







Abstract
自闭症谱系障碍(ASD)是一种脑部疾病,通常特征在于社交沟通和互动不足,以及限制性和重复性的行为和兴趣。在过去的几年中,与用于分类目的的典型对照相比,磁共振成像(MRI)的使用有所增加,以帮助检测自闭症受试者的常见模式。在这项工作中,我们提出了一种使用功能性和结构性MRI信息对ASD患者与对照组进行分类的方法。 大脑区域之间的功能连通性模式,以及皮质包裹之间的灰质体积的体积对应关系,分别用作功能和结构处理管线的特征。 分类网络是以无监督方式训练的堆叠式自动编码器和以有监督方式训练的多层感知器的组合。对来自368个ASD患者和449个对照受试者的多站点国际自闭症脑成像数据交换I(ABIDE I)数据集中的817例病例进行了定量分析,当使用一组分类器时,其分类精度为85.06±3.52%。从功能和结构来源合并信息的性能大大优于已实施的单个管道。
1. Introduction
自闭症谱系障碍(ASD)是一种神经系统疾病,其特征在于社交沟通方面的持续性缺陷(APA,2013),严重程度往往随着时间的推移而发展(Gotham等,2012; Szatmari等,2015)。这些症状通常出现在生命的头两年,包括沟通和互动困难,兴趣受限和重复行为,以及在生活的各个领域正常工作的能力下降。在美国,ASD的患病率估计为1.47%,每位患者的平均终生成本超过100万美元(Buescher等人,2014)。
研究表明,该疾病的病因是多种因素共同作用的结果,包括遗传学,大脑结构和功能以及环境影响(APA,2013; Ha等人,2015)。当前的诊断是基于访谈的,并且最常见的是通过执行“自闭症诊断观察时间表”(Lord等,1989)或“自闭症诊断访谈-修订版”(Lord等,1994)进行。尽管这些方法非常准确,但由于神经解剖学尚不清楚,因此无法指出行为症状背后的生物学基础(Riddle等人,2017; Subbaraju等人,2017)。尽管如此,在过去的几十年中,针对自闭症谱系症状的磁共振成像(MRI)结构(s-MRI) 和功能性(rs-fMRI) 大脑异常的研究有所增加。然而,尽管MRI研究已经提供了许多关于ASD的神经发育特征的暗示(Ecker等人,2015),但是这些发现通常不能涵盖整个ASD受试者。结构MRI研究通常侧重于体积和形态分析,以检查异常的大脑解剖结构,而功能性MRI研究则试图研究局部和全局的大脑连接模式。
结构MRI中的绝大多数方法不是解决固有的分类问题,而是试图指出ASD患者与对照组之间的常见模式。例如,基于体素的形态分析(Riddle等人,2017)显示,患有ASD的2至4岁儿童的总脑容量增加,并且左前颞上回增加。但是,在以后的年龄中,图片并不十分清晰。而艾尔沃德等。 (2002年)观察到ASD和成人对照之间没有体积差异,其他研究得出的结论是总脑体积仍可观察到(Herbert等,2003; Palmen等,2005)。其他工作研究了大脑中特定兴趣区域(ROI)的体积变化,但未能得出明确的结论。 Palmen等。 (2005年)报告说,大脑所有叶的灰质增加,而Courchesne等。 (2007)观察到灰质体积的增加,特别是颞叶。相反,赫伯特等。 (2003年)报道了增加白质的发现,而Palmen等人。 (2005年)指出,在ASD与对照组之间,关于白质的体积没有差异。相反,Jou等。 (2011年)报道了自闭症患者的蛋白质量减少。这些不一致的发现可能是由于样本量较小或每种情况下都是在单个地点收集数据而引起的(Riddle等人,2017),而采集地点的选择对基本图像特性有重大影响(Nielsen等人,2013)。 Kong等人(2019年)进行了一项有前途的研究,以解决基于结构信息的分类问题。 基于为每个对象构建一个单独的大脑网络,以提取每对感兴趣区域之间的连通性特征。然后对这些功能进行排序,并通过深度神经网络分类器执行ASD与控件的分类。
