



因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
点击关注#互联网架构师公众号,领取架构师全套资料 都在这里
上一篇:2T架构师学习资料干货分享
大家好,我是互联网架构师!
代码运行的环境
基础实现的性能
从哪个方向开始优化?
开启 MySQL 批处理
开启多线程写入
进一步的优化方向
最近碰到一个场景,从 XML 文件导入 6 万多条数据到 MySQL 中。需求并不复杂,基于 XML 文件和 xlsx 文件的相似性,其实这就是一个老生常谈的数据导入问题。
本文将介绍我如何将导入操作耗时从 300 秒优化到 4 秒。

代码运行的环境

Java 代码在笔记本上运行,MySQL 在局域网内的虚拟机上。
笔记本配置八核 i9 2.3 GHz,16 GB 内存,最近气温偏高,CPU 存在降频现象,对执行耗时有一定影响。
MySQL 数据库运行在 VirtualBox 虚拟机内。虚拟机分配了 4 核 4 GB 内存,但宿主机硬件性能比较羸弱,导致 MySQL 写入耗时较长。
JDK 采用 21 版本,MySQL 采用 8.0 版本。
在这个环境配置下,从 XML 文件中读取一条数据耗时 0.08 秒,向 MySQL 导入一条数据耗时 0.5 秒。

基础实现的性能

基础实现就是过程式处理方式。
void importData() {
Document doc = 解析 XML 文件,获取 Document 对象;
List<Product> products = 从 Document 对象中提取数据,返回集合;
遍历 products 集合,逐条插入 MySQL;}基础代码比较简单,就不详细展示了。本地测试整个流程需要 300 秒。
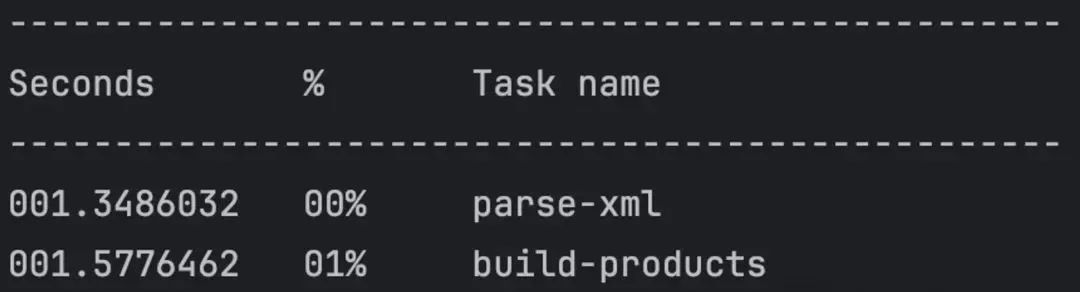
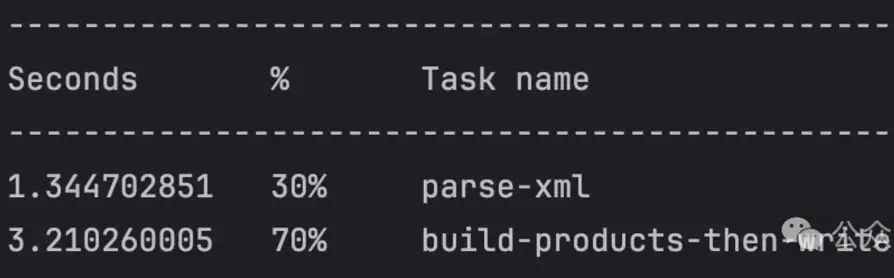
其中 parse-xml 和 build-producs 可以合并,统一看作解析 XML 文件,相对于写入 MySQL 的耗时,这部分简直微不足道。
对应内存占用为峰值 656.6 MB。
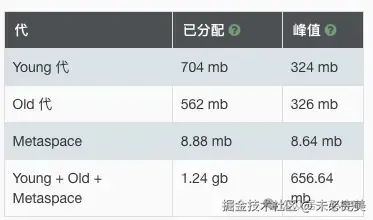
总之,300 秒和 656 MB,就是最初的起点。旅途就此开始。

从哪个方向开始优化?

