







文章目录
关于本篇
这是一篇学习记录,不是很会描述,如果觉得我整理的不好可以参考其它大佬博客。
(学习自 B站尚硅谷Elasticsearch )
他们官方公众号能直接获取网盘资料的,有需要自己找。
感谢尚硅谷,白嫖了很多课程。
ES 介绍
ES是什么?明显特点?
是一个
分布式、可拓展、面向文档、RESTful 风格的搜索和数据分析引擎
ES的优势,就是根据关键字更快地定位到文档。
虽然官方给出的介绍是搜索和数据分析引擎,但实际上已经成为一种另类的数据库,可以用来存储和处理日志等文件。
为什么要用ES?
ES能够在文档搜索、关键字分析具有优势,肯定是有着一般数据库没有的设计。
文档类型的数据之间没有紧密的关联关系,无法相互关联提高搜索效率,对于想根据关键字定位文档需求,就必须要全文检索。
全文检索和一般的在数据库中检索数据不一样,不读取文档内容是没法知道里面是否包含关键字的。
但是如果在检索之前,我们先将文档内容进行读取和拆分(保留原文档),也就是分词,再将分出来的词、也就是关键词建立一个“目录”。
这样就能根据关键字(词),迅速找到包含它们的所有文档是哪一些,防止了检索所有文档内容的操作。
拆分过程其实也挺繁琐,但实际上,以一次针对文档的读取拆分处理操作,为今后的大量、频繁的检索功能提供了超高的效率,是很值的。
Elasticsearch使用Lucene
[必看!] – 关于版本选择
新版的elasticsearch对jdk版本要求蛮高,官方的版本对应:
https://www.elastic.co/cn/support/matrix#matrix_jvm
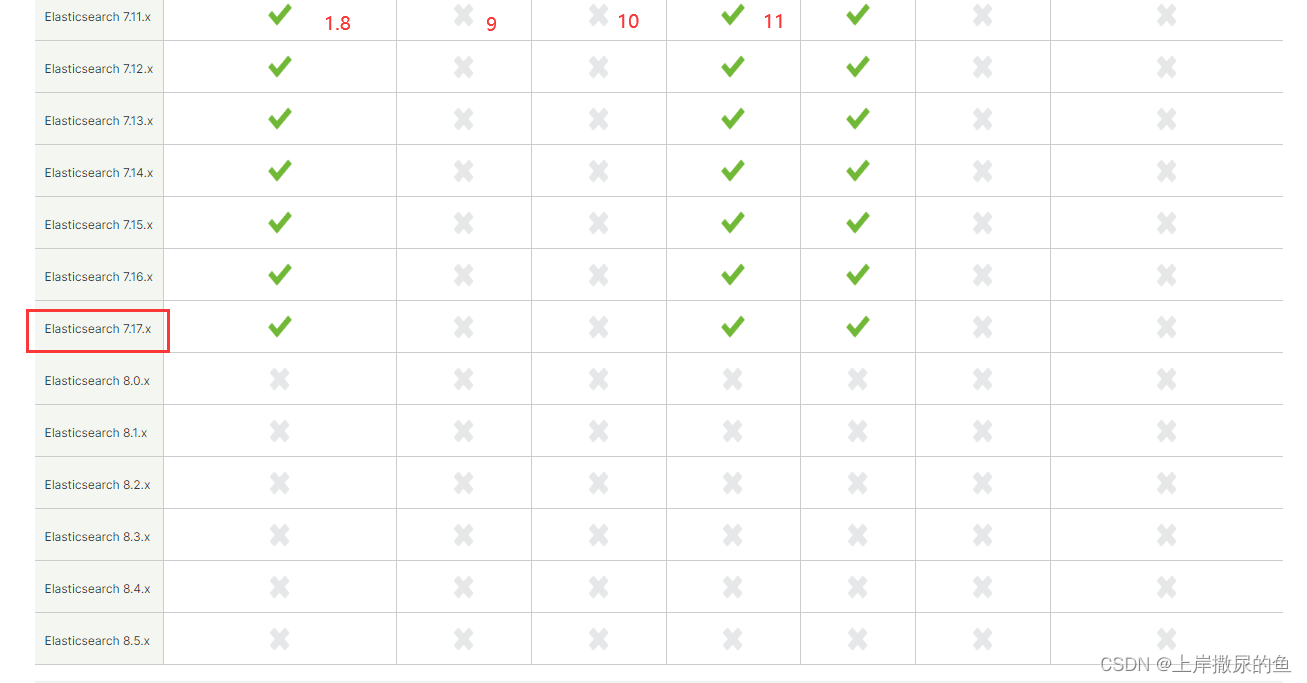
jdk1.8到jdk11最多都只能使用7.17.0
千万不要莽着就上最新版了,在文后半部分,我就是有这个错误的出现,才降版本的。
当然安装方式没什么区别。
Elasticsearch 在Linux下的单机部署
ES 支持Windows和Linux两种环境,并且都支持单机和集群模式的部署。
解压
tar -zxvf xxx
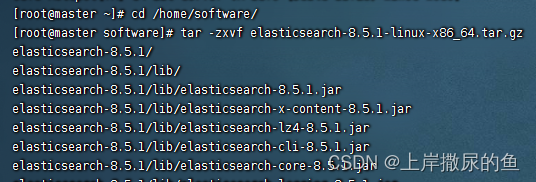
解压后的目录结构如下:
创建es用户
创建es用户,将密码设为es
useradd es
passwd es
给es用户加上文件夹操作权限:
chown -R es:es /home/software/elasticsearch-8.5.1 #文件夹所有者
如果密码错误或者创建错误,删除后重新创建:
userdel -r es
修改配置
config文件夹下的elasticsearch.yml
切换到config目录下:
根据注释里面的提示添加以下内容:
# 加入配置
cluster.name: elasticsearch #集群名称
node.name: node-master #当前节点的名称
network.host: 0.0.0.0 #单节点配置ip
http.port: 9200 #单节点配置端口号
cluster.initial_master_nodes: ["node-master"] #初始的主节点名称
