







文章目录
ABSTRACT
为了基于完整的自闭症脑成像数据交换数据集提高自闭症患者的分类准确性,该研究涉及17个站点的501名自闭症受试者和553名典型对照受试者。首先, 我们基于具有116个大脑区域的自动解剖标记图集,应用静止状态功能磁共振成像数据(rs-fMRI)来计算功能连接性(FC)。其次,我们采用SVM递归特征消除算法(RFE)从原始FC特征中选择了前1000个特征。第三,我们训练了具有两个隐藏层的堆叠式稀疏自动编码器,以从1000个特征中提取出高级潜在特征和复杂特征。最后,将获得的最佳特征输入softmax分类器。实验结果表明,提出的分类算法能够以93.59%(灵敏度92.52%,特异性94.56%)的最新准确性识别自闭症。
1. INTRODUCTION
自闭症谱系障碍(ASD)是一类神经元疾病,与社交沟通,社交互动以及受限和重复行为的核心缺陷有关[1]。 根据疾病控制与预防中心的最新调查,ASD的患病率最近急剧上升,据估计,美国59名儿童中有1名,全世界儿童和成人的比例为1%至1.5%。 令人遗憾的是,ASD的确切病因仍不清楚。 当前,ASD的诊断仅基于行为,并且依赖于基于症状的临床标准,无法将患者与典型对照(TC)区分开。
最近,机器学习(ML)方法已广泛应用于从磁共振成像(MRI)数据中提取生物学信息,对具有ASD和TC的个体进行分类并进一步预测疾病的发展趋势。 先前使用ML的研究在少于200个样本的小型数据集上实现了相对较高的分类准确度,达到65%-96.27%[2] – [11]。相关研究中的分类算法包括支持向量机(SVM),逻辑回归,随机森林,线性判别分析和深度置信网络。在众多ML算法中,基于仅117个样本的小型数据集,SVM是最流行的分类方法,并且在ASD分类中获得了最高的准确性(精度= 96.27%)。这些研究的一个普遍局限性是在功能不足的样本量上聚集了大量特征,从而导致模型过度适合于小型数据集,而无法推广到大型数据样本[12]。
自闭症脑成像数据交换(ABIDE)[13]联盟收集了MRI数据, 该数据由539个ASD和573个匹配的对照组成,分布在17个独立站点上,为大规模研究ASD提供了前所未有的机会。在[14]中, 亚伯拉罕等人。证明了对神经精神状态的站点间分类的可行性,并将其应用于ABIDE数据库。通过从功能定义的大脑区域构建参与者特定的连接体,他们在完整的ABIDE数据集中实现了67%的分类精度。在[15]中,对ABIDE数据集进行了研究,以获取由Craddock 200模板Heinsfeld等人指定的大脑区域的功能连接性。根据整个ABIDE数据集,应用深度学习方法获得70%的分类精度。但是,大型的多站点数据集以不受控制的异质性为代价增加了样本量。异质性意味着对数据样本的某些干扰以及分类准确性的某些损失。
为了提高完整的ABIDE数据集的分类准确性,在本文中,我们提出了一种新颖的ML框架来区分自闭症患者和正常对照。 首先,我们基于具有116个大脑区域的自动解剖标记(AAL)地图集,应用静止状态功能磁共振成像(rs-fMRI)数据来计算功能连接性(FC)。其次,我们采用支持向量机递归特征消除(SVM-RFE)算法从原始FC特征中选择了前1000个特征。第三,我们训练了具有两个隐藏层的堆叠式稀疏自动编码器(SSAE),以从1000个特征中提取出高级的潜在和复杂特征。最后,将获得的最佳特征输入softmax分类器。实验结果表明,提出的分类算法能够以93.59%的最新准确度(敏感性92.52%,特异性94.56%)识别自闭症,这对ASD患者的辅助临床诊断具有启发性的结果。
本文的组织结构如下:第二节介绍了相关工作,第三节介绍了使用的数据集,特征提取和提出的方法; 第四节介绍了这项研究的主要结果,并与最近的类似研究进行了比较,然后在第五节中进行了总结。
2. RELATED WORK
2.1 SVM-RFE
SVM-RFE是一种向后消除方法,从所有功能的全套开始,然后逐个删除最不相关的功能[16] – [19]。 在SVM-RFE的最后一次迭代中删除的排名靠前的功能是最重要的,而在最后一次迭代中删除的靠后的功能是信息最少的功能。 详细地说,SVM-RFE算法可以表示为:
令
X
=
{
x
(
1
)
,
x
(
2
)
,
⋯
,
x
(
N
)
}
X=\{x^{(1)},x^{(2)},\cdots ,x^{(N)}\}
X={x(1),x(2),⋯,x(N)}表示包含
N
N
N个初始特征的数据集,分类标签表示为
Y
=
{
y
(
1
)
,
y
(
2
)
,
⋯
,
y
(
N
)
}
Y=\{y^{(1)},y^{(2)},\cdots,y^{(N)}\}
Y={y(1),y(2),⋯,y(N)},
y
(
i
)
∈
{
−
1
,
1
}
y^{(i)}\in \{-1,1\}
y(i)∈{−1,1},且
i
∈
{
1
,
2
,
⋯
,
N
}
i\in \{1,2,\cdots,N\}
i∈{1,2,⋯,N}
步骤1: 在初始特征集上训练一个SVM:

等式(1)应根据公式(2)最小化。 在等式 (1)和等式(2)中
k
(
x
(
i
)
,
x
(
j
)
)
k(x^{(i)},x^{(j)})
k(x(i),x(j))是核函数,
δ
i
j
\delta_{ij}
δij是Kronecker符号(如果
i
=
j
,
δ
i
j
=
1
i = j,\delta_{ij}= 1
i=j,δij=1,否则为0),
α
=
α
1
,
α
2
,
⋯
,
α
N
\alpha= {\alpha_1,\alpha_2,\cdots,\alpha_N}
α=α1,α2,⋯,αN是待确定的参数,并且
λ
\lambda
λ和
C
C
C是即使在问题是非线性可分离的或条件较差的情况下也可以确保收敛的正常数。
步骤2: 根据以下公式计算权重向量和排名标准:
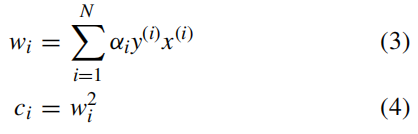
步骤3: 找出排名标准最小的特征并将其消除。
步骤4: 更新特征数据集,并且 N = N − 1 N=N-1 N=N−1
步骤5: 重复步骤1-4,直到功能集为空。
SVM-RFE算法的伪代码可以表示为表1。

值得注意的是,当
F
F
F不为空时,迭代也可以停止。 停止标准可以是用户想要保留的要素的期望数量。 同时,还获得了特征排序。
2.2 AUTO-ENCODER
自动编码器(AE)神经网络是一种无监督的学习框架,该框架应用反向传播,将目标值设置为等于输入值。 对于一组
m
m
m个未标记的训练示例
{
x
(
i
)
∣
x
(
i
)
∈
R
n
+
1
,
i
=
1
,
⋯
,
m
}
\{x^{(i)}| x^{(i)}\in R^{n+1},i=1,\cdots,m\}
{x(i)∣x(i)∈Rn+1,i=1,⋯,m},与偏置输入相关的
x
0
(
i
)
=
1
x^{(i)}_0 = 1
x0(i)=1,AE尝试学习一个近似函数
h
W
,
b
(
x
)
≈
x
h_{W,b}(x)\approx x
hW,b(x)≈x,以使输出接近输入,如图1所示。

稀疏AE(SAE)的总体成本函数定义为:

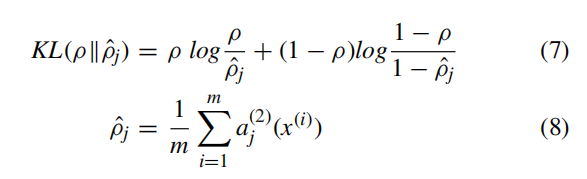
等式中(5)的参数
β
\beta
β控制稀疏惩罚项的权重; 等式(6)中的第一项是平均平方误差项; 等式(6)中的第二项是一个正则化项,它倾向于减小权重的大小并有助于防止过度拟合; 参数
λ
\lambda
λ控制两个项的相对重要性;
m
m
m是训练样本数;
n
l
n_l
nl是网络中的层数;
s
l
s_l
sl是第
l
l
l层的节点数;
ρ
^
j
\hat{\rho}_j
ρ^j表示隐藏单元
j
j
j的平均激活;
ρ
\rho
ρ是稀疏参数。 目标是通过使用迭代优化算法,例如有限内存的Broyden Fletcher-Goldfarb-Shanno(L-BFGS)[20],[21],最小化方程式(5)。
2.3 SOFTMAX REGRESSION
令
{
(
x
(
1
)
,
y
(
1
)
)
,
(
x
(
2
)
,
y
(
2
)
)
,
⋯
,
(
x
(
m
)
,
y
(
m
)
)
,
}
\{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),\cdots, (x^{(m)},y^{(m)}),\}
{(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m)),}是一组
m
m
m个标记的训练示例,并且
x
(
i
)
∈
R
n
x^{(i)}\in R^n
x(i)∈Rn,
y
(
i
)
∈
{
1
,
2
,
⋯
,
k
}
y^{(i)}\in \{1,2,\cdots,k\}
y(i)∈{1,2,⋯,k}。 我们要估计类别标签采用
k
k
k个不同可能值中的每一个的概率。 softmax的假设
h
θ
(
x
)
h_{\theta}(x)
hθ(x)的形式为:

其中,
θ
=
(
θ
1
T
,
θ
2
T
,
⋯
,
θ
k
T
)
T
\theta=(\theta^T_1,\theta^T_2,\cdots,\theta^T_k)^T
θ=(θ1T,θ2T,⋯,θkT)T表示模型的参数集,通常表示为一个
k
×
(
n
+
1
)
k\times(n+1)
k×(n+1)矩阵,是通过将
θ
j
\theta_j
θj叠加而得到的,
j
=
1
,
2
,
⋯
,
k
j=1,2,\cdots,k
j=1,2,⋯,k ,且
θ
j
∈
R
n
+
1
\theta_j\in R^{n+1}
θj∈Rn+1成行。
代价函数为:
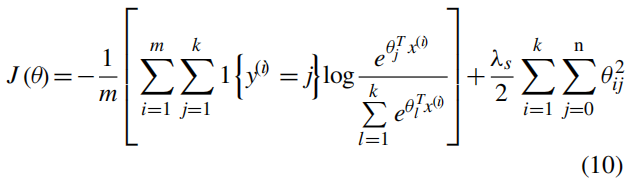
其中
1
{
⋅
}
1 \{·\}
1{⋅}是示性函数,权重衰减项
λ
s
2
∑
i
=
1
k
∑
j
=
0
n
θ
i
j
2
\frac{\lambda_s}{2}\sum\limits_{i=1}^k\sum\limits_{j=0}^n \theta^2_{ij}
2λsi=1∑kj=0∑nθij2用于惩罚较大的参数值并使
J
(
θ
)
J(\theta)
J(θ)严格凸。
3. MATERIALS AND METHODS
3.1 PARTICIPANTS AND DATA PREPROCESSING
原始的fMRI和人口统计学数据是从ABIDE收集的,可以无限制地用于非商业研究目的。这些研究所的扫描参数和受试者的组成列于表2。预处理Connectomes项目(PCP)开始共享ABIDE的预处理神经影像数据[22]。研究中的所有数据均由PCP中的DPARSF [23]管道进行了预处理。具体来说,在删除第一个4卷之后,将进行切片时间校正,重新调整头部运动并将强度标准化。进行有害信号去除以清除由于生理过程(心跳和呼吸),头部运动和低频扫描仪漂移而引起的混杂变化。有害变量回归后,应用带通滤波(0.01 – 0.1 Hz)。通过将功能转换为解剖转换和将解剖转换为模板,可以为每个数据集计算从原始空间到模板的转换(MNI152)空间。根据文献[24],头部运动对自闭症的分类准确性没有显着影响。因此,我们仅排除结构图像在预处理后未被完全覆盖的对象。因此,研究涉及17个站点的501 ASD和553 TC。

