






一、虚拟内存
物理地址:计算机的主存由M个连续的字节大小的单元组成,每个字节由自己唯一的物理地址。

虚拟地址:CPU生成一个虚拟地址,MMU翻译该地址成为一个物理地址,对主存进行访问。**虚拟内存是在磁盘上分配的空间。**虚拟内存和物理内存之家通过块(虚拟页、物理页)来交换数据。

页表(PTE数组,存放在物理内存中):将虚拟页映射到物理页

VPN作为页表的索引
驻留位即为有效位: 1表示该页在内存中有映射,0表示没有映射会出发缺页异常
保护位 为允许对该页做何种类型的访问(只读、可读写、可执行)
修改位: 表示该页修改过,和硬盘中的文件不一样,置换的时候需要保存到磁盘中
访问位(引用位):LRU标记位
**分页:**将物理内存分成相同大小的页(比如4k一个页),那么一个物理地址可以表示成PPN+PPO(物理页表序号+物理页表偏移量)。把虚拟地址也分成和物理页相同大小的页,这样的话虚拟地址也可以用VPN+VPO(虚拟页表序号+虚拟页表偏移量)。因此PPN和VPN不同,VPO和PPO相同
DRAM未命中称为缺页:

缺页异常处理:
1)如果内存中有空闲页,选择其中一帧,将磁盘中的对应的内容复制到该空闲页,并修改页表
2)如果内存中没有空闲页,则需要采用页面置换算法,选择其中某个物理帧,如果该帧的修改位为1,则需要把该帧的内容保存到磁盘,并将对应的磁盘中的内容复制到该物理页中,并求改页表。然后将磁盘中的对应的内容复制到该空闲页,并修改页表
3)重新运行发生异常中断的指令
每次CPU生成一个地址,MMU都会读取一个PTE,因此在PTE中加入控制位来约束对虚拟页的访问

地址翻译:
CPU会生成一个虚拟地址VA,MMU会根据VA的前p位(VP大小位2p)在PTE(每个进程都有一个PTE)上找到对应的PPN。若该有效位为1,VPO和PPO相同,连接后即是对应的PA。若该有效位为0,则会调用缺页异常程序,进行页交换,再次调用产生异常的指令,进行翻译。

TLB(快表):
由于PTE存在SRAM中,每次访问SRAM的开销比较大,因此在MMU中有一个缓冲TLB。
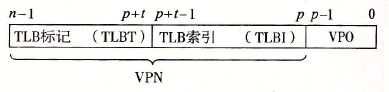
上图用于查找定位对应的PTE,索引用来查找对应的组,标记用来查找同一组中不同的PPN。

由于虚拟地址的位数比物理地址大得多,因此PTE表也需要一个很大的空间。因此采用多级页表(页目录+页表)。将物理地址的前面几个bit平均分成等长的部分,每个i级页表指向下一个i+1级页表的基址,最后一级指向一块物理内存。**当一个PTE为空时,他所对应的下一级页表不存在。**每增加一级页表就要多增加一个对内存的访问。


牺牲页的选择算法:
LRU(最近最少使用):选择最近最长时间没有使用的页作为牺牲页。采用链表实现,最近使用过的为头节点,没有使用过的为尾节点,每次访问一个页找到对应的页面,移动到头节点。缺页发生时候,把链表末尾的页面淘汰。
**LRU近似实现(最近没有使用):利用引用位,将所有页形成一个循环队列,选择替代页的时候,从最老的页开始,访问位为1,则清零,指针指向下一个页,否则该页被替代。由于缺页发生的概率比较小,因此一段时间后,整个循环队列的访问位都是1,这样就退化成了FIFO算法,因此需要一个快指针,在一定时间内利用快指针将循环队列的访问位清零。
belady现象:FIFO算法,分配的物理页面增加,缺页率反而增加。
二、动态分配内存:

堆在未初始化的数据的后面,向上生长(地址变大),是一个连续块的集合。
void* malloc(size_t size)
//成功则返回成功分配的地址,否则返回NULL并且设置错误,返回的地址做字节对齐,32位
void* free(*p)
**碎片:**有内存空间,但是不满足分配条件,不能进行分配
内部碎片:(有效负载)存储的数据小于块的大小,需要进行对齐,维护堆的数据结构,造成一些空间不可使用
外部碎片:有空间,但是连续的空间不够大
1、隐式空闲链表:

因为头部包含了大小,因此可以知道下一块的地址,因此称作隐式空闲链表。
分配过程:
1)首先找到匹配的空闲块:采用放置策略来查找(下一次适配、首次适配、最佳适配)
2)分割空闲块,如果分配的空闲块太大的话就进行分割
3)若没有找到合适的空闲块,会尝试去合并相邻的空闲块(释放可能也会合并相邻块,也可能推迟合并取决于实现)。
合并前面一块使用边界标记技术:
4)已经达到最大程度的合并了,会通过sbrk函数申请额外的堆内存
2、显式空闲链表:

这样分配的时间就从总块数的线性时间减少到了空闲块树的线性时间。
释放块的策略:
1)LIFO:最新释放的块放在链表开始处,释放一个块可以在常数时间内完成
2)按照地址顺序,链表每个块的地址都小于后继的地址。释放一个块就需要线性时间来查找前驱。
3、分离的空闲链表
维护多组空闲链表,每组的块的大小近似
**1)简单分离存储:**每个链表的块大小相同。分配一个给定大小的块,首先对应大小的链表是否为空,不为空则插入到链表头部,否则就向操作系统请求分配额外内存片并分割,形成新的空闲块。释放块则需要将块加入链表头部即可。不会进行合并,不需要头部和脚部标记,只需要一个指针。
问题:为什么会引起大量的外部碎片?(简单地说就是由于不会进行合并造成的)
假设一个应用大量分配释放第一个大小类,然后大量分配释放第二个大小类。。。对每个类都不会做合并,最后分配一个更大的类的时候,有足够的空间,但是没有足够的连续空间。
2)分离适配:每个链表的块大小不同,属于同一个大小类,采用隐式\显示空闲链表链接。首先确定请求的大小类,查找到合适的块(如果太大进行分割,将剩下的部分加入到相对应的链表中)。如果没有找到就对下一个链表进行查找,空闲链表中没有合适的块就从内存中分配,从中分配出一块,将剩余的放到对应的空闲链表中。
伙伴系统是特殊的分离适配。每个链表的大小都是2的幂。首先会将分配的大小向上取2的幂次,查找第一个适配的块,如果偏大,则需要分割(分割剩下的半块叫做伙伴),放在相应的空闲链表中。如果释放了一个块,则需要合并他的伙伴,如果伙伴被分配则停止合并。
缺点:要求块大小位2的幂次,因此会造成内部碎片。















 4648
4648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