静止状态功能MRI中的功能连接被广泛用于描述大脑皮层分裂和脑部疾病的远程关系(Du等人,2018; Jiang and Zuo,2016)。主要思想是检测功能互连区域之间的大脑网络,这是通过使用包含来自大脑不同区域的相关性的连接矩阵来完成的(Heinsfeld等人,2018; Subbaraju等人,2017)。近年来,深度学习技术已成为ASD分类的主要趋势(Calhoun和Sui,2016; Iidaka,2015; Ju等人,2019; Plis等人,2014)。流行的方法包括将简单的多层感知器(MLP)网络与堆叠式自动编码器的无监督训练相结合(Guo等,2017; Kim等,2016)。即使几种方法设法获得了相对较高的分类精度,但仍需要解决所提出策略的一些缺点。 首先,大多数研究使用少量的受试者进行分类。由于泛化不佳,这往往导致结果不可靠。 真正的挑战是跨大型数据集复制发现。仅当使用数十种情况时(Arbabshirani等人,2017)才能获得高于0.9的准确度,而引入更大的数据集时(Heinsfeld等人,2018)准确性会大大降低。其次,大多数研究都使用在单个站点上获取的数据。由于图像属性高度依赖于每个机构执行的成像协议,因此此过程也无法有效地解决问题。 总而言之,很少有研究使用多站点数据,其中许多主题都超过800。此外,这些研究还考虑了只关注功能发现而忽略结构信息的方法。据我们所知,尽管总共仅使用了30名受试者的样本量,但只有一项研究进行了融合方法,将fMRI和扩散张量成像(DTI)信息相结合以进行ASD识别(Deshpande等,2013)。
在本文中,我们提出了ASD与对照组的分类方法,该方法合并了在大型多站点数据集上评估的功能性和结构性MRI信息。
- 功能数据连通性矩阵包含有关来自感兴趣区域对的平均血氧水平依赖性(BOLD)信号的相关系数的信息。
- 结构数据连通性矩阵包含有关皮质灰质体积的信息。
主要假设是,使用多站点数据并结合结构信息和功能信息可能潜在地揭示到目前为止尚未开发的模式,同时由于缺乏对特定协议的依赖,因此可以提高分类的通用性。
我们提出的方法包括几个步骤,包括结构和功能数据的预处理,提取由连通性矩阵表示的特征,利用Fisher分数作为特征维数减少技术以及最终通过对数据进行分类。自动编码器和多层感知器的集合。 具体来说,我们的建议受到了Heinsfeld等(2018)和Kong等(2019)人的工作的启发,分别根据功能或结构数据处理ASD的分类。即使Heinsfeld等人的方法(在本文中也是如此),在这两篇论文中,分类任务本身都是以类似的方式执行的。 (2018)不包括任何降维技术,Kong等人的方法(2019)仅基于来自单个放映站点的图像子集。我们的方法是使用大型的国际多站点自闭症脑成像数据交换I(ABIDE I)数据集进行评估的(Di Martino等,2014)。此外,我们展示了所提出方法的一般性,其中包括留一站式交叉验证实验。
2. Material and methods
2.1. Dataset
ABIDE I数据集用于进行我们的研究(Di Martino等,2014)。它是在涉及17个国际站点的合作下于2012年8月发布的,它包含1112例病例,其中539例来自自闭症患者,573例来自典型对照。各组的受试者年龄中位数为14.7岁。这些病例包括结构性MRI图像和静止状态fMRI系列图像,以及这项工作中未使用的临床数据。