很明显,优化 MySQL 写入性能是目前最具性价比的方向,那长达 298.3 秒的耗时简直就是一片尚未开采的富矿,蕴藏着极大的优化空间。
对于写入的优化通常有两个方向:写聚合和异步写。单次写入操作有一定成本,写聚合是指在一次写操作里尽可能多地写入数据,通过减少操作次数来降低成本。异步写是指异步进行写入过程的耗时操作,引入队列作为中转容器,通过减少单次操作的成本来降低总体的成本。
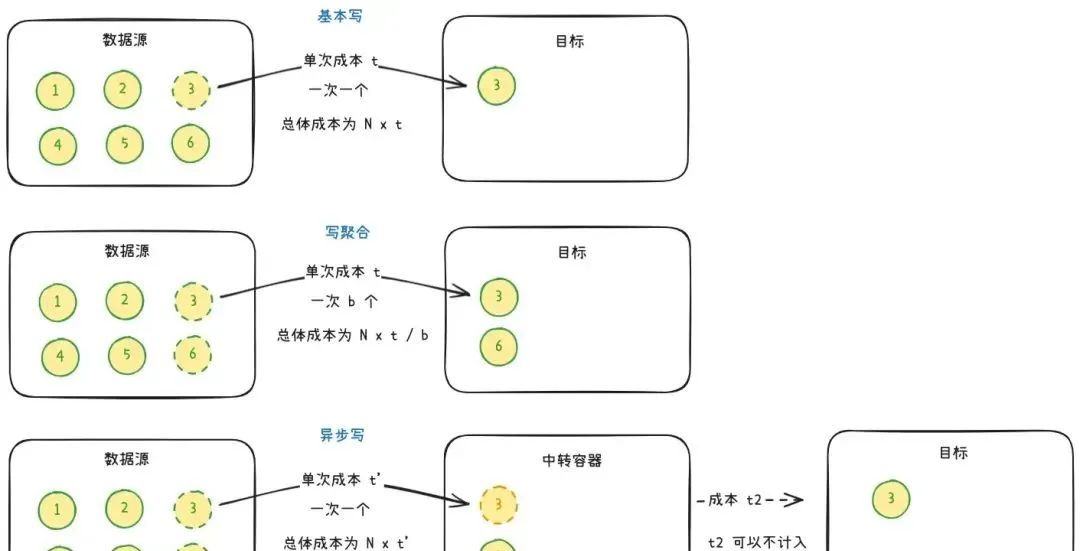
写聚合是分批次写入,单批次数据 b 越多,节约的时间成本也越多,但批次太大也会带来内存和带宽上的开销,需要均衡取舍。同时,对于流式数据源,写聚合需要凑齐一批数据统一操作,实时性不如逐条写入。
异步写是将耗时操作移出操作流程,从数据源角度看,总时间成本有所降低。但从系统的角度看,时间成本 = N x (t' + t2),t' 与 t2之和通常大于 t,总时间成本反而有所增加。
异步写的意义在于可以对流量削峰,通过生产者消费者模型,让消费端可以平滑地处理数据。此外,增加消费者数量,也能通过并发处理的方式来缩短 t2,从而提升系统时间成本。
写聚合和异步写可以组合使用,更进一步缩短时间,提升性能。

开启 MySQL 批处理

对于数据库写入操作,最典型的写聚合莫过于批量处理。单次写入的成本包括网络传输的成本和数据库进程写数据的成本,通过批处理,可以节约大量网络传输成本。
MySQL 本身支持一次请求中包含多条 SQL 语句,JDBC 提供对应的批处理 Batch API。
Connection connection = ...;
// PreparedStatement 可以缓存 SQL 语句,避免多次编译,提高 SQL 语句执行性能
PreparedStatement statement = connection.prepareStatement(sql);
connection.setAutoCommit(false); // 关闭自动提交事务,以批为单位执行事务
for (int i = 0; i < batchSize; i++) {
statement.setString(...);
// ...
// 加入当前批次
statement.addBatch();
}
// 统一执行命令
statement.executeBatch();
statement.clearBatch();
connection.commit();
// close 相关主要涉及三个方法:
statement.addbatch(),不立即执行 SQL,将数据添加进当前批,稍后一起执行。
statement.executeBatch(),批量提交 SQL,交给数据库统一执行。
statement.clearBatch(),清空当前批缓存的 SQL,回收内存。
通过多次 addBatch,然后统一executeBatch,这就是 JDBC 提供的批处理方式。
但是,此处有一个坑,必须开启rewriteBatchedStatements=true才能让 JDBC 的 Batch API 生效,否则仍然是以逐条 SQL 的方式执行。对此在 JDBC 连接中添加&rewriteBatchedStatements=true选项即可。
rewriteBatchedStatements用于将包含 INSERT 和 REPLACE 的 SQL 语句合并,比如将多条insert into t1(c1, c2, c3) values (?, ?, ?)语句合并到一条语句中,insert into t1(c1, c2, c3) values (?, ?, ?), (?, ?, ?), ...,通过将多条 SQL 合并为一条 SQL 可以提高效率。但我使用这个选项主要是为了开启批处理,重写只是附带的功能。
另一个需要注意的地方是,MySQL 对单次请求的包大小有限制,注意 batchSize 不要太大导致包体积超过上限。通过max_allowed_packet可以调整包体积上限,具体可以参考官方文档。
开启 MySQL 批处理后,立竿见影,MySQL 写入耗时降到了 9 秒!

