







不是很擅长讲解知识,
但这些分析记录也希望能帮助到大家。
若有错误之处,希望大家指出。
新建线程的方式
一、常用的新建线程的三种方式
(1)直接new Thread()
代码:
/**直接new thread**/
@Test
public void newThread01() {
//直接new接口然后重写run方法
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("1111");
}
}).start();
//lambda表达式 实际上还是runnable接口
new Thread(() -> {
System.out.println("2222");
}).start();
}
(2)新建一个类,实现Runnable接口,重写run方法
代码
/**
* 通过继承runnable接口
* 重写run方法
* 再start调用
**/
public class ThreadRunnable implements Runnable {
@Override
public void run() {
System.out.println("Thread-Runnable");
}
}
然后要使用时只需要new和start
/**
* 使类实现Runnable接口重写run
* 只需要实例化对象,直接调用start
**/
@Test
public void newRunnableClass() {
ThreadRunnable threadRunnable = new ThreadRunnable();
Thread thread01 = new Thread(threadRunnable, "thread-runnable");
thread01.start();
System.out.println("name:" + thread01.getName());
}
(3)新建一个类,继承Thread类,覆盖run方法
public class ThreadExtends extends Thread{
public void run() {
System.out.println(this.getName() + ":Thread extends Threads!");
}
}
分析
其实以上三者本质上都是重写 Runnable 接口的run方法
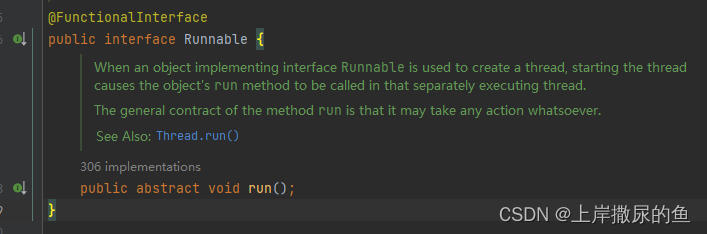
而Runnable作为一个接口,也仅有一个 run方法而已,所谓实现Runnable方式,也还是要new一个Thread传入我们Runnable接口的实现类。
而Thread类内部存在一个target:
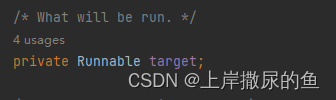
不管是new Thread的方式:

还是继承Thread的方式:
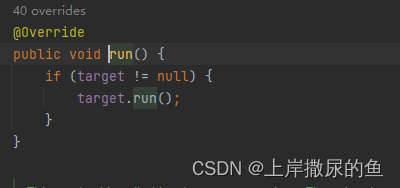
都是重写 Runnable 接口的run方法。
1、需要继承其它的某个父类去调用方法
可以使用新建一个类实现 Runnable 接口的方式,这样不会因为单继承限制了。
(因为单继承,父类只能有一个)。
2、需要对新建的线程有更多的操作
可以使用继承Therad,毕竟Therad提供了许多针对线程的方法。
二、使用线程池创建和管理线程
像上面的三种方式,随时随地new一个看似方便。
但实际上我们在业务中可能会有并发,建立许多线程。
为了方便管理线程,就需要用到线程池
线程池的作用
如上所述,就是为了方便我们管理线程。
我们可以自己定义线程数量的上限、干掉线程……
线程池的参数及含义
ThreadPoolExecutor是最基础的线程池创建方式,也是大部分特殊线程池的基础实现。
最底层有参构造:
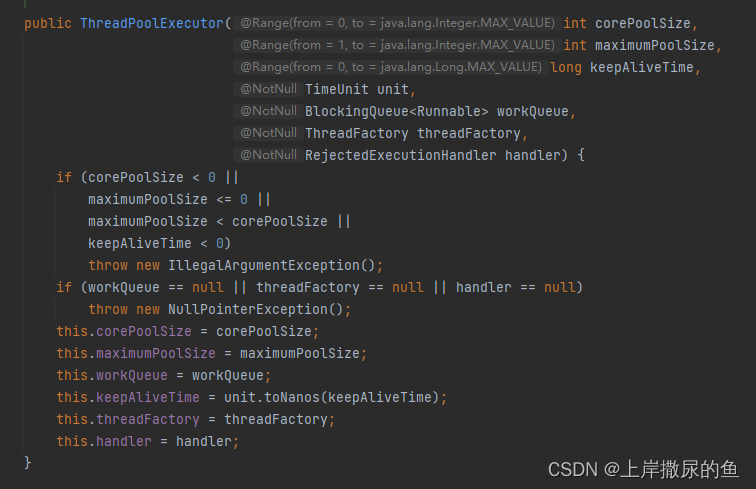
有些参数在其它创建线程池时不用给
是因为作为子类内部早就有自己的一套处理了,但还是要知道它们的含义。
corePoolSize
核心线程数
即正式在职员工数量,创建后,空闲时不会被销毁。
最大值 – Integer.MAX_VALUE
maximumPoolSize
总最大线程数 = 核心线程数 + 临时线程数
当核心线程创建数量已达指定的最大值,且任务队列已满。
线程池会考虑创建临时线程去执行任务。
最大值 – Integer.MAX_VALUE
keepAliveTime
临时线程在空闲多久后会被干掉。
最大值 – Long.MAX_VALUE
unit
TimeUnit类型,为keepAliveTime的时间单位。
threadFactory
是一个线程工厂
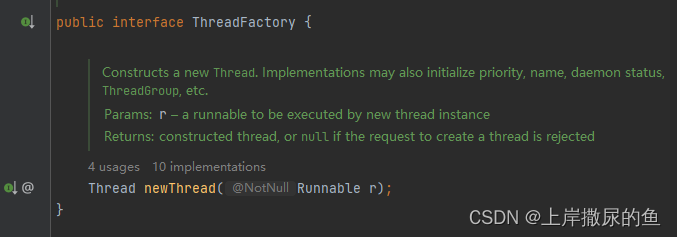
工厂模式,很普遍。
同时,在其父类Executor内部也定义了默认的线程工厂。
就一个方法,如何“生产”一个线程。
handler (RejectedExecutionHandler)
规定了当线程数量已达规定上限(maximumPoolSize)后,线程池的处理策略。
