







目录
1. 数据库
1.1 数据库的简介
(1) 数据库发展史
目前,MySQL已经成为最为流行的开源关系型数据库,并且一步一步占领商业数据库的市场。Google、Facebook、Yahoo、网易等大公司都在使用 MySQL 数据库,甚至将其作为核心应用的数据库系统。
1979年,天才程序员Monty Widenius 为一个名为 TcX 的小公司打工,并且用 BASIC 设计了一个报表工具。没过多久,Monty 又将此工具用 C 语言进行了重写并移植到了UNIX 平台。当时这只是一个很底层的且仅面向报表的存储引擎,名叫Unireg。
1990 年,TcX 公司的客户开始要求为他的API提供SQL支持。当时有人提议直接使用商用数据库,但是Monty觉得商用数据库的速度难以满足客户的需求。于是他借助于mSQL的代码,将它集成到自己的存储引擎中。令人失望的是,效果并不太令人满意。于是Monty决定重写一个 SQL 支持。
1996 年,MySQL 1.0发布,它只面向一小拨人,相当于内部发布。到了 1996 年 10 月,MySQL 3.11.1发布(MySQL没有2.x 版本),最开始只提供 Solaris 下的二进制版本。一个月后,Linux 版本出现了。
(2) 数据库定义
数据库(Database, DB)是将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合。其中,用来管理数据库的计算机系统称为数据库管理系统(Database Management System, DBMS)。
(3) 数据库管理系统的分类
数据库管理系统主要通过数据的保存格式来进行分类的,主要分为5种类型。
关系数据库是目前应用最广泛的数据库。和Excel一样,它也是采用行和列的二维表来管理数据。同时,它还使用专门的SQL(Structured Query Language, 结构查询语言)对数据进行操作。关系数据库的计算机管理系统称为关系数据库管理系统。目前,比较具有代表性的关系数据库管理系统有以下5种:
- Oracle Database : 甲骨文公司
- SQL Server : 微软公司
- PostgreSQL : 开源
- DB2 : IBM公司
- MySQL : 开源
由于MySQL是开源免费的,下面我们将主要研究MySQL数据管理系统。
(4) MySQL客户端与服务器
为了更好地解释MySQL客户端和服务器之间的关系,我们以微信为例。微信是由客户端程序(简称客户端)和服务器程序(简称服务器)组成。微信的客户端有着我们唯一的微信号,腾讯机房有着运行着的微信服务器。平时在微信上的各种骚操作,其实是使用微信客户端与服务器在交流。

客户端是指向服务器发送请求的程序(软件),或者是安装了该程序的设备(计算机)。关系数据库管理系统是一种数据库服务器,它能从保存在硬盘上的数据库种读取数据并返回。换而言之,客户端就是委托方,服务器就是受托方,两者的关系就是受托方执行委托方发出的指令。
1.2 搭建MySQL环境




















2. SQL语言
2.1 SQL的概述
SQL是操作关系数据库的语言,它不但可以进行数据查询,而且可以进行数据插入和删除等操作。SQL语句是用关键字、列名和表名组成的一条语句来描述操作内容。其中,关键字都是事先定义好的。根据指令种类的不同,SQL语句可以分为以下三类:
- 数据定义语言(Data Definition Language, DDL) 用来创建、删除和修改数据库和表。
CREATE # 创建数据库和表
DROP # 删除数据库和表
ALTER # 修改数据库和表
- 数据操作语言(Data Manipulation Language, DML) 用来查询或者改变表中的记录。
SELECT # 查询表中的数据
INSERT # 向表中插入数据
UPDATE # 更新表中的数据
DELETE # 删除表中的数据
- 数据控制语言(Data Control Language, DCL) 用来确认或取消对数据进行的更改。除此之外,更改用户对数据库的操作权限。
COMMIT # 确认对数据库中的数据进行更改
ROLLBACK # 取消对数据库中的数据进行更改
GRANT # 赋予用户操作权限
REVOKE # 取消用户操作权限
2.2 启动MySQL客户端
在成功启动MySQL服务器之后,我们就可以启动MySQL客户端来连接这个服务器。下面这些命令均在DOS命令窗口进行的。
Windows用户启动MySQL客户端方式:
第一步:在键盘上同时按住win + R键;
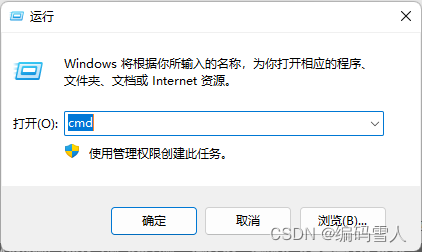
第二步:输入cmd,进入DOS命令窗口。