有关受试者的结构数据和表型信息直接从ABIDE I计划中获得。但是,包含功能信息的预处理数据集是从“预处理Connectomes项目”(PCP)获取的(Craddock等人,2013)。所有rs-fMRI系列均接受处理管线CPAC(可用于连接组分析的可配置管线),其中包括切片时间校正,运动校正和强度归一化,带通滤波(0.01 Hz-0.1 Hz)以及对MNI152的空间配准模板空间。在PCP上可以获得各种功能数据的导数,但是,分类流水线感兴趣的一项是大脑不同区域中BOLD信号的时间序列。测试了两种不同的常用图集:AAL(自动解剖标记)图集(Tzourio-Mazoyer等,2002)和CC200(Cameron Craddock的200 ROI)碎片图集(Craddock等,2012)。但是请注意,由于运动伪影,在某些情况下功能数据会变得无用,因此PCP无法提供。使用平均纵向位移为每个个案计算运动伪像,如果运动伪像超过0.2的值,则丢弃相应的对象。平均框架位移是头部运动的量度,它比较当前体积和先前体积之间的运动。这给我们留下了884个rs-fMRI受试者的数据集,包括408名ASD患者和476个对照病例。
关于结构信息,对每个MRI体积使用Destrieux图集(Destrieux等,2010)进行皮质细胞分裂。为此,我们采用了著名的Freesurfer软件(Fischl等,2002)。用于提取有用信息的管道涉及多个阶段,最值得注意的阶段是强度归一化,头骨剥离,将体积配准到一个公共空间,进行分割,最后是皮层分隔。除皮层划分外,还为每个包裹计算了一系列统计度量,例如灰质体积,皮质厚度和曲率。但是,由于某些结构MRI体积中存在伪影,因此此处理并非总是可行的。总共成功处理了1014例病例,包括475名ASD患者和539名对照对象。
由于我们的目标是提出一种同时处理结构和功能信息的分类策略,因此需要注意的是,在使用预处理管道后交叉引用其余案例会产生总共817个案例(368 ASD + 449个控件)在原始数据集的两个子集中。 表1总结了所使用的数据集的详细信息,包括项目中涉及的每个采集站点的单独清单。
2.2. Functional data classification pipeline
一旦使用CPAC管道对数据进行了预处理,并提取了来自不同大脑区域的平均BOLD信号的时间序列,下一步便是建立连接矩阵。这种矩阵是针对每种情况分别构建的,包含有关由地图集定义的每对区域之间的BOLD系列相关性的信息(AAL地图集由116个区域组成,而CC200地图集由200个区域组成)。因此,根据使用的图集,连通性矩阵的尺寸为116×116或200×200,并且矩阵内的每个元素
i
j
ij
ij是从区域
i
i
i和
j
j
j为平均BOLD级数计算的皮尔逊相关系数。 根据皮尔逊相关系数的定义,矩阵的元素范围从-1到1,并且主对角线上的所有元素都等于1,因为它们对应于信号与其自身的相关性。另外,由于相关系数计算的可交换性质,这样的矩阵是对称的。连接矩阵的示例如图1所示。因此,我们只对连接矩阵的上三角感兴趣(还不包括主对角线),因为矩阵的其余部分是多余的。然后将感兴趣的部分展平为一维向量,以进行进一步处理。在AAL地图集的情况下,此类向量包含6670个元素,而在使用CC200地图集的情况下,其包含19个900个元素。

由于特征向量的高维性,我们在流水线中包括了降维技术。 此步骤的优点是我们避免过度拟合,并使模型更通用。 用于实现此目标的技术是Fisher分数计算,该函数按特征的顺序对特征进行排序,并因此确定哪些特征的重要性较低(Chen和Lin,2006)。 它测量两组实数的判别力,得分值越大,某个特征的等级越高。 给定训练向量
x
k
x_k
xk,如果肯定实例的数量是
n
+
n_{+}
n+,否定实例的数量是
n
−
n_{-}
n−(其中肯定和否定实例表示属于一个类别或另一个类别),则第
i
i
i个特征的Fisher分数为:
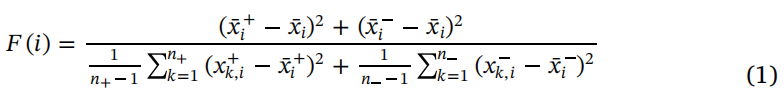
其中
x
ˉ
i
\bar{x}_i
xˉi,
x
ˉ
i
+
\bar{x}_i^+
xˉi+和
x
ˉ
i
−
\bar{x}_i^-
xˉi−是整体的第
i
i
i个特征的均值,正集合
x
k
,
i
+
x_{k,i}^{+}
xk,i+和负集合
x
k
,
i
−
x_{k,i}^{-}
xk,i−分别是第
k
k
k个正实例的第
i
i
i个特征和第
k