内存开销比较稳定,相较于之前并没有增加。
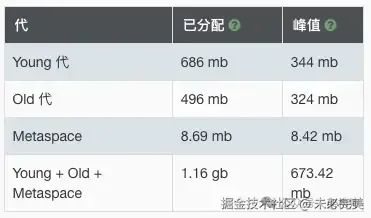
现在的成绩是 12 秒 673 MB,显著的进步!
为什么一定要开启 rewriteBatchedStatements?
答案在 JDBC 代码中。
我是用的 MySQL 驱动为 8.3.0 版本。在com.mysql.cj.jdbc.ClientPreparedStatement类中定义了批处理逻辑。
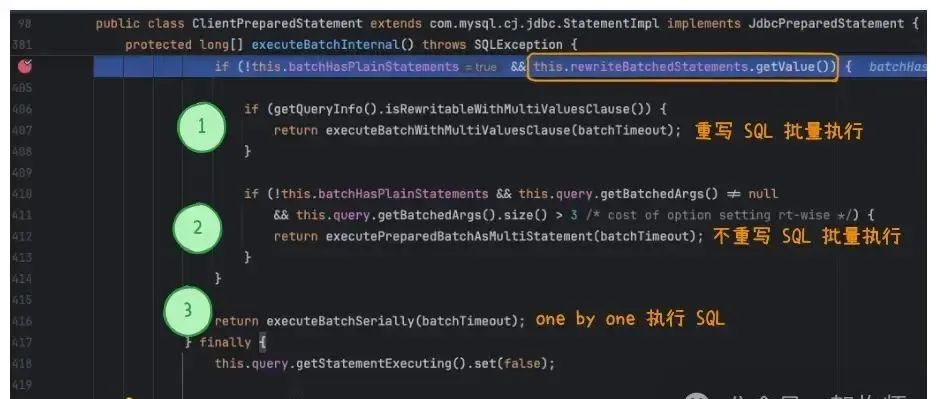
代码中限制了只有开启rewriteBatchedStatements才能使用批处理功能。
重复导入的问题
由于是导入数据的场景,可能遇到需要重新导入的情况。重复导入时,如何处理已经存在的数据,有不同做法。
可以在导入前将目标表的数据删除,然后以新导入数据为准。ETL 流程中的临时表常用这种方式。
可以增加一个步骤,区分出新增数据和更新数据,然后分别执行更新和新增,内部仍然可以批处理。
还可以使用INSERT ... ON DUPLICATE KEY UPDATE语句兼顾更新和新增两种情况,保证操作的幂等性。
INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6)
ON DUPLICATE KEY UPDATE a=VALUES(a), b=VALUES(b), c=VALUES(c);MySQL 还有另一个REPLACE INTO语句,功能相同,特殊之处在于 ORACLE 和 PostgreSQL 也支持 REPLACE INTO,在涉及多种数据库时有利于统一代码。