第三步:使用下面命令启动MySQL客户端。
mysql -u用户名 -p密码 # 登录
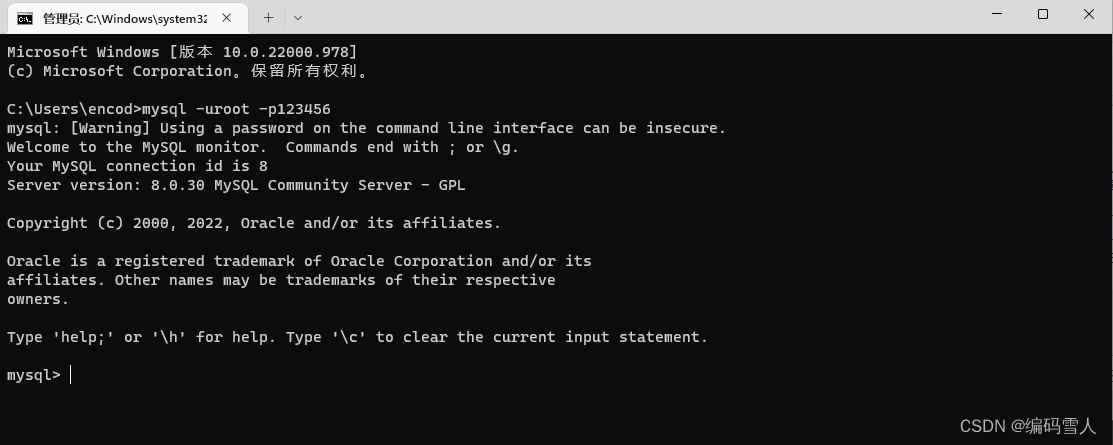
账户和密码都是安装时设置的账号和密码。
exit # 退出客户端
2.3 SQL语句书写规则
俗话说无规矩无以成方圆,这句话也可以用到SQL语句的书写上。下面是一些SQL语句的书写规则。
- SQL语句要以分号结尾;
- 数据库名、表名、列名必须以英文字母、数字、下划线组成;
- SQL语句不区分大小写(注意:关键字用大写,表名的首字母大写,其余用小写);
- 单词要用英文输入法的空格来区分;
- 字符串书写格式:
当SQL语句中有字符串时,用单引号括起来。例如,‘张三’;
当SQL语句中有日期时,用单引号括起来。例如,‘2022-10-3’。
2.4 注释
单行注释: #注释内容(MySQL特色)
单行注释: -- 注释内容
多行注释: /*注释内容*/
2.5 数据库的操作
- 创建数据库
- 查看数据库
- 删除数据库
- 修改数据库
CREATE DATABASE mydb1; # 创建数据库
SHOW DATABASES; # 查看数据库
SHOW CREATE DATABASE mydb1; # 显示数据库创建语句
DROP DATABASE mydb1; # 删除数据库
ALTER DATABASE mydb1 CHARACTER SET gbk; # 修改数据库字符集为gbk
2.6 表的操作
- 选择数据库
- 创建表
| 常用类型 | 内容 |
| 字符串类型 | varchar(可变字符串), char(固定字符串) |
| 大数据类型 | blob(存储图片), text(存储文本) |
| 数值类型 | tinyint, smallint, int, bigint, float, double |
| 逻辑类型 | bit(0,1) |
| 日期类型 | date(年、月、日), time(时、分、秒), datetime(年月日时分秒), timestamp |
- 查表
- 修改表
- 删除表
USE mydb1; # 选择数据库
SELECT DATABASE(); # 查看当前使用的数据库
CREATE TABLE employee(
id INT,
name VARCHAR(20),
gender CHAR(2),
birthday DATE,
entry_date DATE,
job VARCHAR(20),
salary FLOAT,
resume TEXT
); # 创建表
// 查看
SHOW TABLES; # 显示表
DESC employee; # 查看表结构
SHOW COLUMNS FROM employee; # 查看表结构
DESCRIBE employee; # 查看表结构
SHOW CREATE TABLE employee; # 既查看表的创建语句,又能查看表的字符集
// 修改
ALTER TABLE employee ADD image BLOB; # 添加image字段
ALTER TABLE employee MODIFY job VARCHAR(100); # 修改字段类型
ALTER TABLE employee CHANGE name user_name VARCHAR(15); # 既能修改字段名称,又能修改字段类型。
ALTER TABLE employee DROP gender; # 删除字段
ALTER TABLE employee CHARACHER SET utf8; # 修改表的字符集
RENAME TABLE employee TO user1; # 修改表名
// 删除
DROP TABLE user1; # 删除表