k
k个负实例的第
i
i
i个特征(Kong等,2019)。 分子表示组间区别,而分母表示组间区别。
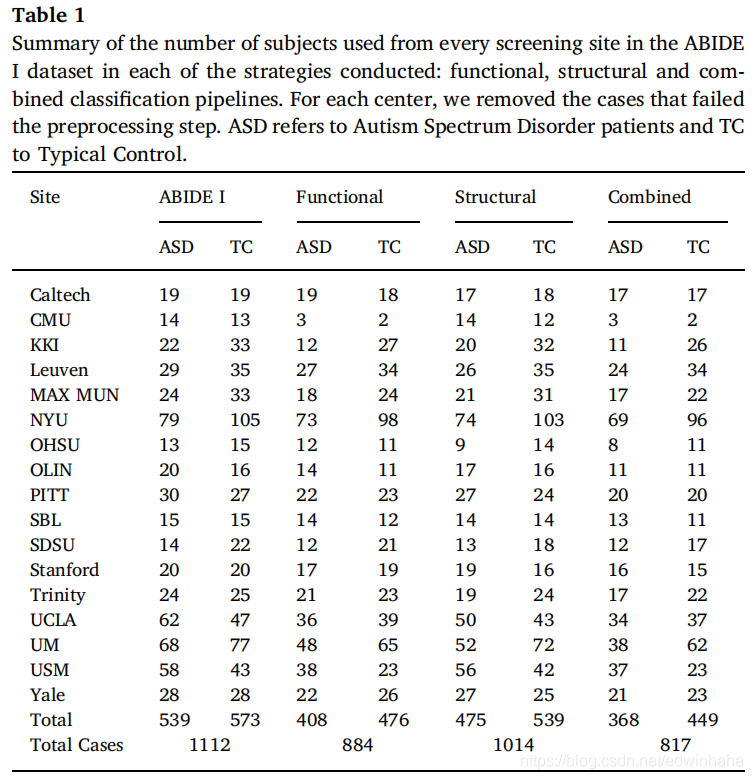
在应用Fisher分数后剩下的是缩减特征向量,该特征向量成为了分类器的输入向量。分类步骤本身分两个阶段执行。 第一个包括对堆叠式自动编码器的无监督训练。 自动编码器是一个简单的网络,试图尽可能精确地重建输入。给定输入向量,它会尝试学习其较低维的表示形式,然后可以从中重建原始向量。这两个步骤称为编码和解码。简单来说,它具有一个输入层,一个对输入进行编码的隐藏的完全连接层以及一个对编码表示进行解码的完全连接输出层。通过反向传播调整模型的参数,直到输入和输出之间的差异最小为止。栈式自动编码器基本上由两个或多个自动编码器组成,并且具有比单个自动编码器更好的学习能力。当堆栈由两个自动编码器组成时,第一个编码级的输出将作为第二个自动编码器的输入。然后,再次以双重方式完成解码阶段,第二个自动编码器解码其输入,然后第一个自动编码器解码原始输入向量。这种结构的图示在图2(b)中。自动编码器训练的最终结果在分类步骤的第二阶段显而易见,这是对带有两个隐藏层和一个二进制输出层的多层感知器(MLP)的监督训练。隐藏层中的节点数与堆叠式自动编码器的编码层中的节点数相对应。这确保了可以使用经过训练的自动编码器的权重来初始化MLP的权重。因此,MLP能够从隐藏层中的输入向量中学习隐藏特征,然后通过softmax激活在最终层中对主题进行相应的分类。 这在图2(c)中示出,其中以与图2(b)相同的方式对从自动编码器初始化的相应权重进行颜色编码。为了防止过度拟合,在隐藏层中引入了辍学,并引入了附加的正则化项和批量归一化以提高收敛性。
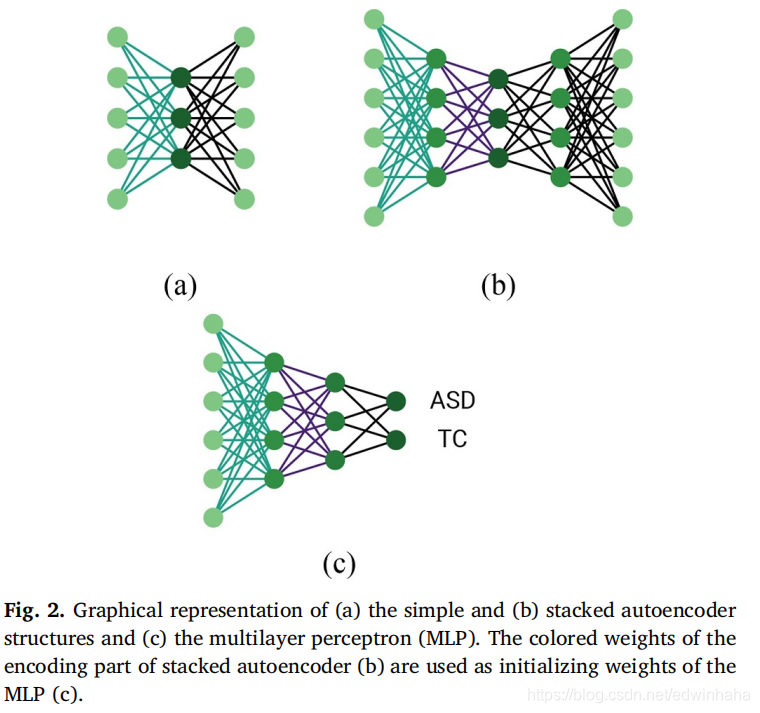
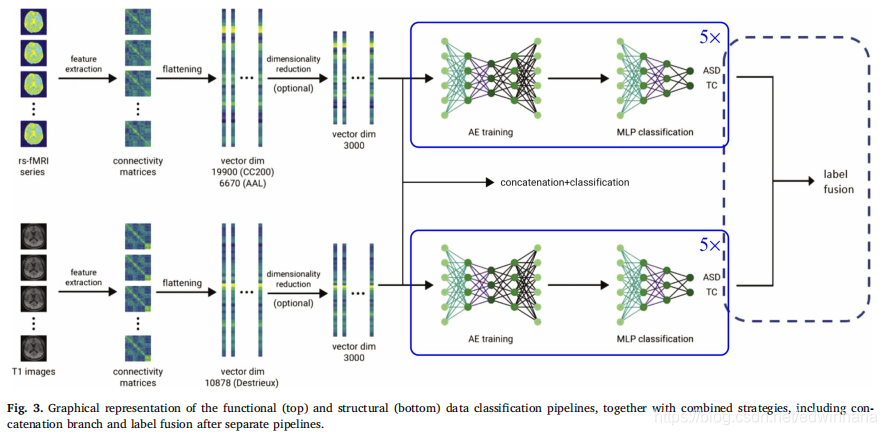
为了获得更可靠的结果,我们在最后一步中使用了一组分类器,以便每个人都可以学习不同的特征表示。具体来说,我们训练了总共5个分类器的集合,这些分类器通过更改自动编码器和MLP的隐藏层中的节点数来获得。在这种情况下,每个主题的特征向量都作为所有分类器的输入,标签分配是通过平均softmax激活概率来进行的。基本假设是,具有不同学习特征表示方式的其他分类器可以在分类准确性方面增加一定的改进余地,并使决策更加稳健(Kamnitsas等人,2017年)。作为总结,完整的功能流水线如图3所示(顶部),其中显示了所有值得注意的步骤,包括将连接矩阵展平为矢量,降维,训练堆叠式自动编码器和MLP分类。
2.3. Structural data classification pipeline
结构数据分类的方法在设计上与功能分类管道非常相似,以便获得二者的后续平滑集成。因此,再次为每个对象建立一个连通性矩阵,并将上三角部分提取并展平以成为特征向量。功能和结构管道之间的主要区别是建立连接矩阵的方式。而不是计算皮尔逊相关系数,我们对由Destrieux地图集(148个区域,每半球74个区域)定义的每对皮质区域中的灰质体积之间的关系感兴趣。即使在Freesurfer流水线之后计算出的特征很容易使用,其基本思想是构造这样一个矩阵,以使这些特征反映特定主题区域之间的体积对应关系。这样,即使数据集高度变化并且涵盖了受试者之间较大的年龄跨度,以矩阵为代表并为每个受试者构建的网络也变得可以相互比较。因此,矩阵的每个元素
i
j
ij
ij是两个宗地
i
i
i和
j
j
j之间的体积对应关系,其定义为:

其中 g m ( i ) gm(i) gm(i)和 g m ( j ) gm(j) gm(j)是ROIs i i i和 j j j的灰质体积(Kong等人,2019)。
结果,从连通性矩阵中提取的扁平化矢量具有10878个特征。 与功能流水线类似,Fisher分数用于减少特征向量的维数,并将新获得的特征向量馈送到5个堆叠式自动编码器和MLP的集合中,以进行分类任务。 结构管道如图3所示(底部)。
