







LMAX Disruptor 用户手册
LMAX Disruptor是一个高性能线程通信库。它起源于LMAX对高并发,高性能,无锁算法的研究,如今已成长为Exchange基础架构的核心部分。
使用Disruptor
介绍
Disruptor库使用了环形缓冲(ring buffer)作为数据结构,这种异步事件处理架构设计提供了低延迟,高性能的工作队列。
为了理解Disruptor的优点,我们可以将一些容易理解并且相似的地方进行比较。Disruptor对应了Java的阻塞队列( BlockingQueue)。Disruptor 和队列的目的一致,都是为了在同一进程的线程之间传递数据(例如:消息或者事件)。然而,Disruptor有一些关键的功能与队列不同。如下:
- 向消费者组播事件, 消费依赖图.
- 对事件预分配内存.
- 无锁(可选).
核心概念
在我们去理解Disruptor的工作原理之前,我们还定义了一些术语,这些术语在以下的文档和代码中都有用到。对于那些喜欢领域驱动设计(DDD)的人来说,在Disruptor这样的做法很普遍。
- 环形缓冲(Ring Buffer): 环形缓冲通常作为Disruptor的重要知识点。从3.0版本之后,环形缓冲仅作为存储和更新数据(事件)的作用,在一些高级的应用场景中,它甚至可以被其他方式直接替代。
- 序列(Sequence): Disruptor 使用序列作为识别组件位置的方法,每个消费者(事件)都会像Disruptor一样维护一个自己的序列,大多数并发的代码实现都依靠序列值的移动。虽然这种这种做法可以用
AtomicLong替代,但是,两者之间唯一真正的区别是序列还包含了额外的东西,用来防止序列和其他值之间在缓存行中的伪共享问题。 - 序列器(Sequencer): 序列器是Disruptor真正的核心,这个接口有两个实现类(单生产者和多生产者),这个接口是生产者和消费者之间快速正确的传输数据的并发算法。
- 序列屏障(Sequence Barrier):序列器生产一个序列屏障,里面包含了序列器对已发布数据的引用和所依赖消费者的队列,并且也包含了用来判断是否有数据需要被消费的逻辑。
- 等待策略(Wait Strategy):等待策略决定了消费者如何等待事件的处理策略,具体可以在下文‘可选无锁’部分找到。
事件(Event):生产者到消费者传递的数据单位叫做事件。事件不是Disruptor的一种类型,而是由用户定义的一种对象结构。- 事件处理器(Event Processor): 事件处理器用于RingBuffer消费时的数据协调控制,并处理Disruptor事件的功能。有一个BatchEventProcessor 对象,实现了EventHandler接口,里面描述了事件循环的实现方式。
- 事件执行者(Event Handler):一个用户实现了Disruptor 消费者接口的对象。(消费者应实现这个)
- 生产者(Producer):指用户使用自己的代码调用Disruptor将事件发布。Disruptor没有强制用户对事件的发布方式使用必需的代码。
为了将元素放入上下文中,下面展示了LMAX 如何使用Disruptor构建高性能核心服务数据交换的样例。
博客防伪码-Y*$bB#ygo2hI3Anh-2022年2月13日23:05:32
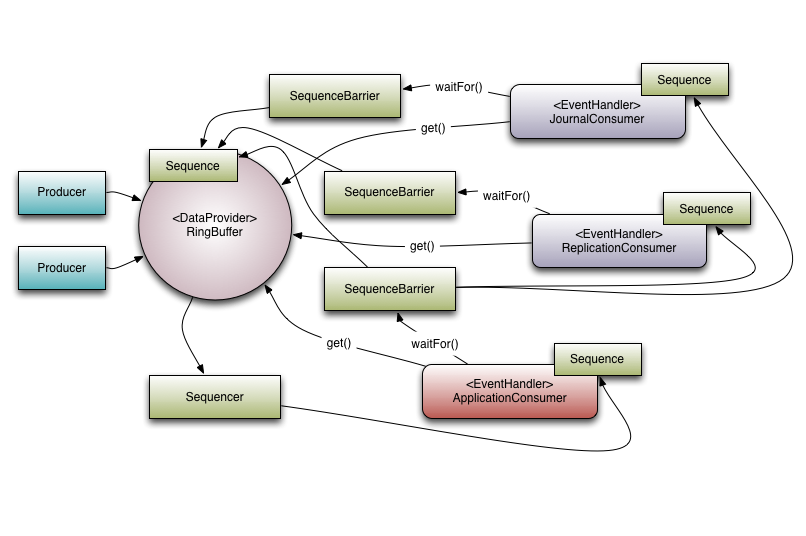
理解1. Disruptor 和一些依赖的消费者之间的关系.