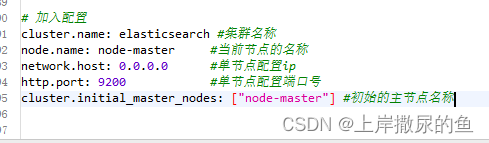
修改/etc/security/limits.conf
vim /etc/security/limits.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
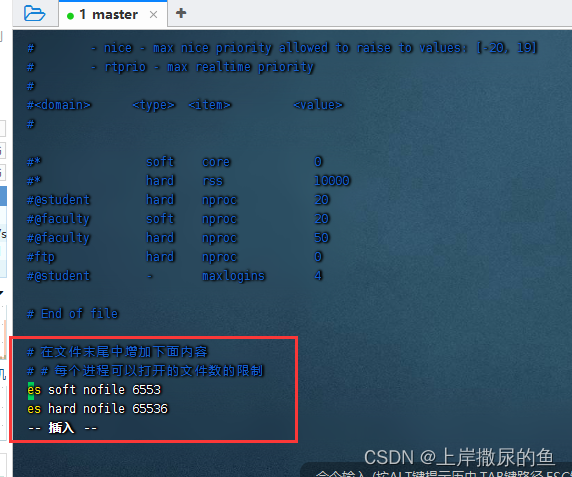
修改/etc/security/limits.d/20-nproc.conf
vim /etc/security/limits.d/20-nproc.conf
# 在文件末尾中增加下面内容
# 每个进程可以打开的文件数的限制
es soft nofile 65536
es hard nofile 65536
# 操作系统级别对每个用户创建的进程数的限制
* hard nproc 4096
# 注:* 表示 Linux 所有用户名称
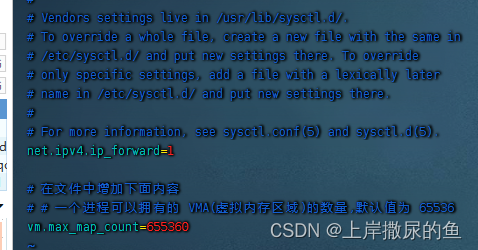
修改/etc/sysctl.conf
vim /etc/sysctl.conf
# 在文件中增加下面内容
# 一个进程可以拥有的 VMA(虚拟内存区域)的数量,默认值为 65536
vm.max_map_count=655360
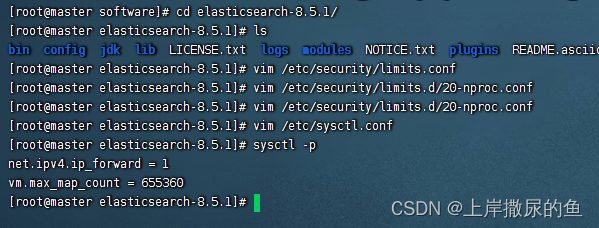
重新加载
sysctl -p
启动ES
切换到es文件夹
cd /home/software/elasticsearch-8.5.1
命令启动
bin/elasticsearch
root用户启动报错
如下:
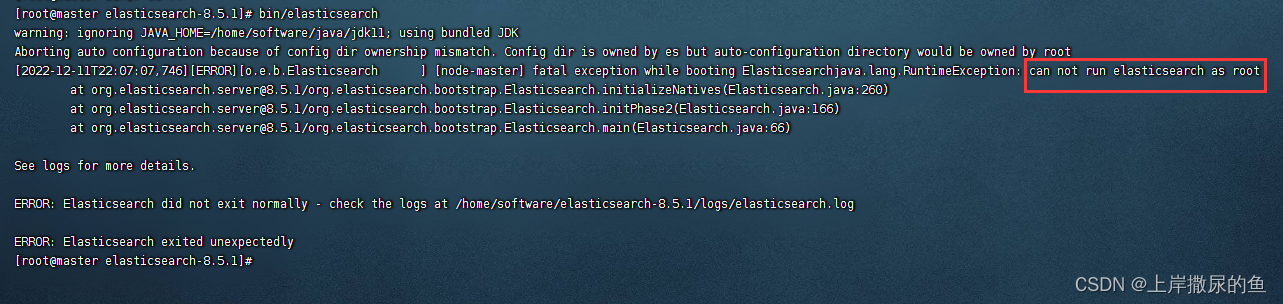
切换到ES用户
su es
bin/elasticsearch
后台启动
#后台启动
bin/elasticsearch -d
访问拒绝报错 – JDK版本不对
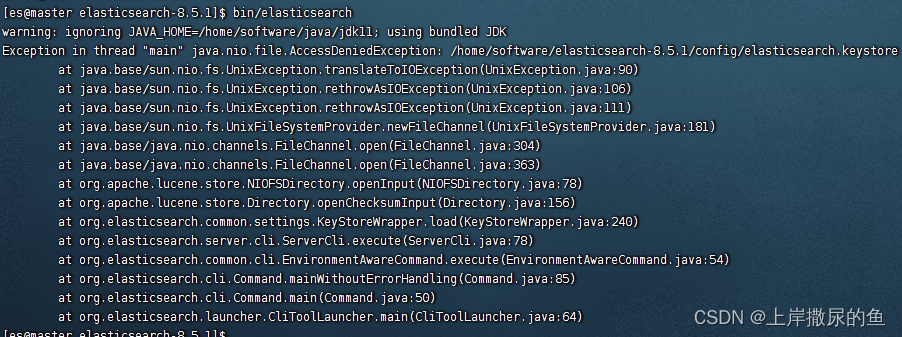
说明es用户对这文件访问受到限制,切换到root用户下,再次执行赋予权限的命令:
chown -R es:es /home/software/elasticsearch-8.5.1
关于提示JDK文件找不到的报错
在完成上述步骤后,启动又报错了:
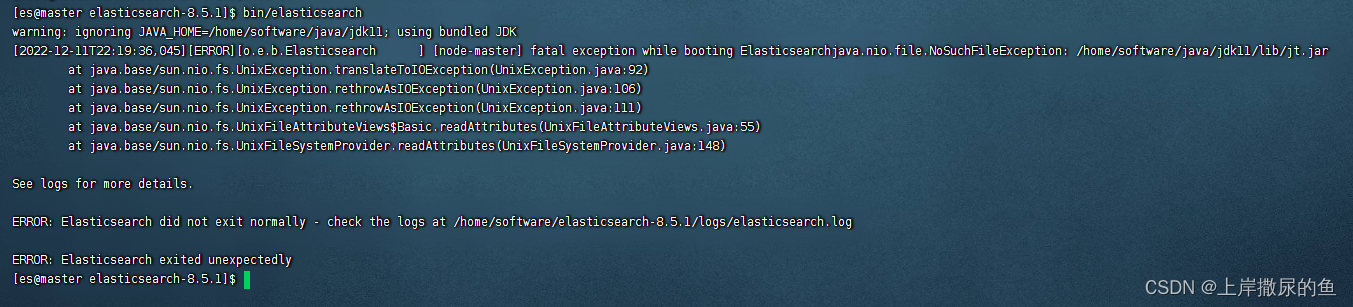
日志文件里的内容是这样的:
[2022-12-11T22:19:36,045][ERROR][o.e.b.Elasticsearch ] [node-master] fatal exception while booting Elasticsearch
java.nio.file.NoSuchFileException: /home/software/java/jdk11/lib/jt.jar
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:92) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:106) ~[?:?]