提供了四种已写好的拒绝策略供选择(有关四种拒绝策略的解释在下方)。
默认为拒绝策略,并抛出异常。
线程池执行流程
任务提交给线程池后以下流程:
- 存在空闲核心线程,由空闲核心线程执行。
- 无空闲核心线程,若核心线程数未达规定最大数量,创建一个新的核心线程执行。
- 无空闲核心线程,若核心线程数已达规定最大数量,添加到阻塞队列中等待执行。
- 当阻塞队列满时 或队列为null,创建临时线程(非核心线程)去执行 。
- 若非核心线程数已达规定的最大值,拒绝这个任务。
(不管是创建核心线程还是非核心线程,在创建之前,都会先考虑线程池中是否存在对应的空闲线程,有的话就交由空闲线程去执行,没有才会去创建。)
临时线程 / 非核心线程是核心线程数达规定上限,且阻塞队列已满或为null时,才会去创建执行任务!
ThreadPoolExecutor – 线程池
创建代码:
public void createThreadPool() {
//ThreadPoolExecutor(int corePoolSize, 核心线程数,创建后不会被销毁
// int maximumPoolSize, 线程池最大线程数,核心线程数+临时线程数
// long keepAliveTime,临时线程空闲时间,空闲多久后销毁
// TimeUnit unit,空闲时间的单位
// BlockingQueue<Runnable> workQueue 阻塞队列)
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 2, 60, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(1), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("我拒绝了创建线程!");
}
});
}
SingleThreadExecutor() – 单线程池
代码:
/**
* 仅创建一个线程去执行任务
* **/
@Test
public void singleThreadPool() {
ExecutorService executors = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
executors.execute(() -> {
System.out.println(Thread.currentThread().getName());
});
}
}
实现方式为ThreadPoolExecutor,看看创建方式:
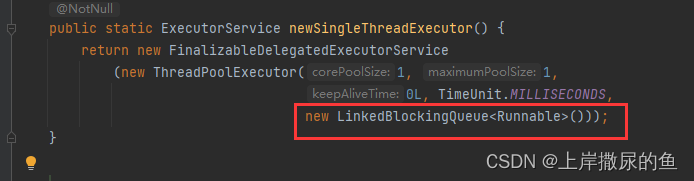
与ThreadPoolExecutor默认的队列不同,单线程池指定的阻塞队列是属于链表性质的,再结合只有一个核心线程执行任务。
可以知道,就算有很多个任务,它们全都得根据提交的顺序,一个个地顺序去执行。
单线程池的特点如下:
- 有且仅会有一个核心线程,不会创建临时线程
- 根据任务提交顺序,一个个地执行
- 指定阻塞任务队列
LinkedBlockingQueue - 默认线程工厂
- 默认拒绝策略
FixedThreadPool – 固定大小的线程池
创建方式依然很简单,使用ExecutorService 就行。
代码:
/**
* 创建一个固定大小的 线程池
**/
@Test
public void createFixedThreadPool() {
ExecutorService executors = Executors.newFixedThreadPool(2);
//submit 提交一个线程任务,默认是Runable
executors.submit(() -> {
System.out.println("Submitted a thread!");
});
//executor 执行一个任务
executors.execute(() -> {
System.out.println("Execute a thread!");
});
}
方法如下图:
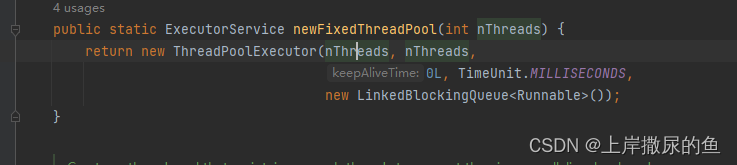
可见,**FixedThreadPool **特点如下:
- 创建
n个核心线程数,不允许创建临时线程 - 存在阻塞任务队列
LinkedBlockingQueue - 默认线程工厂
- 默认拒绝策略
CachedThreadPool – 带缓存的线程池
代码:
/**
* 创建带缓存的线程池
**/
@Test
public void createCachedThreadPool() {
ExecutorService executor = Executors.newCachedThreadPool();
//通过循环执行结果 观察是否调用了空闲的线程
for (int i = 0; i < 100; i++) {
executor.submit(() -> {
System.out.println("This thread is: " + Thread.currentThread().getName());
