







一、并查集概念
并查集实现不相交集合的元素查询和集合合并。
二、并查集的实现
并查集的实现大概是一个森林的结构,节点属性father为节点的父亲,其中 x.father == x 作为根节点的标志,(也可以指向x.father == -1等等作为标志),各元素用所在树的根节点代表,查询一个元素相当于返回这个元素所在树的根节点,合并两个集合是把一个集合的根节点作为另一个集合的根节点的孩子,即合并setA, setB 的主要操作为 setA.root.father = setB.root;
下面贴代码:(用数组实现)
#define MAX 10005
int father[MAX];
void makeset(int n)
{
for (int i=1;i<=n;i++) father[i] = i;
}
int find(int x)
{
return x==father[x]?father[x]:father[x]=find(father[x]);
}
void unionset(int x,int y) //合并y所在集合到x所在集合
{
father[find(y)] = find(x);
}代码都只要一句话,非常简洁,下面介绍一下代码细节:
void makeset(int n);
创建n个集合,第i个集合只含有一个元素i(i=1,...,n)
int find(int x)
查找元素x所在集合,用返回集合根节点表示。函数用递归形式给出,也可以改成迭代形式。递归的终点是x==father[x] ,即x是根节点,然后返回根节点。这行代码还实现了路径的压缩,当查找一个元素时,走过路径的节点在递归下依次变成根节点的孩子,这样减少下次查询到该节点的时间。
void unionset(int x,int y)
先寻找x和y的所在集合,然后把y所在集合根节点变成x所在集合根节点的孩子。
三,简单例题
思路:给集合加上一个num属性记录集合中有的元素个数,注意unionset函数要更新num[x]。
代码:
#include <cstdio>
#define MAX 30005
int father[MAX], num[MAX];
void makeset(int n)
{
for (int i=0;i<n;i++)
{
father[i] = i;
num[i] = 1;
}
}
int find(int x)
{
return father[x]==x?father[x]:father[x]=find(father[x]);
}
void unionset(int x,int y)
{
x = find(x);
y = find(y);
if (x==y) return ;
father[y] = x;
num[x] += num[y];
}
int main(void)
{
int n,m,k,i,a,b;
while (~scanf("%d%d",&n,&m),n|m)
{
makeset(n);
while (m--)
{
scanf("%d",&k);
if (k) scanf("%d",&a);
for (i=1;i<k;i++)
{
scanf("%d",&b);
unionset(a,b);
}
}
printf("%d\n",num[find(0)]);
}
return 0;
}2、poj2524 Ubiquitous Religions
思路:和前面一题几乎一样。
代码:
#include <cstdio>
#define MAX 50005
int father[MAX],num[MAX],diff;
void makeset(int n)
{
for (int i=1;i<=n;i++)
{
father[i] = i;
num[i] = 1;
}
}
int find(int x)
{
if (x!=father[x]) father[x] = find(father[x]);
return father[x];
}
void unionset(int x,int y)
{
x = find(x);
y = find(y);
if (x==y) return ;
if (num[x] > num[y])//把num小的集合并到num大的集合,貌似可以减少树的高度。
{
father[y] = x;
num[x] += num[y];
}
else
{
father[x] = y;
num[y] += num[y];
}
diff--;
}
int main(void)
{
int n,m,cas = 1;
while (~scanf("%d%d",&n,&m),n|m)
{
diff = n;
makeset(n);
for (int i=0;i<m;i++)
{
int a,b;
scanf("%d%d",&a,&b);
unionset(a,b);
}
printf("Case %d: %d\n",cas++,diff);
}
return 0;
}3.、poj1182 食物链
思路: 给元素增加一个关系域,在同一集合中,两个元素关系域相同代表同类,关系域相差1(在模3的情况下)代表前者吃后者。
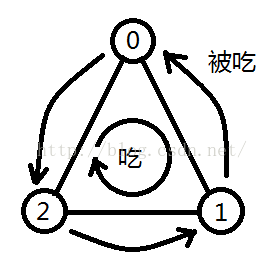
每次遇到x,y,如果它们在不同集合,那么它们还没有关系,一定不是谎言,然后把第两个集合并到第一个集合上,并根据操作是1或2更新第二个集合每个元素的关系域。
集合关系域的更新如下:
假设输入为d,x,y, x 所在集合根为 p:
p.relation = (y.relation - x.relation + d + 2 )%3; //(1)然后依次迭代p的每个棵子树,
a.relation = (a.relation + a.father.relation)%3; //(2)
现在我们来看它们已经在同一集合的情况。这时,它们必然已经有关系了,那么就要判断语句给出的关系是否正确。还是假设输入为d,x,y,如果
(relation[x]-relation[y]+3)%3 != d-1最后要注意的是,在真正实现的时候,(2)那里并不需要真的把整棵树更新,相反我们可以在查找函数上做功夫,使得每次查找的时候就更新查找那个结点的关系域就行了。
最后的最后,本题数据有点坑爹!只能一次输入,改成多次输入会WA。
代码:
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <algorithm>
#define MAX 50005
using namespace std;
int father[MAX], relation[MAX];//仍然是用数组表示
void makeset(int n)
{
for (int i=1;i<=n;i++)
{
father[i] = i;
relation[i] = 0;
}
}
int find(int x)
{
if (x!=father[x])
{
int temp = father[x];
father[x] = find(father[x]);
relation[x] = (relation[x]+relation[temp])%3; //在查找的时候更新所需结点的关系域
}
return father[x];
}
void unionset(int x,int y, int d)
{
int p = find(x), q = find(y);
father[p] = q;
relation[p] = (relation[y]-relation[x]+d+2)%3; //这里只更新p的关系域,当查找到p的子树种节点的时候,查找函数会帮忙更新那个结点
}
int main(void)
{
#ifdef EMO
freopen("in.txt","r",stdin);
freopen("out.txt","w",stdout);
#endif
int n,k,lie=0;
scanf("%d%d",&n,&k);
makeset(n);
while (k--)
{
int d,x,y,p,q;
scanf("%d%d%d",&d,&x,&y);
if (x>n || y>n) {lie++; continue;}
p = find(x);
q = find(y);
if (p!=q) unionset(x,y,d);
else if ((relation[x]-relation[y]+3)%3!=d-1)
{
lie++;
}
}
printf("%d\n",lie);
return 0;
}四、小结
并查集的代码并不复杂,可以说很简单。并查集的用处很广,可以作为很多算法的辅助算法。之后还会继续更新一些有关并查集的姿势。
五、参考资料及扩展阅读
http://www.cnblogs.com/cherish_yimi/archive/2009/10/11/1580839.html
http://blog.csdn.net/lalor/article/details/7388805















 2874
2874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