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111) ~[?:?]
at sun.nio.fs.UnixFileAttributeViews$Basic.readAttributes(UnixFileAttributeViews.java:55) ~[?:?]
at sun.nio.fs.UnixFileSystemProvider.readAttributes(UnixFileSystemProvider.java:148) ~[?:?]
at sun.nio.fs.LinuxFileSystemProvider.readAttributes(LinuxFileSystemProvider.java:99) ~[?:?]
at java.nio.file.Files.readAttributes(Files.java:1849) ~[?:?]
at java.util.zip.ZipFile$Source.get(ZipFile.java:1279) ~[?:?]
at java.util.zip.ZipFile$CleanableResource.<init>(ZipFile.java:710) ~[?:?]
at java.util.zip.ZipFile.<init>(ZipFile.java:243) ~[?:?]
at java.util.zip.ZipFile.<init>(ZipFile.java:172) ~[?:?]
at java.util.jar.JarFile.<init>(JarFile.java:345) ~[?:?]
at java.util.jar.JarFile.<init>(JarFile.java:316) ~[?:?]
at java.util.jar.JarFile.<init>(JarFile.java:255) ~[?:?]
at org.elasticsearch.jdk.JarHell.checkJarHell(JarHell.java:221) ~[elasticsearch-core-8.5.1.jar:?]
at org.elasticsearch.jdk.JarHell.checkJarHell(JarHell.java:84) ~[elasticsearch-core-8.5.1.jar:?]
at org.elasticsearch.bootstrap.Elasticsearch.initPhase2(Elasticsearch.java:180) ~[elasticsearch-8.5.1.jar:?]
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:66) ~[elasticsearch-8.5.1.jar:?]
降低 es版本,重新安装
