







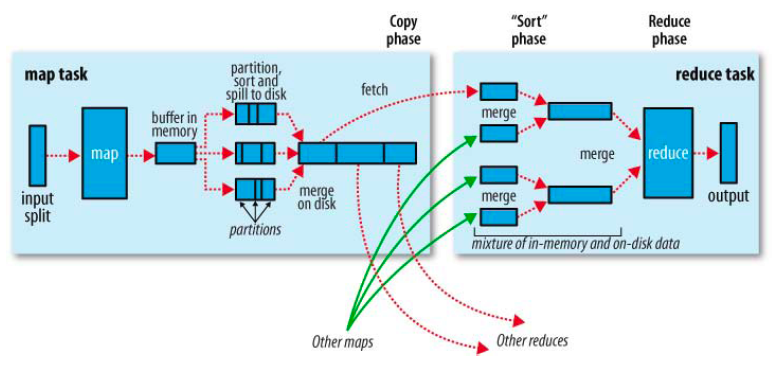
1.在Job初始化时,设定input format,output format,key和value。
2.将HDFS中的block划分成split分给map(在hdfs.xml中dfs.block.size设置block大小)。
3.map通过input format读取(key, value)并处理。处理后将生成数据放入buffer(buffer大小可设定)。
buffer结构:除了key和value之外,还包括meta。一个meta包括了index,key length,value length,partition number。index表示meta所对应的(key, value)的索引坐标,partition number表示对应(key, value)的partition号。
4.当buffer放满时,将buffer放入sort and spill中进行排序,排序时以partition为主键,key为副键。
(partitions可由用户定义,数量由reduce个数确定。例如:terasort设定的partitions确保了:partition0的所有key一定大于partition1。这样就保证了,sort and spill之后在整个map output文件中key是有序的。grep设定的partitions确保了:partition0的所有key(也就是匹配到的词)都相同,这样,sort and spill之后partition中key的个数就是匹配到词的个数。)
5.排序结束后,生成多个(有可能只有一个)map output文件和对应的index文件(标记着mapout的partition的索引,也就是partition0,partition1...partitionN在mapout文件的起始位置),将多个(如果只有1个就不需要merge)mapout和对应的index文件merge成两个文件,最后在一个slave上只有一个mapout和对应的一个index。
6.Reduce根据index文件通过shuffle,fetch对应partition号的数据(也就是reduce0 fetch partition0)。
(fetch过程在集群中是通过网络完成的,如果是pesudo模式shuffle会直接读取本地文件,也就是绕过了真正的shuffle)。
7.多个Reduce处理后进行merge,直到只剩下一个文件为止,通过output format输出结果。















 2344
2344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