组播事件(Multicast Events)
这是队列和Disruptor之间最大的区别。
当你有多个消费者监听了Disruptor时,它可以将所有事件发布给所有消费者,而队列只能将一个数据发送给一个消费者,当你需要在相同的数据上独立多个并行的数据处理(对一个数据使用多个消费者)时,你可以用到Disruptor的这个特性。
使用案例
LMAX 的标准样例-‘我们有三个操作’:
日志写入:将日志数据持久化到日志文件中
复制:将数据发送到其他机器上并确保数据已被远程接收并存储副本
业务逻辑:真正的处理工作
在上文理解1中可以看到有3个
EventHandlers 的事件监听,分别是 (JournalConsumer,ReplicationConsumer与ApplicationConsumer)。每个消费者都会收到来自Disruptor 可用的相同消息(顺序相同)。这样允许多个消费者对同一数据进行并行同时操作。
消费者依赖图(Consumer Dependency Graph)
在多消费者并行处理的实际应用场景中,需要对各个消费者之间进行协调。回到上面的样例,在写入日志和复制数据完成前,不能进行业务逻辑处理。我们把这种概念叫做控制‘gating’(或者说,这种行为是控制的一种特征)。
“控制” 发生在两个地方:
- 首先,我们需要确保生产者的数量少于消费者。这是通过调用
RingBuffer.addGatingConsumers()方法将消费者加入Disruptor的。 - 其次,上面是通过构造一个序列屏障来实现的,而构造这个序列屏障必须先完成处理前序列的工作。
关于理解1有3个消费者监听了环状缓冲区Ring Buffer。而在这个样例中也可以用这个依赖关系图来表示。
ApplicationConsumer 依赖于JournalConsumer 和ReplicationConsumer,意思是:JournalConsumer 和ReplicationConsumer 都是并行运行,互不影响,从ApplicationConsumer's 的序列屏障到JournalConsumer 和ReplicationConsumer的连接可以看出他们的依赖关系。(ApplicationConsumer的序列屏障连接了JournalConsumer 和ReplicationConsumer的序列)
同样需要注意的是序列器和下游消费者之间的关系。它其中的一个作用是防止生产者发布的数据不会污染环形缓冲区(防止顺序错乱)。为了做到这一点,下游消费者的序列都必须小于环形缓冲区的序列与环形缓冲区的最大值。(这部分由环形缓冲区的数据结构所决定)。
然而,通过使用依赖关系图来解决这个问题可能更好。因为ApplicationConsumer's 序列肯定不会大于JournalConsumer 和ReplicationConsumer 的序列(依赖关系确保此条件成立),所以只需要查看ApplicationConsumer 的序列器就可以了。在大多数的场景中,序列器只需要知道消费者树种的叶子节点就可以了。
事件预分配(Event Pre-allocation)
Disruptor的目标之一就是为了在低延迟环境下使用,在低延迟系统中,有必要减少或移除内存分配,提高性能。而在Java环境中,目的就是为了减少JVM的GC次数来提高性能。
为了支持这一点,用户能够预分配Disruptor事件存储所需要的内存,在构造过程中,Disruptor的环形缓冲区为每个实体提供了用户可以调用的事件工厂EventFactory,当向 Disruptor 发布新数据时,用户可以通过API获取构造的对象,以便他们可以调用方法或更新该存储对象上的字段,只要操作正确,Disruptor会保证并发的安全。
无锁(可选)(Optionally Lock-free)
由于Disruptor在设计时需要达到关键的低延时要求,所以在实现过程中广泛使用了无锁算法。所有内存可见性与正确性保证都是通过内存屏障的‘和/或 对两个值比较并交换’操作实现。
在Disruptor中,只有一个地方真正意义上使用到了锁,即BlockingWaitStrategy。为了在等待新事件到达的时候可以停止消费线程,这里使用了一个状态参数来达到它的目的。在大多数低延迟系统中使用了busy-wait 避免使用状态参数导致可能的抖动,然鹅,大量系统的busy-wait操作会导致系统性能的显著下降,尤其在一些对CPU资源需求比较高的场景中,例如在虚拟环境中的web服务器。
准备开始
获取Disruptor
可以从 Maven Central 获取到jar文件,并且可以将他集成到依赖管理系统中。
基础-生产和消费
我们使用非常简单的样例作为你了解Disruptor的第一步。我们这里将一个long值从生产者发送给消费者,然后消费者将这个值打印出来。
在Disruptor中,实现发布者和消费者有几种方法,虽然他们本质上是相同的,但还是有些细微差别,详见以下样例。
首先,我们定义了一个携带了数据的事件Event:
样例:LongEvent
public class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
}为了让Disruptor可以给我们预先分配这些事件,我们需要事件工厂EventFactory来构造它,这可以是一个方法引用,例如LongEvent::new这种写法,或者是一个对EventFactory 接口的一个明确实现:
样例: LongEventFactory
public class LongEventFactory implements EventFactory<LongEvent>
{
public LongEvent newInstance()
{
return new LongEvent();
}
}一旦我们定义了时间,我们需要创建一个消费者来处理这个事件。在下面的样例中,我们需要创建一个事件处理 EventHandler ,它会将收到的值输出到控制台。
样例:LongEventHandler
public class LongEventHandler implements EventHandler<LongEvent>
{
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("Event: " + event);
}
}最后,我们需要一个事件的来源。为了简单起见,我们假设数据来自于某种IO设备,例如以网络,文件或文件中的ByteBuffer。
发布
使用 Lambdas
Disruptor从3.0版本后开始,就可以使用Lambda风格的API编写发布者了。因为它比其他方法更简单,所以这是实现发布者的首选方法。
使用lambda编写发布者
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith((event, sequence, endOfBatch) ->
System.out.println("Event: " + event));
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);
Thread.sleep(1000);
}
}
}| 1 | 指定环形缓冲区ring buffer的大小必须为2的幂次方(为了便于计算机处理,位操作index & ( size - 1 )就能够得到实际的index) |
| 2 | 构造一个Disruptor |
| 3 | 连接处理方法handler |
| 4 | 启动Disruptor,运行所有线程 |
| 5 | 从Disruptor 获取ring buffer用于发布 |
| 注意,用于publishEvent()的lambda仅引用传入的参数。如果我们将代码写成这样: 样例 lambda 这会以一个lambda的方式创建, 意味着它将会需要实例化一个对象去保存 |
考虑到方法的引用可以代替匿名lambda,可以参照如下方法重写该样例:
使用引用方式的样例
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void handleEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println(event);
}
public static void translate(LongEvent event, long sequence, ByteBuffer buffer)
{
event.set(buffer.getLong(0));
}
public static void main(String[] args) throws Exception
{
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith(LongEventMain::handleEvent);
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
ringBuffer.publishEvent(LongEventMain::translate, bb);
Thread.sleep(1000);
}
}
}使用转换器 translator
在3.0版本之前,发布消息的是通过Event Publisher或Event Translator接口实现的:
样例 LongEventProducer
import com.lmax.disruptor.EventTranslatorOneArg;
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
public class LongEventProducer
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
private static final EventTranslatorOneArg<LongEvent, ByteBuffer> TRANSLATOR =
new EventTranslatorOneArg<LongEvent, ByteBuffer>()
{
public void translateTo(LongEvent event, long sequence, ByteBuffer bb)
{
event.set(bb.getLong(0));
}
};
public void onData(ByteBuffer bb)
{
ringBuffer.publishEvent(TRANSLATOR, bb);
}
}这些方法使用了一些在使用lambda时明确不需要的额外类(例如handler,translator),这样做是为了解耦合,方便将各部分代码放入单独的类做单元测试。