降低版本的步骤不复杂,只需要直接删掉原来高版本的文件夹,把低版本解压后,修改config文件夹下的elasticsearch.yml。
修改后重新给权限:
chown -R es:es /home/software/elasticsearch-7.17.0
直接启动:
bin/elasticsearch
启动成功!
使用elasticsearch-head谷歌插件插件
关于几个词语的意思
下面的操作中,会有一些名称,与之前所理解的不太一样。
这里先解释一下:
- Document
文档
表示一条数据。
一个文档就是一条数据,一条记录。
- index
索引
包含有多个文档的集合
与MySQL中的索引不一样,在es中它反而像是一种数据库的概念
Http操作
因为我是装在虚拟机上,主机访问需要改ip。
使用 postman 发送请求
使用了错误的请求方式
比如在新建一个索引时,使用了POST方式:
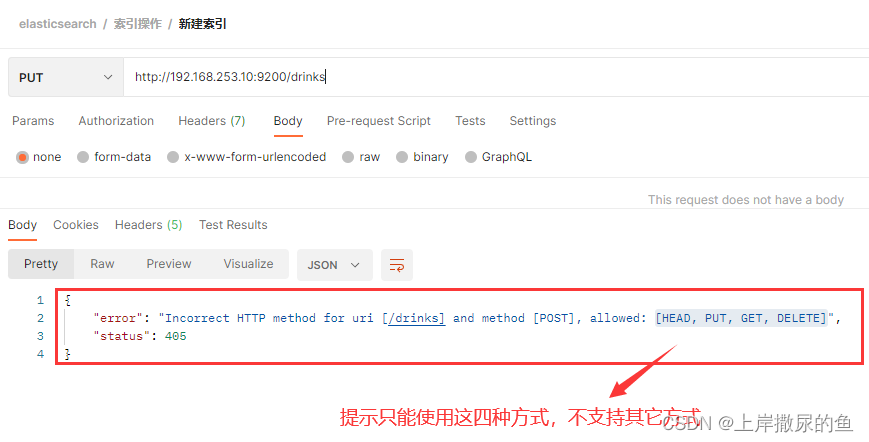
在针对索引进行操作时,只支持
- HEAD
- PUT
- GET
- DELETE
其它的请求方式不行。
一、索引操作 – 创建、查看、删除索引
1、索引 – 创建一个索引 – PUT
创建一个 drinks 索引:
http://192.168.253.10:9200/drinks
(1)成功创建索引

这个时候就相当于创建了一个 名为drinks 的数据库。
(2)重复添加索引,返回错误信息
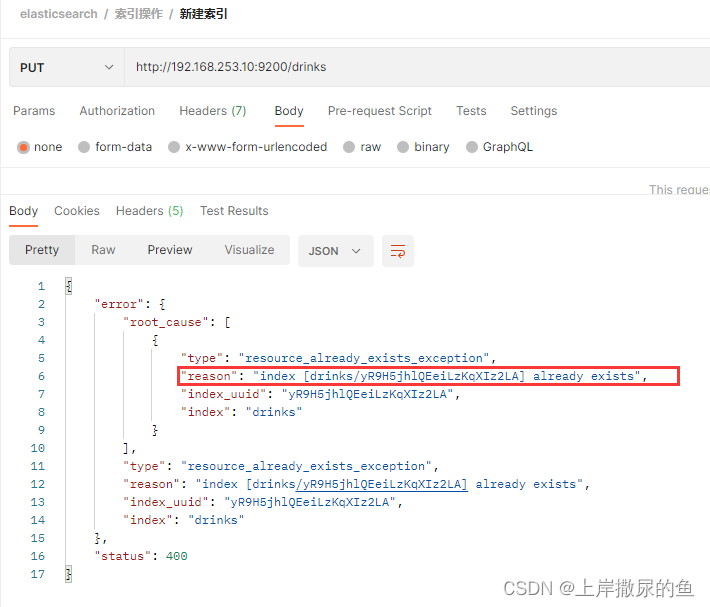
返回内容具体如下:
{
"error"(错误): {
"root_cause"(根本原因): [
{
"type"(错误类型): "resource_already_exists_exception"(资源已存在异常),
"reason"(原因): "index [drinks/yR9H5jhlQEeiLzKqXIz2LA] already exists"
(索引【索引名/索引的唯一id】 已存在),
"index_uuid"(索引唯一id): "yR9H5jhlQEeiLzKqXIz2LA",
"index"(索引): "drinks"
}
],
"type"(错误类型): "resource_already_exists_exception",
"reason"(原因): "index [drinks/yR9H5jhlQEeiLzKqXIz2LA] already exists",
"index_uuid"(索引唯一id): "yR9H5jhlQEeiLzKqXIz2LA",
"index"(索引): "drinks"
},
"status"(状态码): 400
}
2、索引 – 查看所有索引 – GET
查看所有索引(不带顶部的列释义栏)
http://192.168.253.10:9200/_cat/indices
- _cat
查看
- indices
目录
- ?v