2.6.1 表的约束
1. 主键约束
1.1 创建表时添加主键约束
create table employee2(
id int primary key,
name varchar(20),
salary double
); // 只带主键的表
create table employee3(
id int primary key auto_increment,
name varchar(20),
salary double
); // 既带主键,又带自动增长的表
1.2 删除主键约束
第一种情况:
(1) 删除主键的唯一性约束
alter table employee2 drop primary key;
(2) 删除主键的非空约束
alter table employee2 modify id int null; // 或者
alter table employee2 change id id int;
第二种情况:
(1) 删除自增长约束
alter table employee3 modify id int; // 或者
alter table employee3 modify id id int;
(2) 删除主键的唯一性约束
alter table employee3 drop primary key;
(3) 删除主键的非空约束
alter table employee3 modify id int null; // (2)与(3)不演示
alter table employee3 change id id int;
1.3 创建表后添加主键约束
(1) 在原有的字段上添加主键约束
alter table employee2 change id id int primary key; // 或者
alter table employee2 modify id int primary key;
(2) 添加新的主键约束字段
alter table employee2 add num int primary key; // 添加新的主键字段
alter table employee2 modify num int first; // 将主键字段升至为第一字段
alter table employee2 modify num int after id; // 将主键字段放置在id字段之后
1.4 自动增长
(1) 添加
alter table employee2 modify num int auto_increment;
(2) 删除
alter table employee2 modify num int;
1.5 注意事项
(1) modify与change的差异
(2) 主键非空且唯一
2. 非空约束
2.1 创建表时添加非空约束
create table employee4(
id int primary key auto_increment,
name varchar(30) not null,
age int,
salary float
);
2.2 删除非空约束
alter table employee4 modify name varchar(30) null;
alter table employee4 change name name varchar(30) null;
2.3 创建表后添加非空约束
alter table employee4 modify name varchar(30) not null;
3. 唯一约束
3.1 创建表时添加唯一约束
create table employee5(
id int,
name varchar(20) unique,
age int,
salary double
);
3.2 删除唯一约束
alter table employee5 drop index name;
3.3 创建表后田间唯一约束
alter table employee5 modify name varchar(30) unique;
5. 外键约束









2.7 CRUD操作
CRUD (创建:Create, 读取:Read, 更新:Update, 删除:Delete) 是对于存储的信息可以进行操作的缩写。是一个对四种操作持久化信息的基本操作的助记符. CRUD 通常是指适用于存于数据库或数据存储器上的信息的操作。在实际应用中,我们的重点应该放在查询数据上。
第一步:创建一个表employee1
CREATE TABLE employee1(
id INT,
name VARCHAR(20),
salary FLOAT,
job VARCHAR(20),
age INT
);
第二步:插入数据、更新数据、查询数据和删除数据
1. 插入数据
INSERT INTO employee1 VALUES(1, "张三", 3500, "技工", 35); # 全字段插入数据
INSERT INTO employee1 VALUES(2, "李四", 5000, "组长", 32);
INSERT INTO employee1 VALUES(3, "李刚", 500, "总经理", 23);
INSERT INTO employee1 (id, name, salary) VALUES(4, "黎明", 9000); # 字段插入数据
2. 更新数据
UPDATE employee1 SET salary=50000 WHERE name="李刚"; # 将李刚的工资改为5w
UPDATE employee1 SET job="副经理", age=24 WHERE name="黎明"; # 将黎明的信息补充完整
3. 查询数据
SELECT * FROM employee1; # 查找整张表的数据
SELECT id, name, salary, job FROM employee1; # 查找部分字段数据
SELECT * FROM employee1 WHERE id=3; # 查找李刚数据
4. 删除数据
DELETE FROM employee1 WHERE job="总经理"; # 删除一条数据
DELETE FROM employee1; # 删除全部数据
TRUNCATE employee1; # 删除全部数据 —— 不能搭配where使用




