







我们经常使用搜索引擎,比如在百度搜索java会出现如下结果,结果中与关键字匹配的地方是显示与其他内容区别开来。
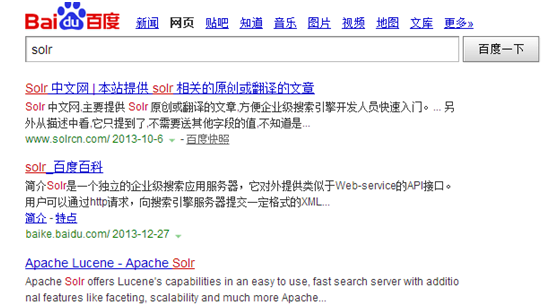
solr默认已经配置了hightlight组件(详见SOLR_HOME/conf/solrconfig.xml)。
通常我们只需要这样请求:
http://localhost:8983/solr/collection1/select?q=%E4%B8%AD%E5%9B%BD&start=0&rows=1&fl=content+path+&wt=xml&indent=true&h1=true&h1.fl=content
可以看到比一般的请求的请求多了两个参数“h1=true”和"h1.fl=content"是告诉sor对name字段进行高亮显示(如果你想对多个字段进行高亮,可以继续添加字段,字段间用逗号隔开,如“h1.fl=name,name2,name3”)。高亮内容与关键字匹配的地方,默认将会被“<em>”和“</em>”包围。高亮内容与关键匹配的地方,默认将会被“<em>”和“</em>”包围。还可以使用h1.simple.pre和“h1.simple.post”参数设置前后标签。
使用SolrJ方法基本一样也是设置这些参数,只不过是SolrJ封装起来了。代码如下:
SolrQuery query = new SolrQuery();
query.set("q" , "*.*");
query.setHighlight(true); // 开启高亮组件
query.addHighlightField("content") // 高亮字段
query.setHighlightsSimplePre(PRE_TAG); // 标记
query.setHighlightSimplePost(POST_TAG);
QueryResponse rsp = server.query(query);
// ...上面取结果的代码
// 取出高亮结果
if (rsp.getHighlighting() != null) {
if (rsp.getHighlighting().get(id) != null) { // 先通过结果中的ID到高亮集合中取出文档高亮信息
Map<String , List<String>> map = rsp.getHighlighting().get(id); // 取出高亮片段
if (map.get(name) != null) {
for(String s : map.get(name)) {
System.out.println(s);
}
}
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