加上的话,返回的第一行就是对每一列的释义,不加默认不会返回这个。
(1)不加 ?v 不返回列释义
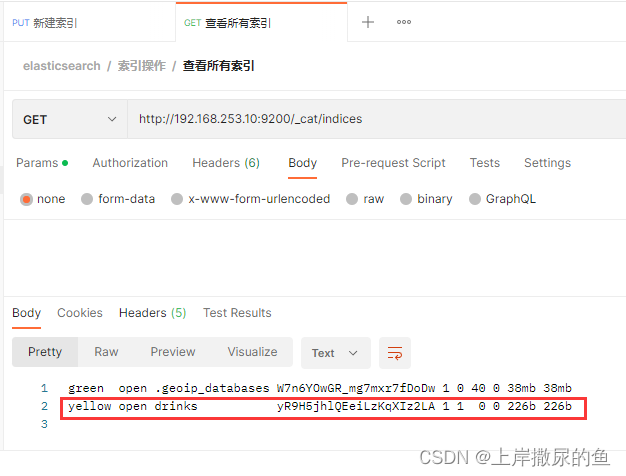
没加 ?v的话,第一行不是列释义,不熟悉字段值含义的话不明白什么意思。一般都会带上。
(2)加上 ?v 返回列释义
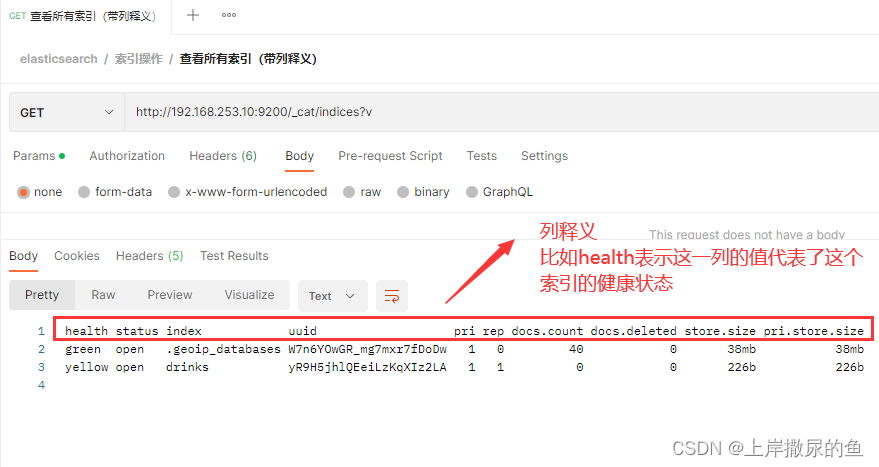
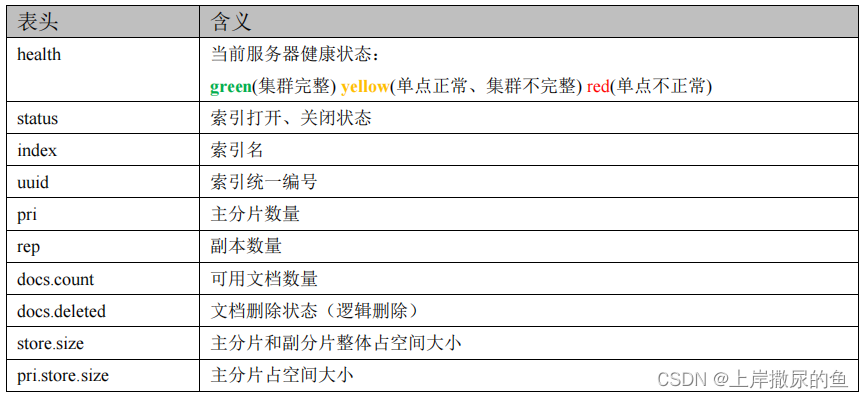
第一行为列释义,可以帮助理解每一列的值代表这个索引的什么信息状态。
3、索引 – 查看单个索引 – GET
查看单个的索引,只需要在路径中带上索引名称(drinks):
http://192.168.253.10:9200/drinks
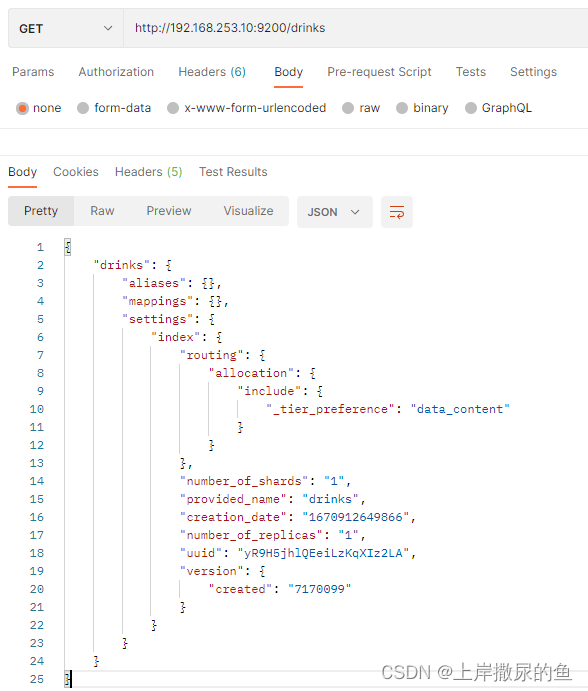
返回的json数据如下:
{
"drinks"索引名: {
"aliases"别名: {},
"mappings"映射: {},
"settings"设置(包含了这个索引的唯一id和创建时间等各种相关信息): {
"index"(设置-索引部分): {
"routing"(设置 - 索引部分 - 路由): {
"allocation"(路由分配): {
"include"(路由分配包含的设置): {
"_tier_preference"(优先层):
"data_content"(数据内容优先)
}
}
},
"number_of_shards"(分片数量): "1",
"provided_name"(索引名称): "drinks",
"creation_date"(创建日期): "1670912649866",
"number_of_replicas"(副本数量): "1",
"uuid"(索引的唯一id): "yR9H5jhlQEeiLzKqXIz2LA",
"version"(索引版本号): {
"created"(创建时的索引版本号): "7170099"
}
}
}
}
}
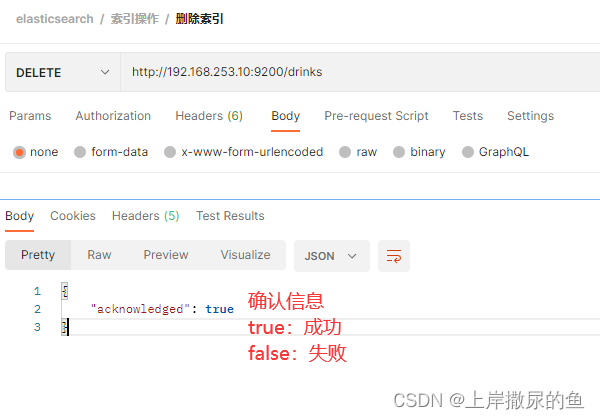
4、索引 – 删除指定索引 – DELETE
URL 与创建索引没有区别,只需要在 ip地址:端口后面加上索引名称。
只是请求的方式为 DELETE:
http://192.168.253.10:9200/drinks
(1)删除成功
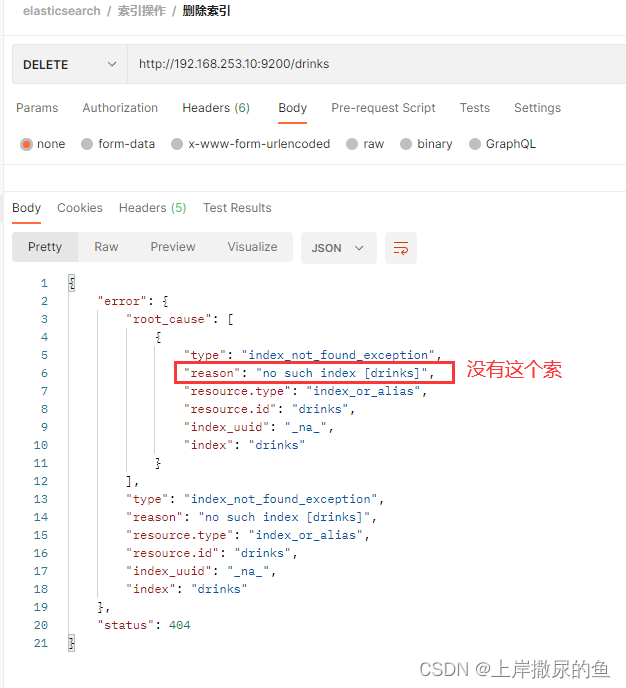
(2)删除不存在的索引
在删除drinks 数据库后,再次重复发出请求,返回的失败信息如下:
二、文档操作 –
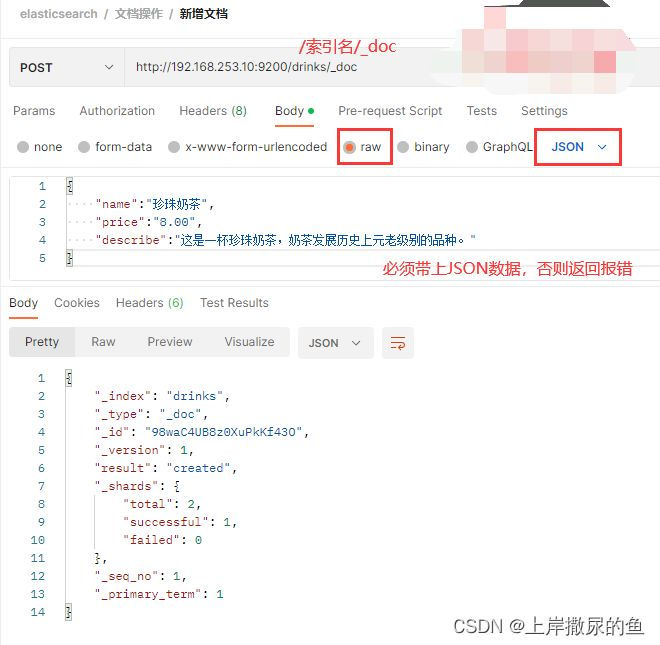
1、文档 – 创建文档 – POST
创建文档是必须将数据以JSON格式传输。
在URL中,ip和端口号都是必须的,然后就是指定文档应该创建在哪个索引下。