2.8 数据库备份与恢复
1. 备份数据库
语法:
mysqldump -u用户名 -p 数据库名 > 文件名.sql
实例:
mysqldump -u root -p mydb1 > e:/database/mydbq.sql -- e:/database/mydbq.sql为文件路径

2. 恢复数据库
语法1:
mysql -u root -p 数据库名 < 文件名.sql -- 备份后删除库,然后恢复
语法2:
SOURCE 文件名.sql
实例1:
DROP DATABASE mydb1;
CREATE DATABASE mydb1;
mysql -u root -p mydb1 < e:/database/mydbq.sql -- 在dos命令窗口执行
实例2:
DROP DATABASE mydb1;
CREATE DATABASE mydb1;
USE mydb1; -- 注意,很容易犯错
SOURCE e:/database/mydb1;


3. 数据查询
在实际操作中,我们经常使用数据查询操作。换句话说,只要我们掌握了数据查询操作,就意味着我们已经学会了如何使用SQL语句。
3.1 单表查询
3.1.1 查询单个字段
语法:
SELECT 列名 FROM 表名
实例:
SELECT job FROM employee1;

注意:在进行此操作前,需要插入数据。
3.1.2 查询多个字段
语法1:
SELECT 列名1, 列名2 FROM 表名
语法2:
SELECT * FROM 表名 # 查询所有列
实例:
SELECT id, age, job FROM employee1;
SELECT * FROM employee1;

3.1.3 查询记录
语法:
SELECT * FROM 表名 WHERE 条件表达式;
实例:
SELECT * FROM employee1 WHERE name='李刚';

3.1.4 三大运算
(1) 算术运算:可以进行加、减、乘、除
实例:
SELECT name, salary*3 FROM employee1 WHERE name='李刚';

(2) 比较运算:数值比较查询
实例:
SELECT * FROM employee1 WHERE salary>10000;;

(3) 逻辑运算:可以条件查询
实例:
SELECT * FROM employee1 WHERE salary>10000 OR age>30;

(4) 注意事项:
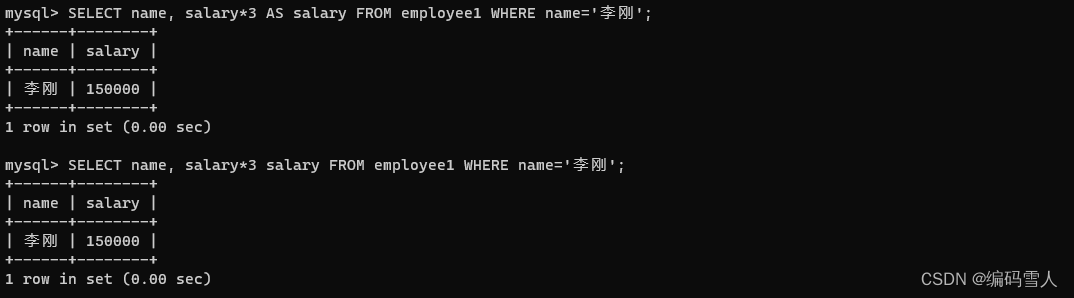
a. 当字段名称较长时,可以使用别名来替代,别名的关键字是AS
实例:
SELECT name, salary*3 AS salary FROM employee1 WHERE name='李刚'; -- 写法一
SELECT name, salary*3 salary FROM employee1 WHERE name='李刚'; --写法二
b. NULL值的四则运算结果
实例:
SELECT NULL/2 value1, NULL+2 value2, NULL*2 value3, NULL-2 value4;

