






我们将介绍RAG(检索增强生成)的评估工作流程
RAG工作流程的部分
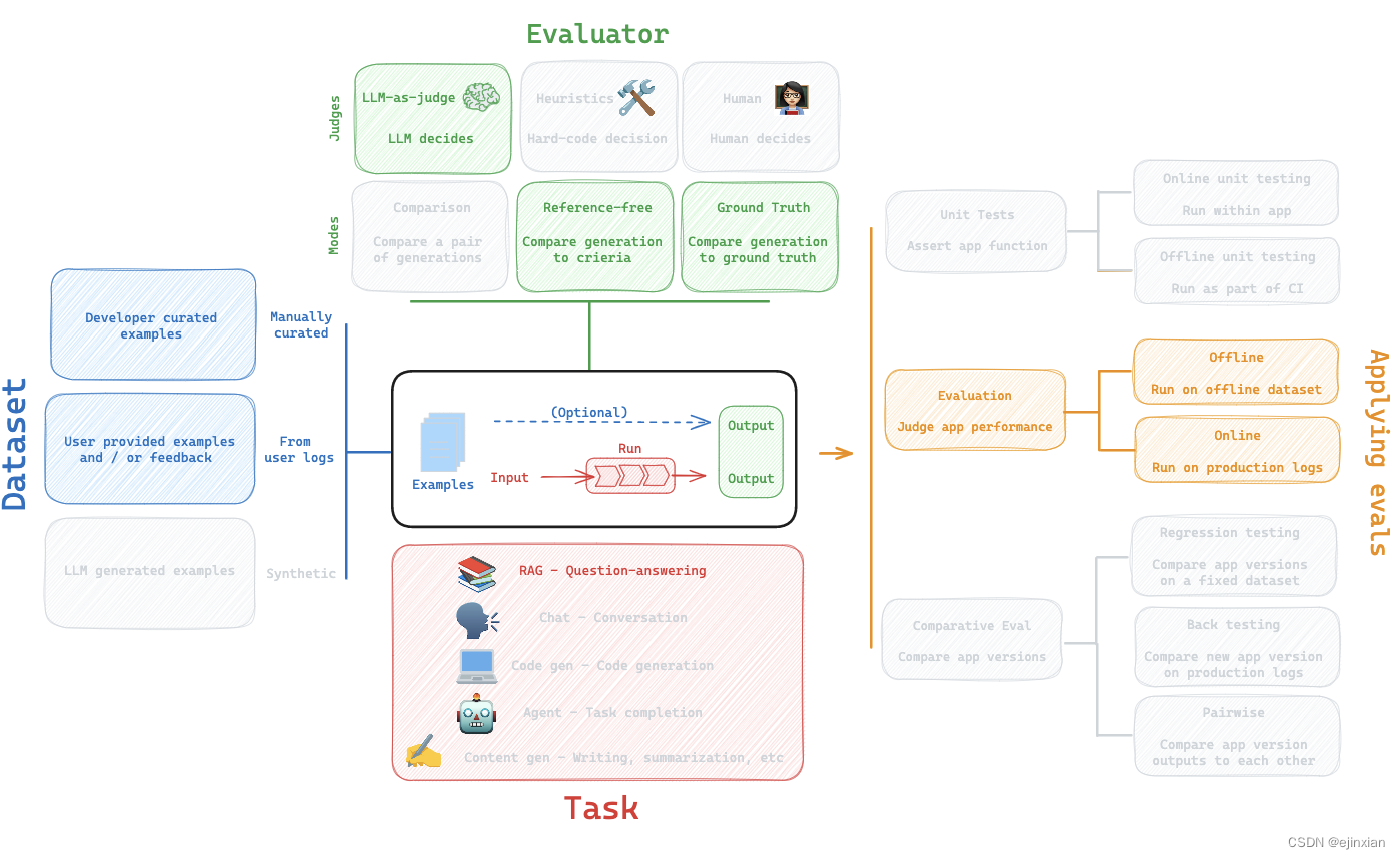
数据集
这里是我们将要使用的LCEL (LangChain Expression Language)相关问题的数据集。
这个数据集是在LangSmith UI中使用csv上传创建的:
https://smith.langchain.com/public/730d833b-74da-43e2-a614-4e2ca2502606/d
在这里,我们确保设置了OpenAI和LangSmith的API密钥。
import getpass
import os
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("OPENAI_API_KEY")
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
_set_env("LANGCHAIN_API_KEY")
任务
这里是一个将在LCEL (LangChain表达式语言)文档上执行RAG的链。
我们将严格使用LangChain来创建检索器和检索相关文档。
整个管道不使用LangChain;无论您的管道是否使用LangChain构建,LangSmith都可以工作。