开启多线程写入

通过开启数据库批处理,我们已经大幅度缩短了耗时,其实已经适合大多数场景的需求了。但还有进一步提升的空间。
通过异步写的方式,可以缩短请求方的等待时间,且可以根据数据量动态调整消费者的数量,这样能在性能和成本之间达到动态均衡。
我使用 Disruptor 并发队列来实现异步写。解析 XML 文件后,将数据入队 Disruptor 提供的队列,并开启了 4 个消费者进行消费。
var disruptor = new Disruptor<>(
ProductEvent::new,
16384,
DaemonThreadFactory.INSTANCE,
ProducerType.SINGLE,
new BusySpinWaitStrategy());
var consumers = new SaveDbHandler[4];
for (int i = 0; i < consumers.length; i++) {
consumers[i] = new SaveDbHandler(i, consumers.length, shutdownLatch);
}
disruptor.handleEventsWith(new SimpleBatchRewindStrategy(), consumers)
.then(new ClearingEventHandler());
var ringBuffer = disruptor.start();
// 通过 ringBuffer 队列发布数据
for (var it = document.getRootElement().elementIterator(); it.hasNext(); ) {
var element = it.next();
if (!StringUtils.hasText(element.elementTextTrim("id"))) {
continue;
}
var product = ObjectMapper.buildProduct(element);
ringBuffer.publishEvent((event, sequence, buffer) -> event.setProduct(product));}Disruptor 4.0 之后,去掉了 worker 相关的 API,一切统一以EventHandler来处理。同一数据会被注册到Disruptor的所有EventHandler获取到,类似广播模式。而我们的场景需要的是争抢模式,为了保证每个消费者只消费自己相关的数据,可以在获取数据时进行判断。
具体做法是为每个EventHandler分配一个从 0 开始的序号,每条数据带有一个序号,EventHandler通过对序号取模的方式判断是否应该丢弃。
@Override
public void onEvent(ProductEvent event, long sequence, boolean endOfBatch) throws Exception, RewindableException {
if (sequence % numberOfConsumers != ordinal) {
return;
}
try {
// 设置 statement
// ...
statement.addBatch();
if (endOfBatch) {
statement.executeBatch();
statement.clearBatch();
connection.commit();
}
} catch (SQLException e) {
log.error("[{}] handler error, sequence: {}, endOfBatch:{}", ordinal, sequence, endOfBatch, e);
try {
if (connection != null)
connection.rollback();
} catch (SQLException se2) {
log.error("rollback error", se2);
}
}}Disruptor 4.0 还提供了重新消费的功能。在 Disruptor 内部会对数据分批次,同一批次内的数据支持从头开始重新消费。具体做法是实现RewindableEventHandler接口,在需要重新消费时,抛出RewindableException。
对于批量写数据库的场景,rewind 机制可以用在数据库出现异常的情况,先回滚事务,然后抛出RewindableException通知 Disruptor 重传当前批次数据。
通过开启多线程异步写入,将耗时从 12 秒降到了 4.5 秒。虽然不如批处理的效果明显,但以 12 秒为基准,也缩短了 60% 的时间。
内存方面,由于开启了多线程,每个线程会带来一定的开销,因此峰值内存提升了不少,能否接受就看具体需求场景。
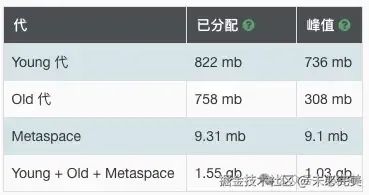
最终成绩,4 秒 1 GB。

进一步的优化方向

优化 XML 解析
我测试的数据量并不大,解析 XML 文件并不是瓶颈。大数据量时,存在一个性能隐患:大量对象带来的内存压力。解决方案也并不复杂,可以采用事件模型来解析 XML 文件。SAX 解析器基于事件驱动,逐行读取 XML,解析为多种事件,开发者可以实现事件处理接口来处理事件。
SAX 的优点在于内存消耗小,适合处理大型 XML 文档。我们可以将事件处理接口作为生产者,获取 Element 并交给 Disruptor 分发。事件模型下每个事件对象存活周期很短,可以节约内存开销。
优化 Disruptor 内存占用
Disruptor 的 batchSize 越大,理论上性能也越高。我将示例代码的 batchSize 从 1024 提升到 16384 后,整体时间能缩短到 3.5 秒。但作为利刃的另一面,大 batch 会导致 Ring Buffer 的体积增大。
Ring Buffer 的大小 = Event 对象内存占用 x batchSize。Disruptor 提供了提前释放内存来优化内存使用的例子:Early release。
优化 MySQL 的写性能
MySQL 的写入优化是一个比较复杂的问题,涉及因素很多。通常的做法是增大log_buffer(innodb-log-buffer-size)、Buffer Pool(innodb_buffer_pool_size),调整innodb_flush_log_at_trx_commit来控制日志刷盘时机。
这次批量写入优化实践的经历对我而言挺有成就感,因此分享出来。我了解了 JDBC Batch 的概念,也学习了 Disruptor 的使用。这种优化方案比较适合批量导入数据的场景。按照惯例,相关代码已经上传 GitHub。
https://github.com/xioshe/xml-to-mysql
— 完 —
如喜欢本文,请点击右上角,把文章分享到朋友圈
· END ·
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描上方二维码关注一下,您的支持是我坚持写作最大的动力。
求一键三连点赞、转发、在看

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