- URL 中的
_doc会被赋值到_type字段中- 在7这个版本,一个索引下,只允许存在一种
_type,否则创建会报错。
(1)直接创建文档,不指定id
http://192.168.253.10:9200/drinks/_doc
返回的信息如下:
{
"_index"(索引名称): "drinks",
"_type"(数据类型): "_doc",
"_id"(文档唯一id): "98waC4UB8z0XuPkKf43O",
"_version"(文档版本号,当文档被逻辑删除后会被置0): 1,
"result"(操作结果): "created"(已创建),
"_shards"(分片信息): {
"total"(总共): 2,
"successful"(成功数): 1,
"failed"(失败数量): 0
},
"_seq_no"(文档初次创建为0,每次更新文档这个值都会+1,文档被逻辑删除后此值仍会+1,不受影响): 0,
"_primary_term"(文档所在主分片的编号): 1
}
(2)创建文档数据时,手动指定唯一id号
在创建文档的URL 后面加上版本号就行:
http://192.168.253.10:9200/drinks/_doc/1
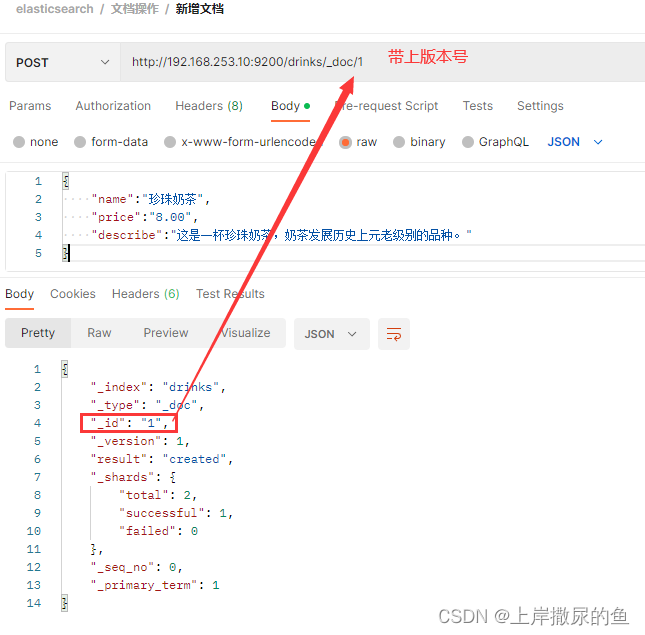
此处的 _id就相当于MySQL中的主键id,虽然系统能够自动生成一个不重复的,但是也支持手动指定一个(如果不存在重复值的话)。
2、文档 – 查看指定id的文档内容 – GET
在上面创建文档操作中,接连发送了两次创建文档的请求,根据返回的信息来看,都创建成功了。
一次是不指定版本号,一次是不指定版本号。
但是考虑到内容相同,drinks索引中是一条数据,还是两条数据呢?
在查询文档时,必须携带文档的id,也就是上面我们手动或者系统自动生成的 _id 。
通过查询 id 号为 xxx 的文档,来看一下,刚才创建的两个文档是否都能查到。
http://192.168.253.10:9200/drinks/_doc/98waC4UB8z0XuPkKf43O
_id = 98waC4UB8z0XuPkKf43O:
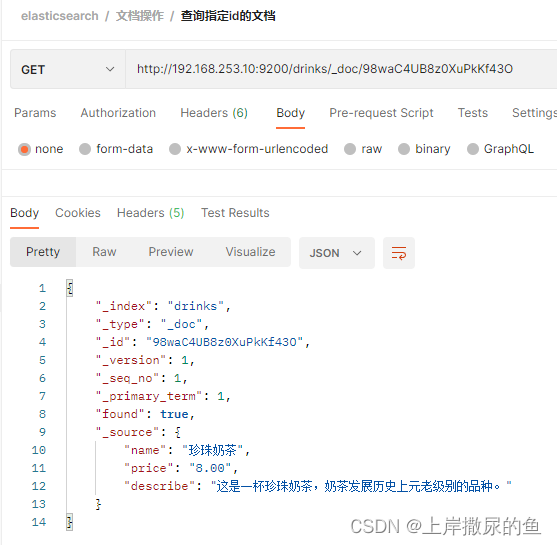
_id = 1:
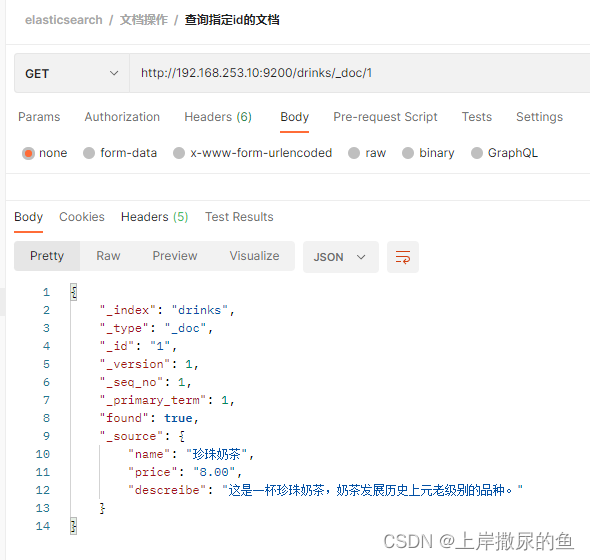
两条都能够查询到。
这种查询方式确实无法严格地验证它们确实是两条分开的数据,接下来试试查看指定索引下的所有文档内容。
3、文档 – 查询指定索引下的所有文档及内容 – GET
http://192.168.253.10:9200/drinks/_search
只需要在URL 中带上索引名和 _search(表示查询所有)
查询结果如下:
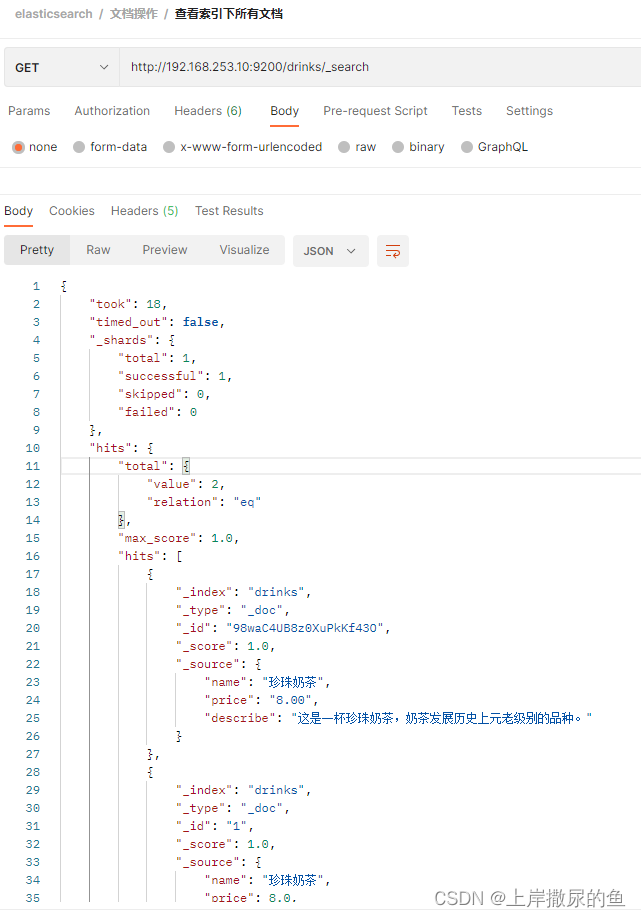
内容如下:
{
"took"(耗费时间): 18,