c. 运算符
| >, <, <=, >=, =, <> | 大于, 小于, 小于等于, 大于等于, 等于, 不等于 |
| BETWEEN......AND...... | 在某个范围内 |
| IN(集合) | 指定某个列的多个可能值 |
| IS NULL | 判断是否为空 |
| IFNULL | 替换空值, IFNULL(字段名,0) |
| AND, OR, NOT | 与,或,非 |
3.1.5 排序操作
查询的数据一般会以底层表中的顺序显示(数据最初添加到表中的顺序),如果数据在后期进行更新或者删除,势必会影响到表单的顺序。因此,如果不明确操作的话,就不能得出想要的排序。
语法:
SELECT 列名1, 列名2, 列名3
FROM 表名
ORDER BY 列1排序准则, 列2排序准则, 列3排序准则
实例:
# 第一步:创建表
CREATE TABLE student(
id INT,
name VARCHAR(20),
math DOUBLE,
Chinese DOUBLE,
history DOUBLE
);
# 第二步:添加数据
INSERT INTO student VALUES(null, '张三', 60, 86, 45);
INSERT INTO student VALUES(null, '李四', 75, 79, 60);
INSERT INTO student VALUES(null, '黎明', 22, 90, 98);
INSERT INTO student (id, name, Chinese, math) VALUES(null, '阿三', 44, 80);
# 第三步:排序
SELECT name, history FROM student ORDER BY history ASC;
SELECT name, history FROM student ORDER BY history DESC;
SELECT name, math, Chinese FROM student ORDER BY math DESC, Chinese ASC;
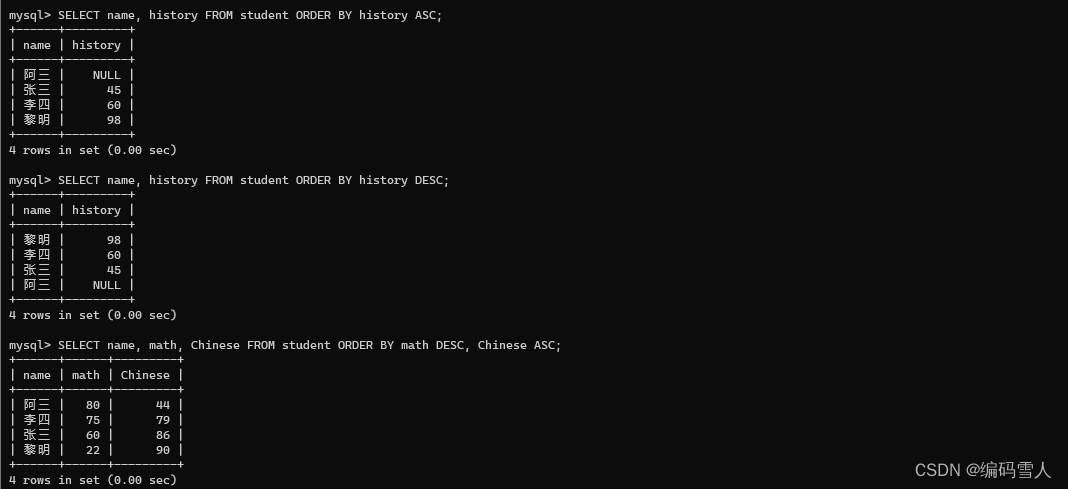
【注意事项】
- ORDER BY子句必须写在SELECT语句的末尾。
- NULL不能使用比较运算符,所以不能对NULL和数字进行排序,也不能与字符串和日期比较大小。因此,使用含 NULL的列作为排序键时,NULL会在结果的开头或者末尾显示。
3.1.6 分组操作
# 第一步:创建表
CREATE TABLE university(
id INT,
name VARCHAR(20),
remark CHAR(2)
);
# 第二步:添加数据
INSERT INTO university VALUES(1, "小木棍", "A");
INSERT INTO university VALUES(2, "张飞", "A");
INSERT INTO university VALUES(3, "小白菜", "B");
INSERT INTO university VALUES(4, "小花", "B");
INSERT INTO university VALUES(5, "小明", "C");
# 第三步:分组
SELECT * FROM university GROUP BY remark;
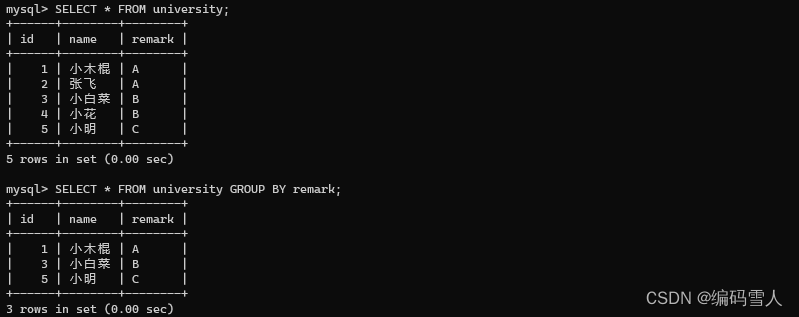
【注意事项】
- GROUP BY只能写在SELECT子句中;
- GROUP BY子句不能使用SELECT子句中列的别名。
- 如果分组中具有NULL值,则NULL将作为一个分组返回。
3.1.7 模糊搜索
例如,当搜索列表中姓李的记录时,无法通过比较进行搜索。因此,我们需要模糊搜索模式。
1. 通配符搜索
语法:
SELECT 列名 FROM 表名 WHERE 列名 LIKE '%内容';
SELECT * FROM employee1 WHERE name LIKE '内容_';
实例:
SELECT * FROM employee1 WHERE name LIKE '李%'; -- '李%'是一种搜索模式,表示我们要搜索的内容
SELECT * FROM employee1 WHERE name LIKE '李_';

