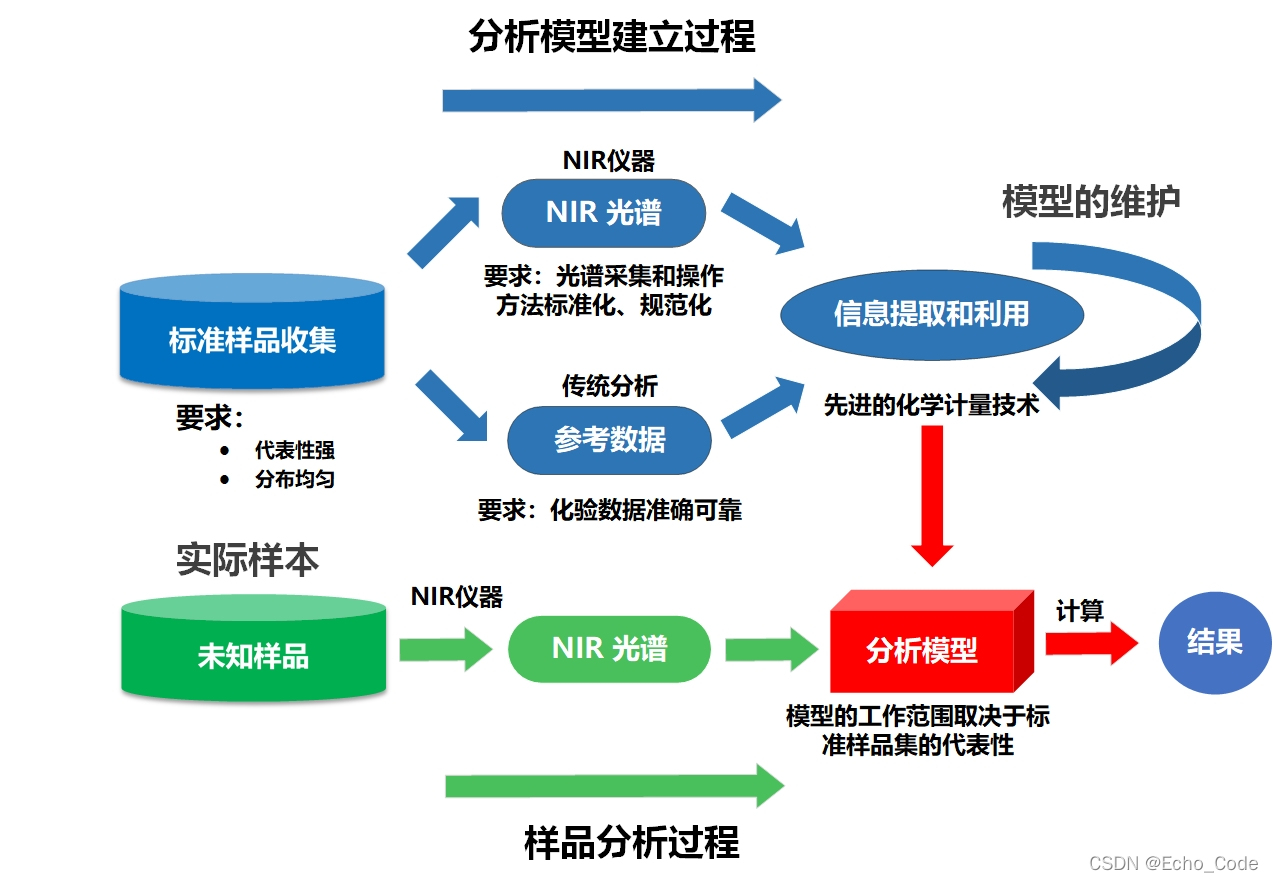
典型的光谱分析模型(以近红外光谱作为示意,可见光、中远红外、荧光、拉曼、高光谱等分析流程亦相似)建立流程如下所示,在建立过程中,需要使用算法对训练样本进行选择,然后使用预处理算法对光谱进行预处理,或对光谱的特征进行提取,再构建校正模型实现定量分析,最后针对不同测量仪器或环境,进行模型转移或传递。因此训练样本的选择、光谱的预处理、波长筛选、校正模型、模型传递以及上述算法的参数都影响着模型的应用效果。
针对光谱分析流程所涉及的常见的训练样本的划分、光谱的预处理、波长筛选、校正模型算法建立了完整的算法库,名为OpenSA(OpenSpectrumAnalysis)。整套算法库的架构如下所示。
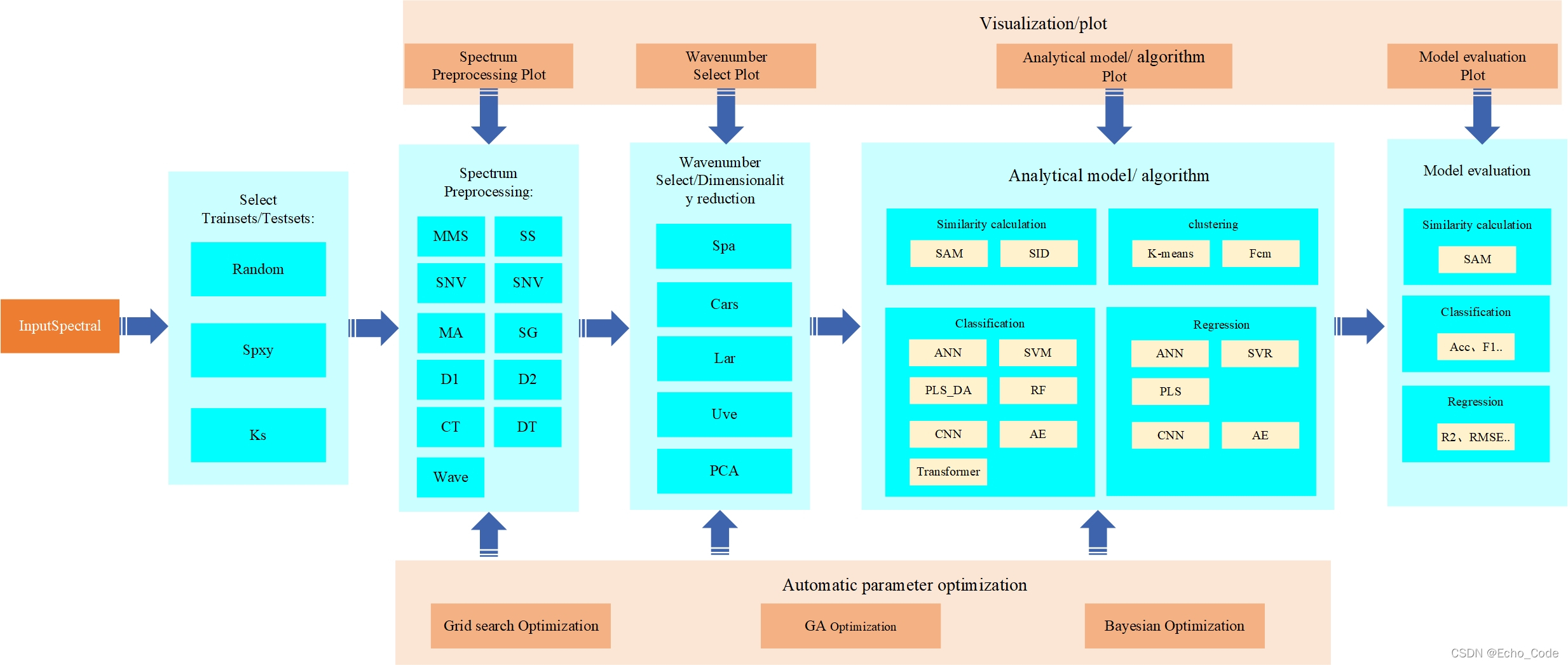
样本划分模块提供随机划分、SPXY划分、KS划分三种数据集划分方法,光谱预处理模块提供常见光谱预处理,波长筛选模块提供Spa、Cars、Lars、Uve、Pca等特征降维方法,分析模块由光谱相似度计算、聚类、分类(定性分析)、回归(定量分析)构建,光谱相似度子模块计算提供SAM、SID、MSSIM、MPSNR等相似计算方法,聚类子模块提供KMeans、FCM等聚类方法,分类子模块提供ANN、SVM、PLS_DA、RF等经典化学计量学方法,亦提供CNN、AE、Transformer等前沿深度学习方法,回归子模块提供ANN、SVR、PLS等经典化学计量学定量分析方法,亦提供CNN、AE、Transformer等前沿深度学习定量分析方法。模型评估模块提供常见的评价指标,用于模型评估。自动参数优化模块用于自动进行最佳的模型设置参数寻找,提供网格搜索、遗传算法、贝叶斯概率三种最优参数寻找方法。可视化模块提供全程的分析可视化,可为科研绘图,模型选择提供视觉信息。可通过几行代码快速实现完整的光谱分析及应用(注: 自动参数优化模块和可视化模块暂不开源,等毕业后再说)
本篇针对OpenSA的光谱波长筛选模块进行代码开源和使用示意。
一、光谱数据读入
提供两个开源数据作为实列,一个为公开定量分析数据集,一个为公开定性分析数据集,本章仅以公开定量分析数据集作为演示。
1.1 光谱数据读入
# 分别使用一个回归、一个分类的公开数据集做为example
def LoadNirtest(type):
if type == "Rgs":
CDataPath1 = './/Data//Rgs//Cdata1.csv'
VDataPath1 = './/Data//Rgs//Vdata1.csv'
TDataPath1 = './/Data//Rgs//Tdata1.csv'
Cdata1 = np.loadtxt(open(CDataPath1, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
Vdata1 = np.loadtxt(open(VDataPath1, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
Tdata1 = np.loadtxt(open(TDataPath1, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
Nirdata1 = np.concatenate((Cdata1, Vdata1))
Nirdata = np.concatenate((Nirdata1, Tdata1))
data = Nirdata[:,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