Disruptor提供了许多不同的接口,(EventTranslator, EventTranslatorOneArg, EventTranslatorTwoArg, 等等.) 他们可以作为translatrs实现。这是为了将转换器表示为静态类和lambda (见 上面). 转换器方法的参数通过 Ring Buffer 的调用传递给另一个转换器。
使用旧版API发布
我们可以使用一种更加“原始”的方法:
样例 旧版 LongEventProducer
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.examples.longevent.LongEvent;
import java.nio.ByteBuffer;
public class LongEventProducer
{
private final RingBuffer<LongEvent> ringBuffer;
public LongEventProducer(RingBuffer<LongEvent> ringBuffer)
{
this.ringBuffer = ringBuffer;
}
public void onData(ByteBuffer bb)
{
long sequence = ringBuffer.next();
try
{
LongEvent event = ringBuffer.get(sequence);
event.set(bb.getLong(0));
}
finally
{
ringBuffer.publish(sequence);
}
}
}| 1 | 获取下一个序列 |
| 2 | 在Disruptor中获取序列的数据 |
| 3 | 填充数据 |
很显然,使用这种方式发布比使用简单的队列发布复杂的多。这是由于对事件预分配有要求。他需要(在最低级)一种两阶段的信息发布方式,首先在环形缓冲区中申请一个槽位,再将数据发布上去,这两个阶段。
它需要将发布的代码包含在
try/finally块中.如果我们在环形缓冲区中申请(调用
RingBuffer#next())了一个槽位,那我们就必须将这个序列发布出去。如果不这样做,将会导致Disruptor异常。另外,在多生产者情况下,这样还会导致数据无法消费,必须通过重启Disruptor恢复。所以,我们推荐你使用lambda或
EventTranslatorAPI来发布消息。
最后一步是将整个东西连接在一起,虽然可以手动连接每个组件,但是我们不推荐这么做,因为我们有DSL来解决这个问题。
可以使用DSL满足大部分业务场景,但仍有小部分复杂的情况无法通过DLS实现。
使用旧样例 LongEventProducer
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.examples.longevent.LongEvent;
import com.lmax.disruptor.examples.longevent.LongEventFactory;
import com.lmax.disruptor.examples.longevent.LongEventHandler;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
public class LongEventMain
{
public static void main(String[] args) throws Exception
{
LongEventFactory factory = new LongEventFactory();
int bufferSize = 1024;
Disruptor<LongEvent> disruptor =
new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);
disruptor.handleEventsWith(new LongEventHandler());
disruptor.start();
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
LongEventProducer producer = new LongEventProducer(ringBuffer);
ByteBuffer bb = ByteBuffer.allocate(8);
for (long l = 0; true; l++)
{
bb.putLong(0, l);
producer.onData(bb);
Thread.sleep(1000);
}
}
}基本调优方法
上述的方法可以满足广泛的业务场景中的使用,然鹅,我们还有许多调优的方法改进它的性能。
调优的两个基本方法:
- 单生产者与多生产者
- 更换等待策略.
这两个选项都是在构造Disruptor时设置的:
调优Disruptor
public class LongEventMain
{
public static void main(final String[] args)
{
//.....
Disruptor<LongEvent> disruptor = new Disruptor(
factory,
bufferSize,
DaemonThreadFactory.INSTANCE,
ProducerType.SINGLE,
new BlockingWaitStrategy()
);
//.....
