







创建三张表格,test,test1,test2,每张表插入十万行数据,这三张表的schema都如图1所示,不同的是每张表的des字段的长度不同(但同一张表格内,每一行des字段的长度都是相同的),如图2所示。


重启测试机,两次执行sql查询语句以统计每张表cnt字段的累加和,并获取耗时如图3、4所示


对比图3和图4,会发现图3的查询时间远大于图4查询的时间,这是因为执行第一次统计的时候,三张表的数据都只存在磁盘里面,mysql统计的时候,需要将三张表的数据先从磁盘里面读到内存数据页里面,然后才能进行统计操作,这发生了大量的随机IO读,从而导致统计缓慢。而执行完第一次统计之后,磁盘里面的数据都被读到内存页里面了,因此执行第二次统计的时候就无需再读磁盘,直接统计内存页里面的数据即可,避免了随机读操作,所以第二次统计速度远大于第一次统计速度。
我们再看图3,对比test1和test2表格的统计速度,发现test2的统计时间远远大于test1的统计时间,这是为什么?我们回到图2,发现test2的des字段的长度(7168)远大于test1的des字段长度(0),是了没错,这就是造成test2比test1慢的原因,我们知道,如果mysql要读取字段cnt的值的话,它需要让InnoDB把一整行数据都读入到内存当中,然后才能去读cnt的值,所以如果一行数据过长的话,那么需要从磁盘中读取的数据量就多了,特别是执行统计类的操作,随机读IO会大大增加,这就造成了图3中test1与test2对比的情况。
说到这里,细心的读者可能发现,不对啊,表test的des字段可是要比表test2的des字段大多了,那为啥图3中test的统计时间却比test2的小那么多。要解释这个问题,就不得不提InnoDB的行溢出的概念了,我们知道InnoDB是以页为单位来存储数据的(一个页里有多行数据),页的大小为16KB,也就是16384个字节,而我们的表格test光是des字段就有32768个字节,显然这一行数据就已经超过了一个页的大小,造成了行溢出。一般情况下,InnoDB都是将数据存放在B-tree Node的页类型当中,也就是那个16KB的页,但是发生了行溢出时,InnoDB会将溢出的行分为两部分,一部分放在B-tree Node的页类型中,另一部分放在Uncompress BLOB页中,如图5所示,B-tree Node页中存放着前768个字节的前缀数据,之后跟的偏移量,指向Uncompress BLOB页。所以我们的test表的InnoDB行中其实只存放了字段des的前缀和相应的偏移量,一共几百字节,比test2要小的多,那test的统计时间自然是要小于test2的。

如果对行溢出感兴趣的读者可以翻阅《MySQL技术内幕 InnoDB存储引擎 第2版》一书,这里就不赘述了。
我们再看看有没有方法能够优化表test2的查询速度,答案是有的,我们知道,innodb是以B+树的方式来组织索引结构的[1],其中主键索引树的叶子节点存的是整行数据,非主键索引树的叶子节点存的是主键的值,我们当前的统计之所以这么慢是因为我们从主键索引树的叶子节点中读了整行数据,倘若我们能够为字段cnt建立索引,那么我们统计的时候就无需去遍历主键索引树了,直接遍历非主键索引树即可,就避免了读整行数据,减小了随机读IO。
执行语句
ALTER TABLE test2 CREATE INDEX ix_cnt(`cnt`) USING BTREE;
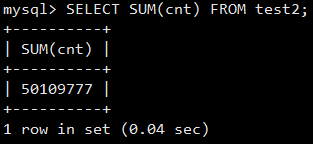
重启测试机后查询时长如图6所示
[1](极客时间)深入浅出索引(上).
















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









