









Spark1.4.0让你透视整个Spark分布式执行
高速演进的Apache Spark这一周刚刚发布1.4.0,除了SparkR的重量级发布,一个值得一提的是对Spark分布式执行的可视化。
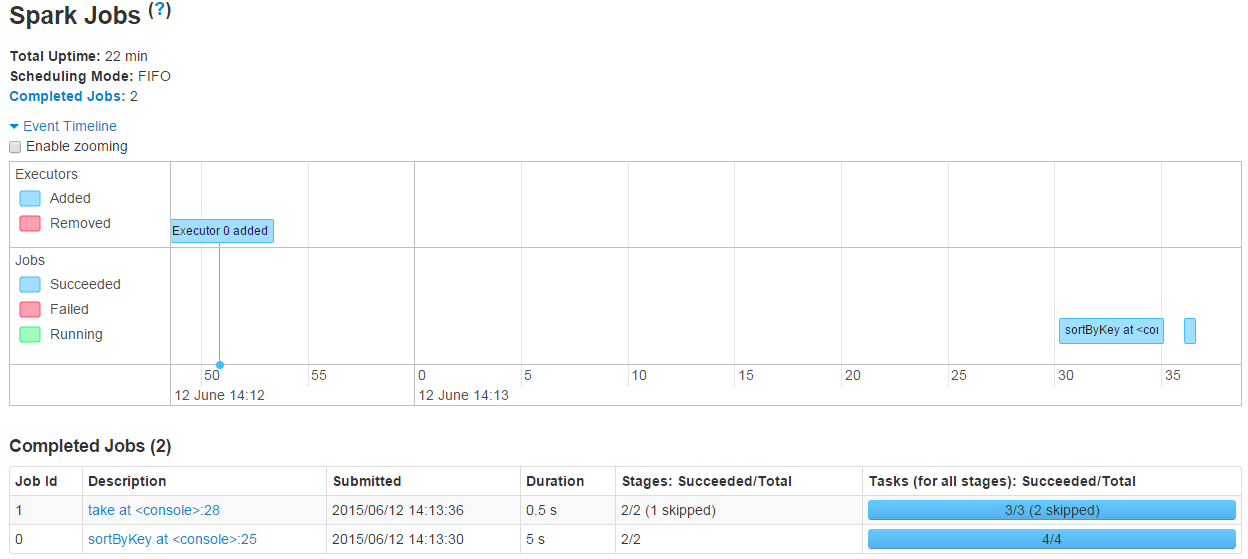
Job时间线
在Jobs页面添加了Event Timeline
DAG图
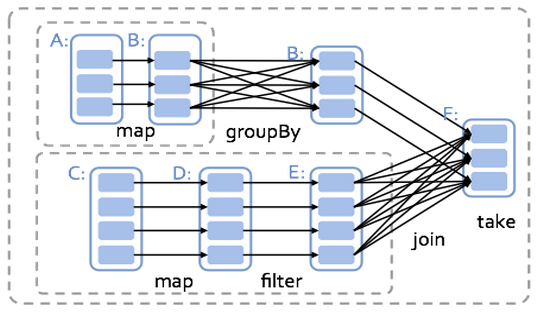
Spark执行的核心是生成DAG(有向非循环图),把整个计算分解成若干个Stage,把narrow dependency的RDD合在一个stage执行,把wide dependency的RDD分到不同的Stage。最后并行或串行的在Spark集群里执行Stage。
下面就是一个例子,实际开发优化,往往要分析DAG,看看Stage是否能合并,过多的Stage往往意味着大量缓慢的跨节点数据Shuffle。
我运行一个简单的Word Count并排序的Scala程序。
val rdd = sc.textFile("hdfs://hadoop1:8000/README.txt")
val wordcount = rdd.flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_)
val wordsort = wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
wordsort.take(10)像Spark1.3以前的一样,可以看到所有的Stage清单。
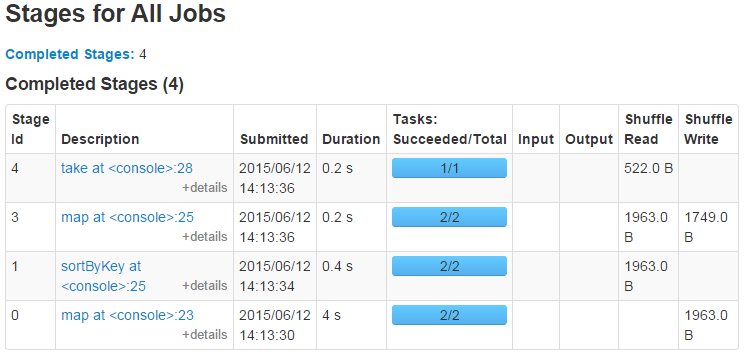
打开Stage 0和Stage 1就可以看到对应的DAG的图了,每一个transformation对应相应的RDD类型,是不是很直观。
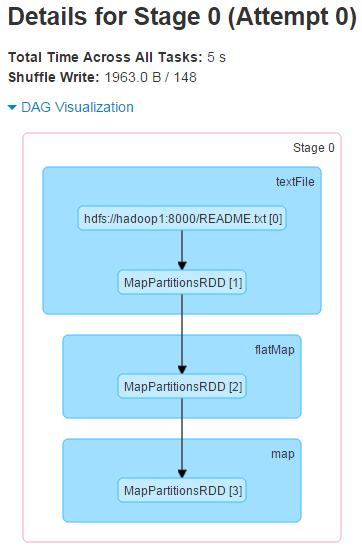
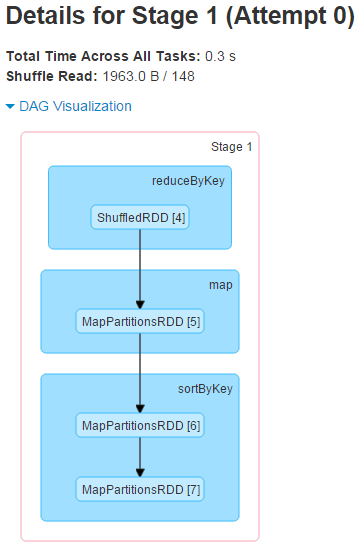
Stage的开销时间线
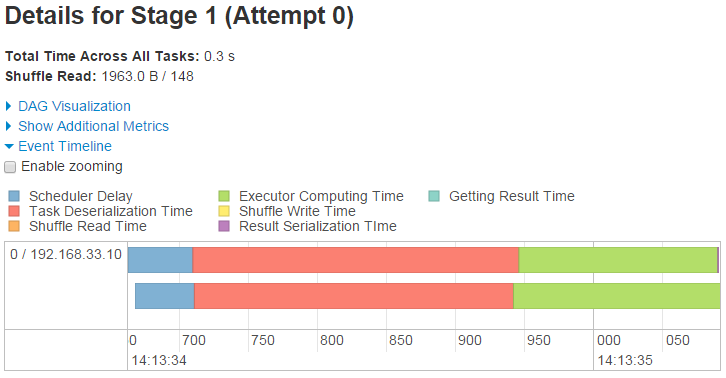
除了DAG图,更牛逼的是Stage详细页面上,还可以看到同一个Stage里消耗在不同计算、Serialize、Shuffle方面的开销。















 932
932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