2.4. Combined data classification pipeline
这项工作中提出的主要贡献之一是将两个先前描述的管道合并为一个,目的是通过考虑不同类型的信息来改善分类结果。由于功能和结构管线学习独立的功能,因此将它们合并在一起可以在某种程度上减轻错误。请注意,只有成功进行了功能和结构预处理管道的情况才能视为组合分类管道数据集的一部分。在ABIDE I数据集中,结果是817个案例的集合。
使用两种不同的策略进行功能和结构信息的合并。第一种策略是在降维阶段之后将结构和功能特征向量进行级联。这样,我们合并了功能数据和结构数据,然后执行自动编码器训练,以便自动蔓延程序可以确定哪些模式更有用。我们选择在降维步骤之后进行合并,因为原始特征向量的大小取决于图集的选择,因此对于结构和功能数据而言是不同的,这会向一侧或另一侧引入潜在的偏差。随后,使用新获得的向量(长度为6000)或使用Fisher分数再次降低其维数来进行分类,以获得另一个向量作为网络的输入。分类阶段保持不变,包括由无监督的堆栈自动编码器训练和随后的MLP的有监督训练组成的合奏(图3,串联分支)。第二种策略包括使用单独的分类管道(如前所述),然后是用于选择最终标签的决策方法。 换句话说,我们使用相应的功能和结构训练以及验证数据独立地训练了自动编码器和多层感知器的功能和结构集成,从而产生了10个softmax激活。通过平均10个softmax激活概率或通过多数投票策略获得最终输出。这种方法如图3所示(标签融合策略)。
2.5. Validation
通过执行10倍交叉验证来验证每个模型。在每一折中,将10%的相应数据集用于测试分类器,而将其余90%的案例用于训练和验证,其中训练包括70%的可用集合验证。 使用该策略可以在训练和测试不同数据子集时评估模型的健壮性和行为效果。重要的是要注意,在每个折叠中,对组合进行拆分的方式应使子集保持类平衡,并且包含来自所有或几乎所有筛选站点的病例。利用这种方法使模型尽可能通用。自然地,在使用组合方法训练2个分类器或一组分类器的情况下,对于所有分类器,在一定的折叠度下,训练,验证和测试集的划分是相同的。
使用准确性作为度量标准对模型进行了评估,这是最新技术中最常见的度量。尽管不能保证我们的方法中使用的数据集与以前的模型完全相同,但这可以对我们的结果与以前的模型进行定量比较。此外,由于类别不平衡,我们对每个实验的敏感性和特异性值进行了量化。最终,我们还使用最佳模型进行了“一站式”交叉验证,以便分别分析从17个筛查点中分别获得的准确性,敏感性和特异性。这样就可以将我们的结果与其他最新研究成果进行定性和定量比较,尤其是因为先前的某些研究仅使用其中一个地点收集的数据进行。
为了对通过提出的模型获得的结果进行统计分析,我们进行了单向方差分析(变异性分析)测试,以及事后Tukey HSD(诚实显着差异)测试,目的是表明哪些模型存在显着差异。对三组模型分别基于功能数据,结构数据库和组合数据分别进行了方差分析和Tukey HSD测试。选择了95%的置信区间,这意味着p值小于0.05表示某个结果与另一个结果相比具有很高的统计显着性。请注意,在评估10倍交叉验证过程的结果时,t检验估计存在固有误差。但是,在分析II型错误(即无法检测到算法之间的真正差异)时,它具有很高的统计辨别力。
2.6. Qualitative analysis
根据Ha等(2015年),默认模式网络(DMN)是最常被分析的功能性大脑网络之一,显示了ASD和对照组之间大脑活动的差异。在患有这种疾病的成年人中,DMN通常倾向于连接不足,而在具有相同病理的儿童中则倾向于连接过度。它包括大脑的几个部分,包括后扣带回,脾后皮质,顶顶外侧皮,额前内侧皮层,额上回和颞叶。与基于任务的筛查相比,它在静止状态功能性MRI(rs-fMRI)中表现出更大的活性(Greicius等,2003),这就是为什么它对于ABIDE I数据集特别感兴趣。