通配符搜索总结:
- %通配符表示任意字符出现任意次数;
- _通配符表示单个字符;
2. 正则表达式搜索
正则表达式不仅用于其他语言中的文本(字符串集)匹配,还用于SQL语言中的文本匹配。接下来,我只是简单讲讲,具体讲解参考其它语言的正则表达式。
语法:
SELECT * FROM employee1 WHERE name REGEXP '搜索模式';
实例:
SELECT * FROM employee1 WHERE name REGEXP '^[0-9\\.]';

3. 附加表
| 特殊字符 | 说明 |
| \\f | 换页 |
| \\n | 换行 |
| \\r | 回车 |
| \\t | 制表 |
| \\v | 纵向制表 |
| 类 | 说明 |
| [:alnum:] | 任意字母和数字 |
| [:alpha:] | 任意字符 |
| [:blank:] | 空格和制表 |
| [:digit:] | 任意数字 |
| [:lower:] | 任意小写字母 |
| [:upper:] | 任意大写字母 |
| 字符 | 说明 |
| * | 任意多个 |
| + | 大于0个 |
| ? | 0个或1个 |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围 |
3.1.8 聚合函数
- 聚合函数的概念
聚合函数作用于一组数据,并返回一个值。 - 常用的聚合函数
(1) AVG( ); SUM( ); — 不能作用字符串和日期类型
(2) MAX( ); MIN( );
(3) COUNT( )
第一步:创建一个表
CREATE TABLE employee_1(
id int,
name varchar(20),
salary double
);
第二步:插入数据
INSERT INTO employee_1 VALUES(1, '菲菲', 2000);
INSERT INTO employee_1 VALUES(1, '程程', 5020);
INSERT INTO employee_1 VALUES(1, '豆豆', 3600);
INSERT INTO employee_1 VALUES(1, '尧尧', 4300);
第三步:查询数据
SELECT * FROM employee_1;
第四步:测试聚合函数
SELECT AVG(salary), SUM(salary), MAX(salary), MIN(salary), COUNT(name)
FROM employee_1;