这里,我们将检索到的文档作为最终答案的一部分返回。
然而,下面我们将说明这不是必需的(使用中间步骤的评估)。
有关这方面的更多信息,请参阅我们的RAG-From-Scratch repo和教程视频系列。
评估
用户通常会对至少4种类型的RAG eval感兴趣。
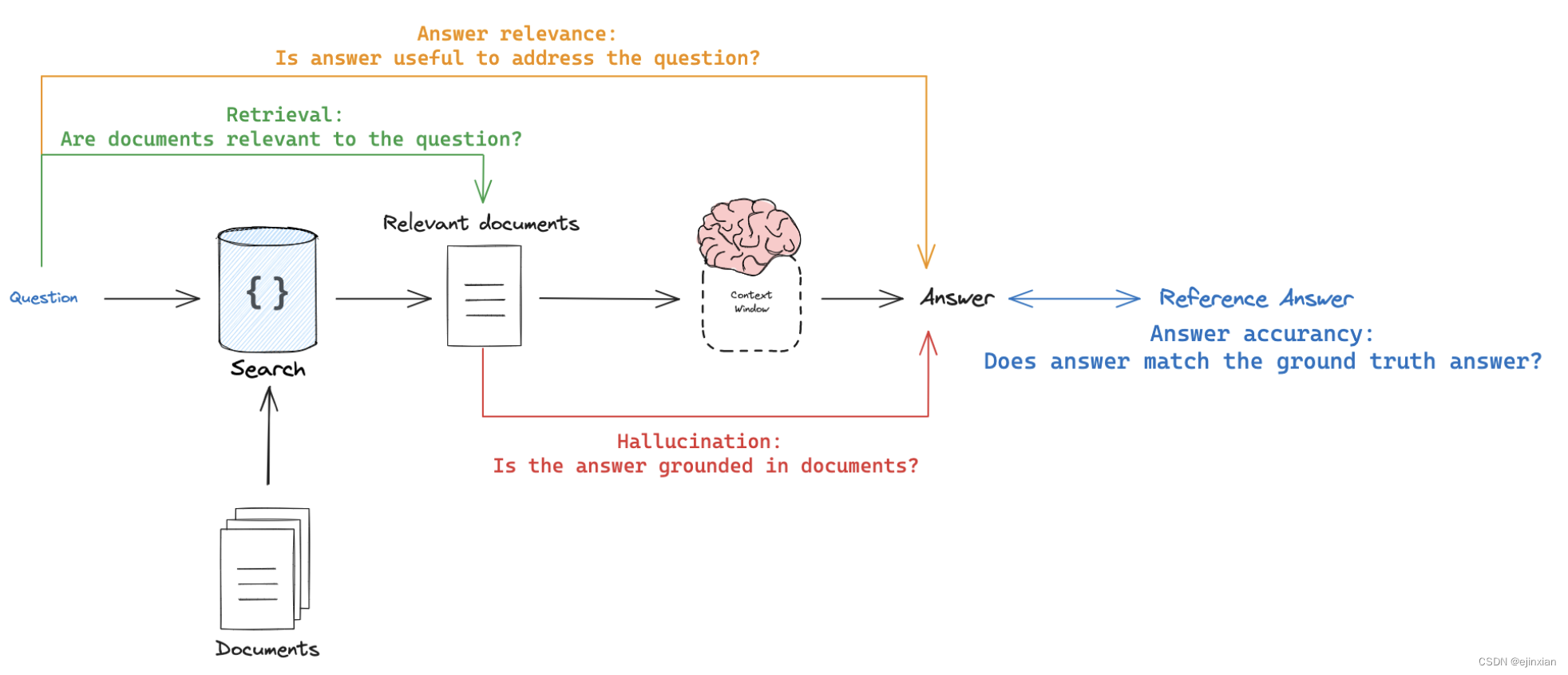
回应vs参考答案
目标:衡量“相对于基本事实的答案,RAG链的答案有多相似/正确”
模式:使用通过数据集提供的真实(参考)答案
评委:用llm作为评委来评估答案的正确性。
响应vs输入
目标:衡量“生成的响应如何处理初始用户输入”
模式:无参考,因为它会将答案与输入问题进行比较
评委:用法学硕士作为评委来评估答案的相关性、有用性等。
响应与检索文档
目标:测量“生成的响应在多大程度上与检索的上下文一致”
模式:无引用,因为它将把答案与检索到的上下文进行比较
评委:用法学硕士作为评委来评估忠诚、幻觉等。
检索文档vs输入
目标:衡量“这个查询的检索结果有多好”
模式:无引用,因为它会将问题与检索到的上下文进行比较
评委:用法LLM-as-judge评委来评估相关性
来源:















 6654
6654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