为了将我们的方法与常见的临床发现进行比较,我们提出了特征分级的定性测试。因为Fisher评分是通过所有特征的独特性来对所有特征进行排名,所以该想法是分析排名最高的特征是否与先前的临床和科学研究中观察到的发现相对应,并检查是否存在潜在的通用模式。
3. Results
表2总结了进行的实验和获得的准确性,提供了交叉验证倍数上的标准偏差以及敏感性和特异性值的更多详细信息。我们单独或组合测试了功能和结构管道的准确性。后者可以通过在分类之前将前两者串联(即将功能和结构信息一起训练神经网络)或独立地优化功能和结构管线,然后将结果组合(单独的管线)来获得。
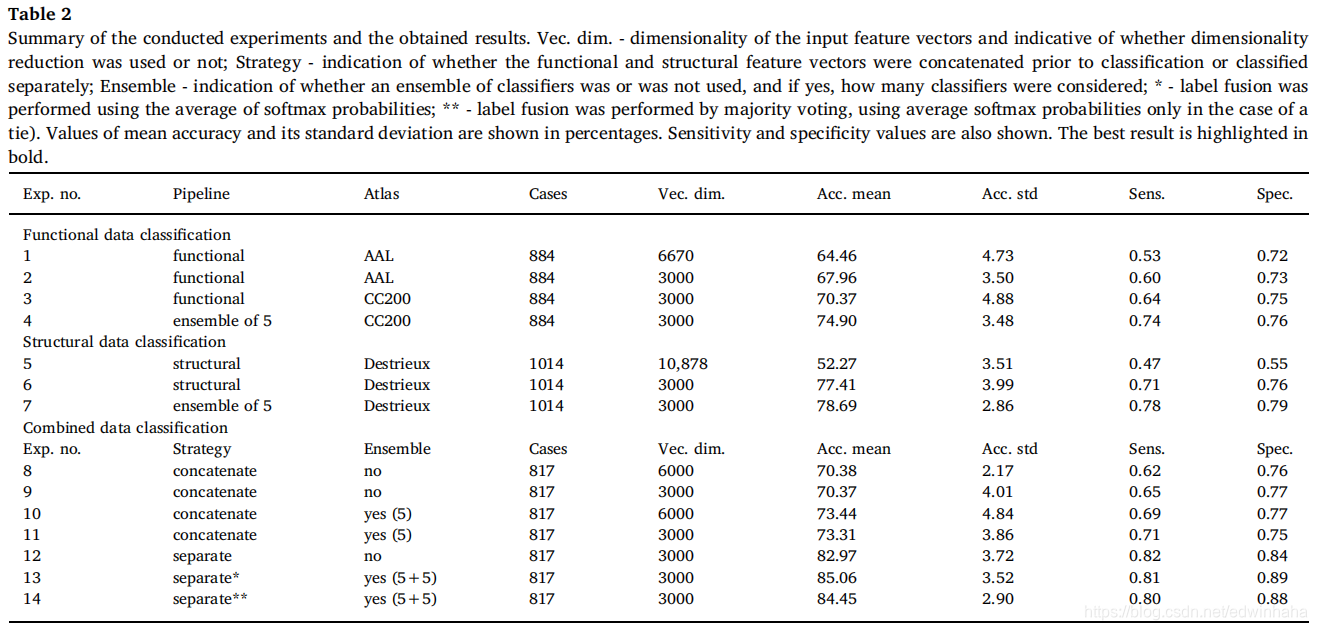
为了测试管道的功能数据分类,提出了四个实验。其中两个被认为是使用AAL地图集进行了预处理的数据,而其他两个则使用了通过CC200地图集获得的数据。在这两种方法中,我们都考虑了输入特征向量的两种大小,无论是否使用降维方法。
- 使用AAL地图集时,不降低尺寸和降低尺寸的精度分别达到64.46%和67.96%。
- 使用CC200地图集时,总体精度较高。当使用Fisher分数减小输入向量的大小时,我们报告的准确性为70.37%。
- 通过使用分类器集合进行分类,进一步探索了使用降维CC200地图集的最后一个模型。达到了改进,准确性为74.90%。
比较这些策略的结果时,所有成对的p值均低于0.05。
对于结构信息,当使用原始特征向量和使用简化特征向量时,我们还测试了两种情况。获得的两个精度差异很大。(1)使用整个特征向量,我们仅获得52.27%的精度,(2)而包括降维,精度为77.41%。此外,(3)在后一种方法上使用集成分类,准确性提高了,在交叉验证的10倍中平均准确性为78.69%。所有三个成对的p值均具有统计学意义(p <0.05)
合并的方法分为两个主要策略。第一种利用通过结构和功能数据预处理获得的简化向量的级联 。第二种方法是对功能和结构数据进行单独分类,然后对获得的标签进行融合 ,方法是对softmax输出求平均值或进行多数表决 。针对这两种策略,提出了几种模型,包括对级联向量进行降维或使用分类器集成进行分类。当考虑单独的分类策略时,使用5个功能和5个结构数据分类模型的集合,然后对所有10个softmax概率求平均值,可获得最佳结果。这种方法的平均准确度达到85.06%。除实验13和14外,所有成对比较均具有显着性(p <0.05),这仅在于将标签融合在一起的方式不同。
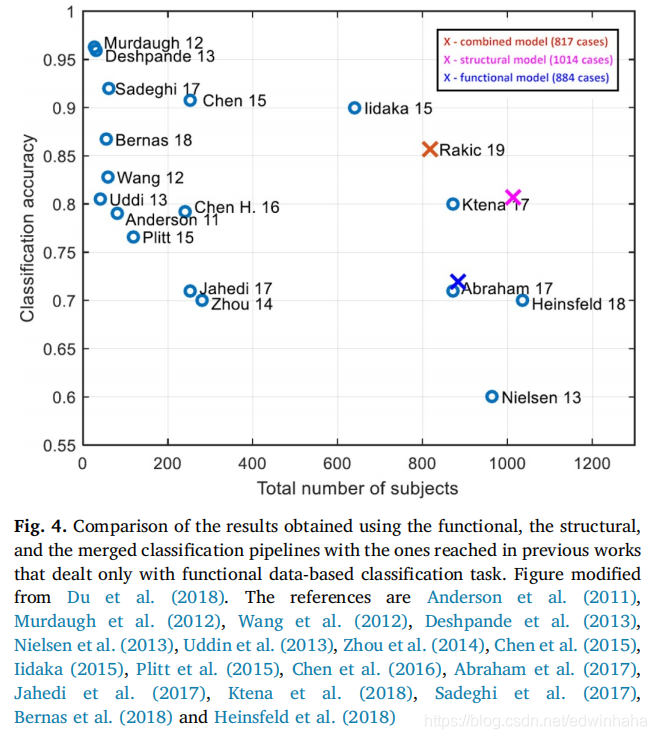
图4显示了与以前的最新技术相比,我们针对每个功能,结构和组合管道的最佳模型的工作方式。由于Kong等人的工作,该图中报道的工作仅基于功能数据。据我们所知,(2019)是唯一处理基于结构数据的分类任务的工具。即使我们获得的准确性不是最高,其他在定量上更好的其他结果也是基于较小的数据集,并且通常包括仅来自单个筛选站点的数据。此外,与我们相比,基于更大的数据集进行的工作得出的准确性明显偏低。但是,在整个ABIDE I数据集上进行测试时,我们模型的行为仍然未知,因为由于各种伪像,整个主题集的一部分被丢弃了。还要注意在图4中结合功能信息和结构信息的优势,相对于单独的管道获得了显着的改进(p <0.05)。
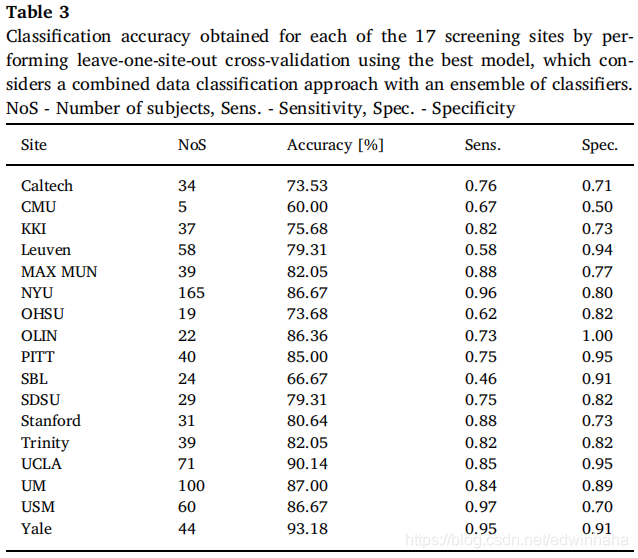
最后,使用获得的最佳模型,我们通过执行“留一留一”的交叉验证对17个成像部位中的每一个所达到的准确性进行了定量分析。表3总结了获得的值,包括达到的灵敏度和特异性值。除CMU中心(精度为60%)外,我们所有其他中心的精度均超过70%。但是,请注意,此中心使用的案例数量很少,这可能会影响分类准确性。这表明该方法能够很好地概括来自不同筛选站点,机器和/或采集协议的看不见的数据。