"timed_out"(是否超时): false,
"_shards"(分片信息): {
"total"(总共数量): 1,
"successful"(成功数量): 1,
"skipped"(跳过数量): 0,
"failed"(失败数量): 0
},
"hits"(命中信息): {
"total"(信息总览): {
"value"(总数据量): 2,
"relation"(关联): "eq"
},
"max_score"(最大评分): 1.0,
"hits"(命中数据展示): [
{
"_index"(索引名): "drinks",
"_type"(类型名称): "_doc",
"_id"(数据唯一id): "98waC4UB8z0XuPkKf43O",
"_score"
(评分,搜索结果中命中的数据会根据这个分值从大到小排序,体现的是该文档的相关性):
1.0,
"_source"(原数据内容): {
"name": "珍珠奶茶",
"price": "8.00",
"describe": "这是一杯珍珠奶茶,奶茶发展历史上元老级别的品种。"
}
},
{
"_index": "drinks",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"name": "珍珠奶茶",
"price": 8.0,
"describe": "这是一杯珍珠奶茶,奶茶发展历史上元老级别的品种。"
}
}
]
}
}
可以发现存有两条内容相同的文档数据,只是id不一样罢了。
4、文档 – 替换指定id的文档全部内容 – POST
URL与创建文档一样,并且都必须带上JSON数据。
http://192.168.253.10:9200/drinks/_doc/1
假设drinks索引中,希望将珍珠奶茶的价格从8块涨到10块钱
用新的内容
替换原来的文档内容。
除了将price价格改成10块,其它的字段按照原来的字段值填写。

可以看到上图中,响应信息里的 _version 字段值已经变成 2 了, 并且_result 值为updated就表示更新完成。
实际上相当于还是发送了一个
新建指定id的文档的请求,并且带上了数据。
es发现这个索引下已经存在这个相同id的文档,就会将内容替换掉。所以指定修改的文档id一定一定不能够出错!!!
不然会覆盖掉其它的什么文档内容。
如果直接发送这样的JSON内容,则是表示我们希望用这个JSON数据替换掉原有的文档内容。
如果仅仅希望修改文档中的某一个字段值,而不改变其它的呢?
5、文档 – 更新指定id文档的指定字段值 – POST
http://192.168.253.10:9200/drinks/_update/1
仅更新字段值,并且只需要传输新的字段值。
不需要再把那些重复的不更更改的字段和值再写入JSON。
JSON格式数据如下:
{
"doc": {
"price": 8.00
}
}