3.2 CONNECTIVITY MEASURES AND FEATURE MATRICES
AAL图集[25]将大脑分为116个区域,是用于创建内在连通性的标准大脑模板。 从116个区域中的每个区域中提取时程,并在每个区域中进行平均。 这些平均时间过程之间的 皮尔逊相关系数
(
R
(
i
,
j
)
)
(R(i,j))
(R(i,j)) 根据以下公式计算:
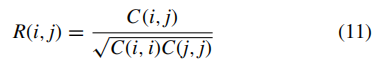
其中,
C
(
i
,
j
)
C(i,j)
C(i,j)表示时程
i
i
i和
j
j
j之间的相关系数。
为了使其在统计上更具重要性,根据以下条件实施了Fisher的z变换:
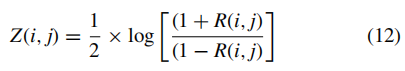
因此,Fisher的z变换相关系数用一个116×116矩阵(13,456个特征)表示,该矩阵关于对角线对称。 删除了矩阵的上三角和主对角线内的值。 因此,矩阵下三角中剩余的有效像元数为6670。我们将剩余三角展平(即将其折叠成一维向量)以检索特征向量,以将其用于分类。
3.3 FEATURE SELECTION BASED ON SVM-RFE
上述FC产生了6670个特征,而样本量为1054。因此,在“高尺寸,小样本”一词中进行了总结。 很难了解最有区别的功能,即在小样本情况下,将6670功能直接输入SAE。 SVM-RFE可以预先消除一些毫无意义的功能。 因此,我们使用SVM-RFE在6670个初始特征中选择了前1000个,以使SAE更好地学习高级特征。 如图2所示,SVM-RFE在6670 FC集中选择了前1000个功能。
3.4 FEATURE SELF-TAUGHT LEARNING AND CLASSIFICATION
为了提取FC的高级潜在特征和复杂特征,我们构建了一个由两层SAE组成的特征自学学习网络,其中第一层的输出连接到第二层的输入。 令
W
(
k
,
1
)
,
W
(
k
,
2
)
,
b
(
k
,
1
)
,
b
(
k
,
2
)
W^{(k,1)},W^{(k,2)},b^{(k,1)},b^{(k,2)}
W(k,1),W(k,2),b(k,1),b(k,2)分别表示第
k
k
k个SAE的权重参数和偏差。 获得SAE良好参数的一种好方法是使用贪婪的逐层训练[26]。 为此,首先在原始输入上训练第一层以学习参数
W
(
1
,
1
)
,
W
(
1
,
2
)
,
b
(
1
,
1
)
W^{(1,1)},W^{(1,2)},b^{(1,1)}
W(1,1),W(1,2),b(1,1)和
b
(
1
,
2
)
b^{(1,2)}
b(1,2)。 第一层将原始输入转换为包含隐藏单元激活的向量。 然后在此向量上训练第二层,以学习参数
W
(
2
,
1
)
,
W
(
2
,
2
)
,
b
(
2
,
1
)
W^{(2,1)},W^{(2,2)},b^{(2,1)}
W(2,1),W(2,2),b(2,1)和
b
(
2
,
2
)
b^{(2,2)}
b(2,2)。 通过使用每个层的输出作为后续层的输入,针对后续层重复此训练过程。由两个或多个SAE以此方式构造的网络称为堆叠式稀疏自动编码器(SSAE)。
如图3所示,基于SSAE的特征自学学习系统被配置为1000-200-100。 SVM-RFE选择的前1000个功能被馈入具有200个隐藏单元的第一个SAE中,其中学习了200个高级功能。 第二次SAE依次学习了100个复杂功能。 从两个连续的SAE中提取的自学式学习功能分别如图4和图5所示。