3.1. Qualitative feature analysis
由于Fisher评分根据特征的区分度对特征进行排名,因此我们想分析基于功能连通性的主要特征(即区域对之间的顶级功能连通性模式)是否与临床研究中的常见发现相对应。表4列出了关于分类任务最感兴趣的连接模式的前15对区域。
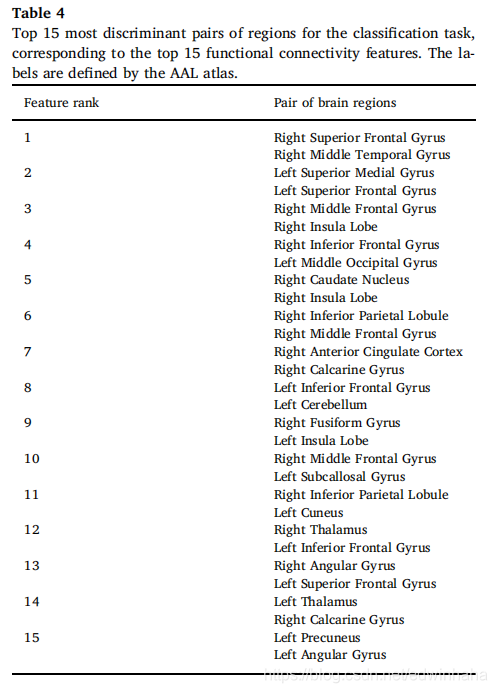
根据表,最有趣的相关性是右上额额回与右中颞期回。另一方面,右中额中回在15个相关中的3个中出现,而左下额中回,左上额中回,右卡尔卡琳回,右下顶叶和右中叶分别出现两个相关。
我们进行了类似的分析,以检查结构数据情况下的主要特征。有一些观察和音符的重复模式。例如,在前15个特征中(即前15个最显着的皮质区域之间的相关性),左横颞沟出现在其中的5个中。这可以表示该特定皮层包裹对于ASD分类的重要性, 因为它是148个可能的包裹之一,并且总共出现在前15个特征中的五个中。列表中的其他重复区域是左顶内沟和横顶沟,出现四次,以及右call下回,出现三个特征。
4. Discussion
在这项工作中,我们旨在通过结合结构性和功能性MRI信息来改善ASD检测。特别是,我们根据Heinsfeld(2018)等人开发的方法实施并合并了两个基准实施 进行功能数据分类和Kong等(2019年)进行结构数据分类,获得的结果与这两部著作中的结果相当。确实,我们的结果与报告的结果之间存在差异,这是可以预料的,因为无法保证用于分类的案例是相同的,训练,验证和测试之间的划分是随机生成的,最后,原始实现的某些细节并未可用。在设计基线实现时,必须注意,我们在这些工作中保留了分析的最佳参数。因此,默认自动编码器和MLP的隐藏层中的节点数(两层分别为1000和600)是Heinsfeld(2018)等人的工作。为结构数据分类管道保留了相同的体系结构。另一方面,Kong(2019)等人证明将输入向量的维数降低到3000是最好的选择(通过从2000到5000的输入向量的维数变化来测试不同的模型),因此,我们在执行功能数据分类策略时应用了相同的约简约束。此外,对功能数据进行了类似测试(通过将输入向量的维数从2000更改为5000,步长为200),结果表明3000个元素确实是最佳选择。
在分别考虑功能和结构管线以及结合方法的情况下,使用Fisher分数作为降维技术可以改善结果。通过从定义的特征集中选择最有区别的特征,可以防止分类器过拟合。因此,它使冗余最小化。关于结构数据分类,降维特别有利。从表2中,我们观察到通过删除多余的特征,分类准确性显着提高(p <0.05)。这可能是由于以下事实:所提出的堆叠自动编码器的浅层架构无法处理如此长的原始特征向量,因此Fisher评分用作减小其尺寸的预处理步骤。就功能数据分类而言,此精度差异要低得多,但是由于选择了图集,该管线还显示出结果的差异。如功能流水线所示,我们同时使用了AAL和CC200地图集来预处理功能数据。当比较获得的结果时,CC200在所有进行的实验中均胜过AAL(p <0.05)。这可能是因为CC200地图集具有200个定义的区域,而AAL仅具有116个区域。我们认为,其他区域揭示了更多的信息和连接模式,而仅使用AAL地图集可能并不存在或与众不同。
如果我们考虑对结构和功能数据进行分类的不同方法,则可以得出结论,就获得的准确性而言,结构管线明显优于功能管线(p <0.05)。这可能是因为在结构预处理管道之后,有更多的案例可供分类。此外,即使特征是在两个管道中独立定义的,它们也来自不同的模态,因此,表明降维技术对结构数据分类的影响大于对功能的影响,这是对特征的另一种证明。定量结果的差异。换句话说,当应用Fisher评分时,在结构管线中分类准确性方面的改进比在功能管线中分类方面的改进更高。关于使用集成分类器的实现,在功能和结构管道中,分类准确性在统计上都有显着提高(p <0.05)。集合中的每个分类器都能够学习输入特征向量的不同表示形式,并且通过融合输出标签,可以在一定程度上减轻错误。在组合分类流水线的情况下,这种错误补偿更为重要,因为输入向量包含来自不同模态的更多信息。关于标签融合,我们尝试了多数投票和平均softmax激活。事实证明,后者的方法略胜于前者。在进行多数表决时,所有标签的权重都相同,而考虑softmax概率时,在决策过程中输出具有较高确定性的概率的分类器将比具有较低确定性的分类器获得更大的权重。但是,这种改善在统计上并不显着。