外层先声明一个doc,里面只需要写想要更新的字段和新的字段值就行了。
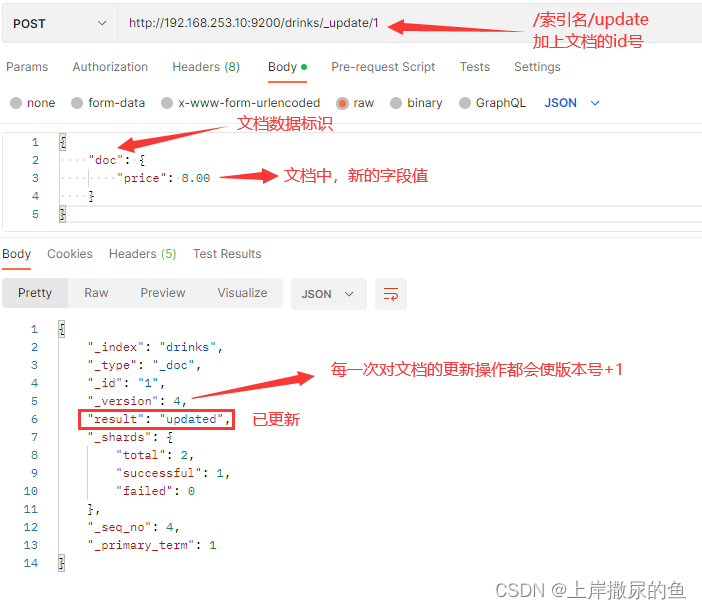
查看id为1的文档内容后,验证字段值确实已更新。
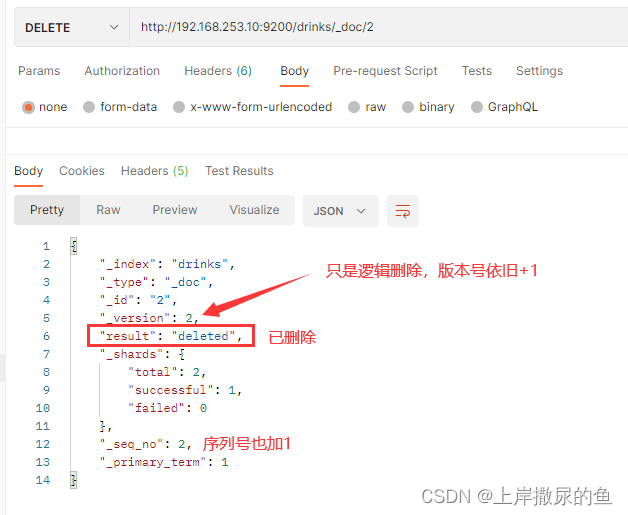
6、文档 – 删除指定id的文档(逻辑删除) – DELETE
这种删除模式只是逻辑删除,实际上数据还存在,只是被特殊标记了,无法再查询到了。
经过一些试验后,现在drinks索引下,存有这两条数据:

现在删除掉红豆奶茶,也就是文档id为2的数据,使用DELETE请求:
http://192.168.253.10:9200/drinks/_doc/2
结果如下:
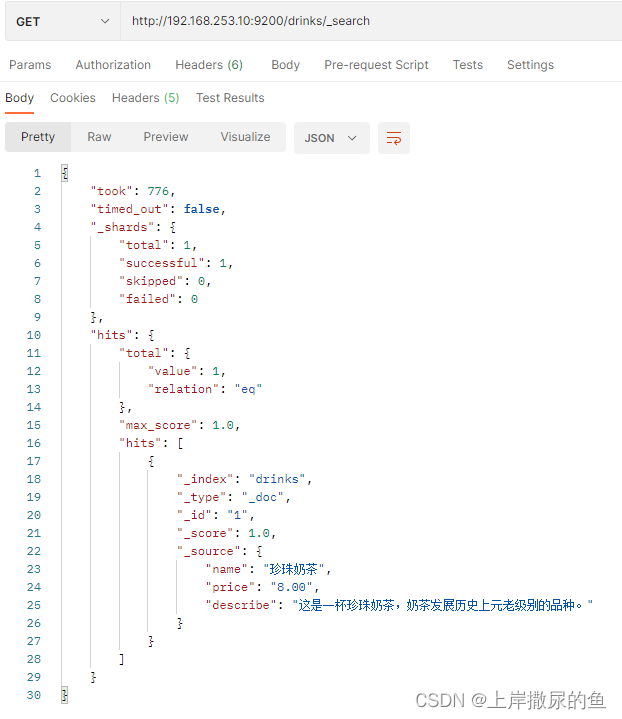
查询的话,就只能查询到一个珍珠奶茶了:
7、文档 – 删除指定条件的文档 – POST
现在drinks索引下有珍珠和红豆两种:

假如只想删除name为珍珠奶茶的文档,保留红豆奶茶。
不严格匹配的条件
http://192.168.253.10:9200/drinks/_delete_by_query
- _delete_by_query
根据条件删除
JSON为:
{
"query": {
"match": {
"name": "珍珠奶茶"
}
}
}
- query 表示携带条件
- match 表示不严格匹配内容
然而返回的信息中发现deleted的值是2,检查drinks索引下,红豆奶茶也被删掉了:
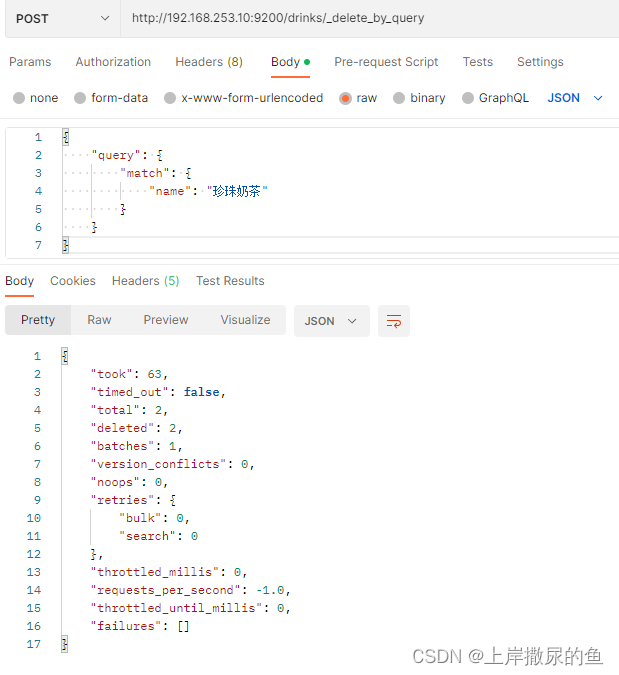

这个结果就与最开始的目的相违背了,因为红豆奶茶也被删除了!
原因分析
珍珠奶茶 四个字,同样会被分词,再进行匹配。
请求删除的字符串是:珍珠、奶茶、奶、茶……
而红豆奶茶和珍珠奶茶都带了奶茶两个字。
请求条件的字符串被拆分成多个词后,只要name中满足一个条件,就视为满足条件。
而不是严格地去匹配。
严格匹配条件
重新把两条数据加进去,修改一下JSON:
URL:
http://192.168.253.10:9200/drinks/_delete_by_query
JSON:
{
"query": {
"match_phrase": {
"name": "珍珠奶茶"
}
}
}
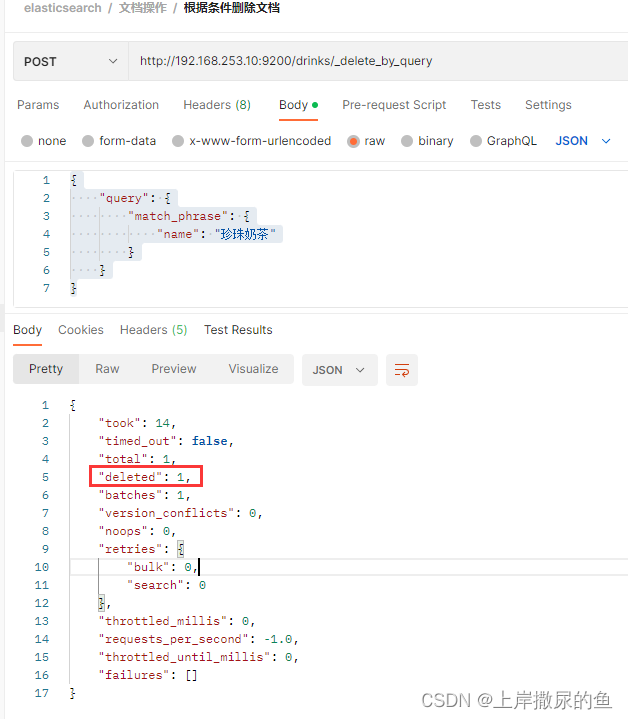

操作结果就是,只删除了珍珠奶茶,而红豆奶茶没受到影响,达到目的。
query 条件中:
match是不严格匹配
match_phrase是严格匹配
一定要根据使用场景,使用正确的字段。
query 条件匹配,在 条件查询中同样会用到。
映射操作
















 2184
2184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