});
}
}
看看创建方法:
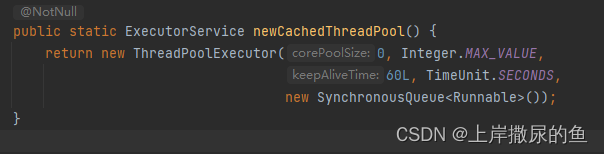
特点:
- 创建**CachedThreadPool **时不用指定参数,它不会创建核心线程,全都是临时线程,用完就销毁
- **CachedThreadPool **的运行创建最大数量(Integer.MAX_VALUE)的临时线程,且它们在空闲60s后才会被销毁
- **CachedThreadPool **的任务队列是
SynchronousQueue,它比较特殊,不存放任务,所以进来多少任务,有空闲线程让空闲线程去执行,没有就去创建临时线程执行。 - 优点:短时间内的大量任务可以及时得到执行。
- 缺点:这种大量线程的创建会占有大量资源,很容易OOM。
WorkStealingPool – 默认根据CPU核心数创建的线程池
Stealing这个单词吧,要是直接翻译,盗窃?工作盗窃池,听上去挺离谱的……
甭管叫什么吧,它的特点就是创建这个线程池的时候:
- 没指定线程数,默认以CPU核心数创建。
- 指定了,就按指定线程数创建。
源码中的构造函数:
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
WorkStealingPool 底层不是 ThreadPool 而是 ForkJoinPool
其中,Runtime.getRuntime().availableProcessors()这个的作用,就是返回CPU核心数。
而且ForkJoinPool有属于它自己的线程工厂,可见特殊性。
(具体的……不懂……
ForkJoinPool有时间得单独记录)。
如果问到这个线程池特点,除了上面的创建时特点,还有:
- 适合比较耗时间的且数量不大的任务,
- 底层用的ForkJoinPool 来实现的
- ForkJoinPool的优势在于,充分利用多核心cpu,把一个任务拆分成多个“小任务”分发到不同的cpu核心上执行,执行完后再把结果收集到一起返回。
ScheduledExecutorService
定时任务线程池的创建方式与其它不一样,需由ScheduledExecutorService创建使用。
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
//...
}
定时任务的服务实际上是继承自ThreadPoolExecutor,只是做了属于它自己的特点,拿一个构造函数来看:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
这个super自然指的就是ThreadPoolExecutor,实际上还是ThreadPoolExecutor实现的。
造就定时任务的特殊功能,归功于DelayedWorkQueue这个特殊的队列。
具体的……另外单开一章写队列吧……
这里只知道它是定时取任务执行就是了。
ScheduledExecutorService提供了定时任务和延时定时任务两种
(1)执行一次的延时定时任务
等待一定时间后执行一次这个任务,创建时先指定
代码:
/**
* 创建一个 ScheduledThreadPool
* 且仅执行一次延迟任务
*
* schedule(Runnable command,long delay, TimeUnit unit);
* delay 表示延迟多久时间开始执行第一次, unit为时间单位
* **/
@Test
public void executorsOnly() throws Exception{
//ScheduledThreadPool 执行延迟任务 有其自己的executors服务
//实际的方法还是得Executors来
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(1);
System.out.println("ScheduledThreadPool created:" + new Date());
//lambda默认实现runnable接口
executorService.schedule(() -> {
System.out.println("ScheduledThreadPool executing!" + new Date());
},3, TimeUnit.SECONDS);
Thread.sleep(5000);//主线程需要等待子线程完成任务
}
看一下内部方法:

- 指定的数值,为核心线程数上限
- 允许创建临时线程,且任务执行完毕就销毁,没有什么特点。
- 任务队列为
DelayedWorkQueue,为一种延迟的任务队列,是定时任务的重点,这里不细说。
(2)创建一个定时任务
创建一个固定周期的任务,从当前时间开始计算,每隔一定时间,就执行一次。
代码:
/**
* 执行定时任务
* scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);
* initialDelay 多久后执行第一次任务