每个站点进行了定量分析,以测试最佳模型的鲁棒性及其泛化能力。这个想法是要收集经过10倍交叉验证的错误分类的样本,然后确定它们来自哪个筛选站点。然后,针对这17个站点分别计算分类精度。 CMU站点的最低准确度为60%,但是,从该特定站点考虑的案例总数仅为5,远低于其他站点的案例数量。如果有更多可用的案例,则可以说会在单个站点分析中提高该站点的准确性。在其他中心,分类超过75%,我们甚至在其中3个中心获得了90%以上的准确性。
我们进行的另一项分析调查了Fisher评分排名最高的判别特征是否与功能性大脑连通性的常见发现相对应,特别是在与默认模式网络连通性有关的研究中(Greicius等人,2003; Ha等人,2015) 。通过比较DMN区域和对应于排名最高的特征的区域(如表4所示),可以观察到一些相似之处。在两者中都存在上额回和颞叶,但是也存在DMN中不存在的分类网络能够区分的成对区域。原因是功能连接模式在全球范围内观察到,而不是集中在一个特定的大脑网络上。我们的方法量化了所有ROI对的连接性,因此,选择最不同的连接以优化分类准确性。相反,DMN分析仅关注DMN定义范围内的区域的连通性,而忽略其余区域。选择最有区别的特征可以证明在执行组合方法时精度的提高是合理的;我们考虑了两种不同的模式,分别具有两种不同类型的特征,并从这两种特征中选择了最有区别的特征。当我们对基于结构的特征进行类似分析时,我们在前15个特征(即具有不同体积对应关系的成对区域)中提出了一些共同的发现。但是,没有像DMN这样的标准化网络或模型可以为比较和得出结论提供依据。
在功能数据集或结构数据集或在某些情况下,在原始数据集中的1112个样本中,总共有295个样本不符合所需的预处理标准。 这是我们工作的主要限制之一,因为报告的结果不是使用整个ABIDE I数据集获得的。 此外,由于我们使用的子集不一定与其他论文中使用的子集相对应,因此该限制妨碍了与同一主题上其他一些作品的比较。 但是,即使数据来自17个不同的筛查站点并且是使用不同的协议获得的,我们也能获得比其他作品更高的分类结果。 这意味着我们的方法具有良好的泛化能力,并且不依赖于特定协议。
5. Conclusions
在本文中,我们提出了一种自闭症谱系障碍与对照组的分类方法。基于由自动编码器和多层感知器组成的网络的提议方法,在可从ABIDE I数据集中获得的功能和结构数据(以单独和组合方式)上进行了测试。通过定性和定量分析获得的结果,我们展示了多模式方法的重要性。通过在分类算法中包含不同类型的信息,我们能够以统计学上显着的方式改善结果。获得的最高分类精度为85.06%,是多模式策略的结果,该策略包括针对结构和功能数据分类的分类器集合。
当前对ASD的诊断基于两个主要标准:社交沟通和互动中的障碍以及兴趣,行为和活动的限制性,重复性范围(APA,2013)。没有经验的临床医生可能会错误地应用自闭症和相关病症的标准,这是诊断中的主要问题。当前临床实践中的另一个重要问题是诊断的延迟,因为治疗的早期初始化增加了获得有利结果的可能性。考虑到这一点,我们的方法可能会提供有关ASD诊断的更多见解。即使在该领域进行的神经影像学研究得出的结果不一致,仍被认为不足以作为诊断工具,但我们的方法仍可以用作ASD检测的第二意见系统,因为它可能会揭示一些有用的模式和发现,以区分ASD疾病。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