}
}| 1 | 使用 使用 |
| 2 | 设置所需的等待策略 |
单vs多生产者
在并发系统中改进性能最好的方式是坚持单一写入原则,这同样适用于Disruptor。如果你只需要单一线程生产数据的情况下,你可以利用这一点来获得额外的性能提升。
为了说明通过这种技术可以带来多少性能提升,我们可以在一对一性能测试中更改生产者类型。(测试于i7 Sandy Bridge MacBook Air)
| 表 1. 多生产者 | |
| Run 0 | Disruptor=26,553,372 ops/sec |
| Run 1 | Disruptor=28,727,377 ops/sec |
| Run 2 | Disruptor=29,806,259 ops/sec |
| Run 3 | Disruptor=29,717,682 ops/sec |
| Run 4 | Disruptor=28,818,443 ops/sec |
| Run 5 | Disruptor=29,103,608 ops/sec |
| Run 6 | Disruptor=29,239,766 ops/sec |
| 表 2. 单生产者 | |
| Run 0 | Disruptor=89,365,504 ops/sec |
| Run 1 | Disruptor=77,579,519 ops/sec |
| Run 2 | Disruptor=78,678,206 ops/sec |
| Run 3 | Disruptor=80,840,743 ops/sec |
| Run 4 | Disruptor=81,037,277 ops/sec |
| Run 5 | Disruptor=81,168,831 ops/sec |
| Run 6 | Disruptor=81,699,346 ops/sec |
其他等待策略
默认的等待策略是阻塞等待策略(BlockingWaitStrategy)。BlockingWaitStrategy 的内部使用了一个典型的锁和一个条件变量去处理线程唤醒。BlockingWaitStrategy 是可用的等待策略中最慢的, 但是在CPU使用率比较保守,并且会在各种环境下部署后提供最一致的情况。
根据要部署的系统环境情况再选择不同的等待策略是提高性能的有效方法:
等待策略名按照(按照CPU主观命名)
- 睡眠等待策略SleepingWaitStrategy →
和 BlockingWaitStrategy 类似, SleepingWaitStrategy 也尝试使用一个简单的忙等待循环来控制CPU的使用率,不同的地方在于:SleepingWaitStrategy 再循环中调用了 LockSupport.parkNanos(1)方法,在典型的Linux系统中,这样会导致线程睡眠大约60us。
这样做的好处是生产者线程不需要增加计数器,也不需要传递条件变量。然而,这样做会导致生产者和消费者传输数据的延迟比较感人。
对数据延迟不是很敏感并且希望对生产线程影响较小的情况下是它最佳的使用场景。比如异步的日志记录场景。
- 让步等待策略YieldingWaitStrategy →
YieldingWaitStrategy 是两个可用于低延迟系统中的等待策略之一,他是为了牺牲CPU性能来改善低延迟数据传输而设计。
YieldingWaitStrategy 会产生自旋,当序列递增到适当值的时候,循环体内部将调用Thread#yield() 方法以允许其他排队的线程运行。
当你需要非常高性能的队列并且 EventHandler 的数量低于CPU逻辑核心(包含超线程)的数量的时候,推荐你使用这个等待策略。(防止线程过多频繁切换造成的损失)
- 自旋等待策略BusySpinWaitStrategy →
BusySpinWaitStrategy 是一个高性能的等待策略,和YieldingWaitStrategy一样,它可以应用于低延时系统中,但是这个等待策略对部署环境有相比其他几种等待策略中最高的要求。 it can be used in low-latency systems, but puts the highest constraints on the deployment environment.