3.2 多表查询
3.2.1 外键
外键为某个表的一列,它包含了另一张表的主键值,从而定义了两个表之间的关系。这个知识点不常用,下面仅用于练练手。
语法:
FOREIGN KEY(ordersid) REFERENCES orders(id);
实例:
第一步:
CREATE TABLE dept
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
第二步:
INSERT INTO dept VALUES(null, '新一团');
INSERT INTO dept VALUES(null, '新二团');
INSERT INTO dept VALUES(null, '新三团');
第三步:
CREATE TABLE emp
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
dept_id INT,
FOREIGN KEY(dept_id) REFERENCES dept(id)
);
第四步:
INSERT INTO emp VALUES(null, '孙德胜', 1);
INSERT INTO emp VALUES(null, '张大彪', 2);
INSERT INTO emp VALUES(null, '和尚', 3);
INSERT INTO emp VALUES(null, '赵刚', 3);
INSERT INTO emp VALUES(null, '李云龙', 3);
INSERT INTO emp VALUES(null, '丁伟', 1);
3.2.2 笛卡尔积查询
直接书写两张表的名称进行查询即可获取笛卡尔积查询结果。
第一步:
CREATE TABLE dept
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20)
);
第二步:
INSERT INTO dept VALUES(null, '新一团');
INSERT INTO dept VALUES(null, '新二团');
INSERT INTO dept VALUES(null, '新三团');
第三步:
CREATE TABLE emp
(
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
dept_id INT
);
第四步:
INSERT INTO emp VALUES(null, '孙德胜', 1);
INSERT INTO emp VALUES(null, '张大彪', 2);
INSERT INTO emp VALUES(null, '和尚', 3);
INSERT INTO emp VALUES(null, '赵刚', 3);
INSERT INTO emp VALUES(null, '李云龙', 3);
INSERT INTO emp VALUES(null, '丁伟', 1);
第五步:
SELECT * FROM dept;
SELECT * FROM emp;
SELECT * FROM dept, emp;
SELECT * FROM emp, dept;
SELECT emp.id, emp.name, dept.name FROM emp, dept WHERE emp.dept_id=dept.id;
SELECT emp.id, emp.name AS emp_name, dept.name AS dept_name FROM emp, dept WHERE emp.dept_id=dept.id;

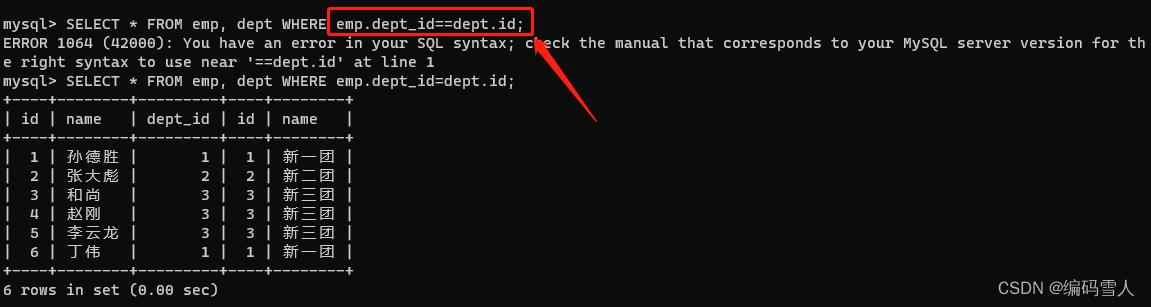


扩展知识点
上面我们使用了’‘emp.dept_id’'表达式,其中emp是表名,dept_id是字段名称。我们把这样的表达式称为完全限定的表名。
3.2.3 内连接查询
在笛卡尔积的基础上,获取左右两边表均有的记录,这样的操作称为内连接查询。
语法:
SELECT * FROM 左边表 INNER JOIN 右边表 ON 判断条件;
实例:
SELECT emp.id, emp.name AS emp_name, dept.name AS dept_name FROM emp INNER JOIN dept ON emp.dept_id=dept.id;

3.2.4 外连接查询
- 左外连接查询:在内连接查询的基础上,获取左边表有而右边表没有的数据。
INSERT INTO dept VALUES(null, '独立团'); -- 为了更加清楚的认识左外连接,在此给dept表中添加一条数据
SELECT * FROM dept LEFT JOIN emp ON dept.id=emp.dept_id;

- 全外连接查询:在内连接查询的基础上,获取左边表有而右边表没有和右边表有而左边表没有的数据。然而,在mysql中没有全外连接关键字,只能通过union关键字实现全外连接的查询效果。
SELECT * FROM dept LEFT JOIN emp ON dept.id=emp.dept_id
UNION
SELECT * FROM dept RIGHT JOIN emp ON dept.id=emp.dept_id;

- 右外连接查询:在内连接查询的基础上,获取右边表有而右边表没有的数据。
INSERT INTO emp VALUES(null, '丽萨', 8); -- 为了更加清楚的认识左外连接,在此给emp表中添加一条数据
SELECT * FROM dept RIGHT JOIN emp ON dept.id=emp.dept_id;

4. 推荐书籍
[1] 刘晓霞, 钟鸣(译). MySQL必知必会[M]. 北京:人民教育出版社.
[2] 孙淼, 罗勇(译). SQL基础教程[M]. 北京:人民教育出版社.














 890
890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