* period 第一次任务开始,每隔多久执行一次
* unit 时间单位
* scheduleAtFixedRate 为固定周期的任务
* **/
@Test
public void fixedRate() throws Exception{
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);
System.out.println("ScheduledThreadPool created:" + LocalDateTime.now());
executorService.scheduleAtFixedRate(() -> {
System.out.println("ScheduledThreadPool executing!" + LocalDateTime.now());
try {
//让实际执行时间的延迟 大于 规定的延迟时间
Thread.sleep(3000);
}catch (InterruptedException e) {
e.printStackTrace();
}
},3, 2,TimeUnit.SECONDS);
while (true) {//保证主线程存活
}
}
定时任务和延时任务的使用场景,需要分析一下:
- 如果每次任务的执行时间必须是指定的时间点(例如,0点0分,1点0分……),我们就需要用 延时定时任务。
再说仔细点,我们需要一个任务每次整点(即几点零分)的时候执行,那么在这个任务提交之前,先判断当前时间距离整点多久,我们需要等待到整点的时候再去执行这个任务。 - 如果说我们需要任务
立即执行,且以当前时间为准立马开始计算周期,那么久使用定时任务。
这里需要注意的是,不管是定时任务 还是 延时定时任务 都是以 上一次任务开始时间 开始计算周期时间的。
再举个例子:
现在时间为: 06:01:00 ,开始执行定时任务,周期为一个小时,那么往后的执行情况为:
第一次: 06:01:00
第二次: 07:01:00
第三次: 07:01:00
第四次: 07:01:00
……
以此类推,所以需要清楚所谓定时和延时定时的特点。
其实我看
线程池的拒绝策略
注:以下贴出的源码已删掉注释,会作出解释。想看英文注释去翻翻源码。
ThreadPoolExecutor对于拒绝任务提供了四种策略选择,他们全都是由ThreadPoolExecutor内部定义的静态公共类,可以直接使用。
AbortPolicy
abort – 中止
翻译:中止策略
特点:拒绝任务,丢弃任务,抛异常。
作为默认的拒绝策略,它会直接拒绝掉无法处理的任务,并且抛出异常打印信息。
在源码中是这样的:
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
没有什么特别的,能瞄一瞄的也就是这个异常属于运行时异常,也就是RuntimeException
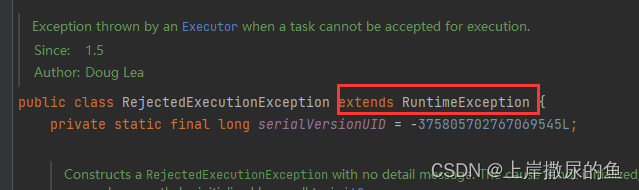
(思维发散延伸一下:运行时异常有什么特点?异常分为几类?)
DiscardPolicy
discard – 拒绝
翻译:拒绝策略
特点:拒绝任务,丢弃任务,但不抛异常不打印信息。
源码中是这样的:
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
可以看到,重写的方法里啥也没有,什么都不做,这货啥也没做呀!
这个任务就这么不声不响地被抛弃了,啥信息也没有。
CallerRunsPolicy
Caller – 呼叫者,Runs – 运行
翻译:呼叫者运行……(咳咳,中式翻译不可取)
特点:本身拒绝任务,但不会丢弃,在主线程没有关闭的情况下,给主线程去做。
源码:
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
DiscardOldestPolicy
discard-- 拒绝,oldest – 最老的,最旧的
翻译:拒绝最老的策略
特点:把队列位于最前面的任务给丢掉,把现在这个任务放进去。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
可以看到,因为是队列嘛,e.getQueue().poll();自然取出最前面的,最前面的没了,队列就能空出一个位置给现在这个任务。
为什么是e.execute(r);而不是选择直接add放进队列?
万一啊,我是说万一啊,偏偏这个时候有空闲的线程了呢?
自定义拒绝策略
对于自定义拒绝策略,在上边儿新建ThreadPoolExecutor已经举例代码了。
关于各线程池中队列的特殊性,会单独再看看总结一下,哦,还有ForkJoinPool,其实还有Executors、ScheduledExecutorService、ExecutorService它们的关系等等。
其实帖子很多,都大差不差,但自己总结叙述一遍,对自己也有帮助。
















 2664
2664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