只有当EventHandler 的线程数量低于CPU物理核心数量时,才能用当前等待策略,在这种情况下,超线程应被关闭。
从环形缓冲中清理对象
当通过Disruptor传递数据时,对象的寿命可能长于预期,为了避免这种情况,我们需要在数据处理后清理Event事件数据。
如果你的事件处理是单线程的,那你数据处理后将值清空就可以了,但如果你的是事件处理链,那你需要在数据处理完成后使用一个特定的程序清理数据。
样例ObjectEvent
class ObjectEvent<T>
{
T val;
void clear()
{
val = null;
}
}样例 ClearingEventHandler
import com.lmax.disruptor.EventHandler;
public class ClearingEventHandler<T> implements EventHandler<ObjectEvent<T>>
{
public void onEvent(ObjectEvent<T> event, long sequence, boolean endOfBatch)
{
event.clear();
}
}如果这里没有调用
clear()方法将导致与事件关联的对象一直存在,直到它被覆盖。这种情况只会在环状缓冲区环绕一周重新开始的时候发生。
样例 使用 ClearingEventHandler
public static void main(String[] args)
{
Disruptor<ObjectEvent<String>> disruptor = new Disruptor<>(
() -> new ObjectEvent<>(), BUFFER_SIZE, DaemonThreadFactory.INSTANCE);
disruptor
.handleEventsWith(new ProcessingEventHandler())
.then(new ClearingEventHandler());
}高级技术
大数据处理
"更早版本"的样例
public class EarlyReleaseHandler implements EventHandler<LongEvent>
{
private Sequence sequenceCallback;
private int batchRemaining = 20;
@Override
public void setSequenceCallback(final Sequence sequenceCallback)
{
this.sequenceCallback = sequenceCallback;
}
@Override
public void onEvent(final LongEvent event, final long sequence, final boolean endOfBatch)
{
processEvent(event);
boolean logicalChunkOfWorkComplete = isLogicalChunkOfWorkComplete();
if (logicalChunkOfWorkComplete)
{
sequenceCallback.set(sequence);
}
batchRemaining = logicalChunkOfWorkComplete || endOfBatch ? 20 : batchRemaining;
}
private boolean isLogicalChunkOfWorkComplete()
{
// Ret true or false based on whatever criteria is required for the smaller
// chunk. If this is doing I/O, it may be after flushing/syncing to disk
// or at the end of DB batch+commit.
// Or it could simply be working off a smaller batch size.
return --batchRemaining == -1;
}
private void processEvent(final LongEvent event)
{
// Do processing
}
}设计与实现
- 单生产者算法
- 多生产者算法
已知问题
- 在32位Linux系统上
LockSupport.parkNanos() 方法代价较大,因此不建议使用 SleepingWaitStrategy.
内容回溯
特性
当使用BatchEventProcessor 去处理事件时,这里有一个可用的功能,可以让它从批量回退(Batch Rewind)的异常中中恢复。
如果在处理可恢复的事件时发生了错误,用户可以抛出RewindableException异常。这将会调用BatchRewindStrategy (而不是通常所使用的ExceptionHandler)来决定序列号是否应该回滚到要重新尝试处理事件的开头,或重新抛出异常并让ExceptionHandler处理。
例如:
当使用SimpleBatchRewindStrategy 时,BatchEventProcessor 收到一批150 → 155的数据,但是在153的时候产生了一个问题(抛出了RewindableException),事件处理看起来将会像下面这样….
150, 151, 152, 153(失败-> 回退), 150, 151, 152, 153(此时成功), 154, 155
默认的批量回退策略(BatchRewindStrategy)是 简单批量回退策略(SimpleBatchRewindStrategy) 但是,也有不同的策略提供给批量事件处理 BatchEventProcessor 使用,像这样设置…
batchEventProcessor.setRewindStrategy(batchRewindStrategy);
使用案例
当批量处理数据库事务时也非常方便。只需要当开始一个批处理时启动一个事务,然后将事件作为语句处理,当结束时再提交事务。
如果一切正常,那就是这样...
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> insert a row;
Event 3 -> insert a row;
Batch end -> COMMIT;
如果没有用批量回退发生异常时,就是这样...
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> DATABASE has a blip and can not commit
Throw error -> ROLLBACK;
User needs to explcitily reattempt the batch or choose to abandon the batch
如果用了批量回退发生异常时,就是这样...
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> DATABASE has a blip and can not insert
Throw RewindableException -> ROLLBACK;
Batch start -> START TRANSACTION;
Event 1 -> insert a row;
Event 2 -> insert a row;
Event 3 -> insert a row;
Batch end -> COMMIT;
1. 在低延迟 C/C++ 系统中,由于内存分配器上的抢占,所以在大量内存分配的时候也存在问题。
















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