SSAE的输出(用作特征)被馈入由logistic回归概括的softmax分类器中[27]。 总体模式识别方案如图6所示。

对于SSAE,稀疏参数
ρ
\rho
ρ,权重衰减参数
λ
\lambda
λ,稀疏惩罚项
β
\beta
β的权重和迭代次数分别设置为
0.08
、
1
e
−
4
、
2
0.08、1e-4、2
0.08、1e−4、2和
200
200
200。 对于softmax分类器,权重衰减参数
λ
s
\lambda_s
λs为
1
e
−
4
1e-4
1e−4,迭代次数为100。此外,我们使用微调来改善预训练后SSAE的性能。
4. RESULTS AND DISCUSSION
该研究是在完整的ABIDE数据集上进行的。 将1054个样本(501个ASD,553 TC)的数据集与k个大小相等的子集随机分割,并馈入所提议的模式识别网络。 通过以下性能指标评估分类质量:
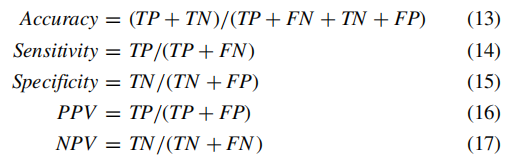
其中,正阳性(TP),假阴性(FN),真阴性(TN)和假阳性(FP)分别表示正确分类的ASD数量,预计为TC的ASD数量,TC的数量 正确分类,并预测TC数量为ASD。 表3列出了ASD和TC的识别结果,它们具有不同的交叉交叉验证(CV)。 即使k不同,诸如准确性之类的各种指标的值也非常稳定。 平均分类准确率达到93.59%。

敏感性衡量正确识别的ASD的比例,特异性衡量正确识别的TC的比例。为了评估我们的模型在实际临床世界中的行为的现实前景,我们分别计算了PPV和NPV。所提出的方法获得了相对较高的PPV为94.01%和NPV为93.41%。根据文献,这是迄今为止实现的最佳分类结果。
此外,如果将SSAE配置为6670-200-100或6670-3072-1024-512-100,也就是说,无需通过SVM-RFE选择就将原始FC功能输入到SSAE中,分类精度仅为63.37%,而分别为64.01%。尽管增加了SSAE的隐藏层数量,但在“高尺寸小样本”情况下,SSAE难以提取最具区分性的特征。此外,如果将SVM-RFE选择的1000或100 FC功能直接输入到没有SSAE的soft max分类器中,分类准确率分别仅为67.25%和63.12%.
由于样本相对于FC特征的大小较小,因此即使仅来自整个ABIDE数据集,其识别结果也不能令人满意,仅依赖于深度学习。 此外,仅依靠SVM-RFE而没有SSAE的分类准确性也不令人满意。 通过结合使用SVM-RFE和SSAE,很好地解决了“高尺寸,小样本”的问题。 使用SVM-RFE预先消除一些毫无意义的功能可以减少SSAE的噪音。 SSAE可以根据SVM-RFE选择的功能来学习一些高级潜在功能。 在较高的抽象级别上,这些转换创建了用于分类任务的表示形式。
与最近的类似研究相比,基于相同的大型多站点数据集,该方法的性能优于文献[14]和[15]。 表4显示了通过不同方法进行的分类精度比较。
另外,图7示出了所提出的方法,文献14的方法和文献15的方法的接收机工作特性(ROC)曲线,从中可以看出,对于所有分类器,真实的阳性率随着假阳性率的增加而增加,而所提出的方法获得了曲线下的最大面积(AUC)。

所提出的方法完全由数据驱动,无需任何先验知识。这项研究的最初FC功能来自整个大脑区域,而不是诸如默认模式网络之类的局部区域。根据现有文献[28]-[33],某些选定的区域与ASD并没有真正的联系,但是这些区域在自闭症中可能发挥了一些未被认识的作用。数据驱动的方法可以很好地解决由大型多站点数据集中的不同设备和人口统计学产生的不受控制的异质性的原因可能是这样。因此,在无法识别的区域进行更多的传送对于进一步发展ASD诊断至关重要。
5. CONCLUSION
在这项研究中,提出了一种结合SVM-RFE的深度学习方法,以基于整个ABIDE数据集提高ASD的分类准确性。所提出的方法使用SVM-RFE预先消除了一些无意义的特征,以使SSAE在“高尺寸,小样本”情况下能够很好地提取出复杂的特征。这项研究共涉及501名自闭症受试者和553名在17个部位进行典型对照的受试者。最新的平均准确度为93.59%,ROC和AUC均优于最近对最大自闭症数据集的类似研究。实验结果表明,根据现有文献,尽管所提出的某些ROI与ASD并没有真正的联系,但它们可能在自闭症中起了一些无法识别的作用。它确实表明,数据驱动的方法可以很好地解决由大型多站点数据集中的不同设备和人口统计学产生的不受控制的异质性。这是对ASD患者进行辅助临床诊断的令人鼓舞的结果。
需要进一步研究以将大脑成像的多个指标(例如灰质体积和皮质厚度)与FC结合起来,这可能会导致更好的识别结果。















 6670
6670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









