






随机森林算法
1.随机森林原理介绍
Random Forest 是 ensemble learning (集成学习?)算法的一种,它利用多棵树对样本进行训练并预测的一种分类器,同样也可用户回归,其输出的类别是由个别树输出的类别的众数而定。
该算法最早由Leo Breiman和Adele Cutler提出, 而”Random Forests”是他们注册的商标。这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。1
简单来说,随机森林就是由多棵CART(Classification And Regression Tree)构成的。对于每棵树,它们使用的训练集是从总的训练集中有放回采样出来的,这意味着,总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。
2.随机森林训练过程
用N来表示训练用例(样本)的个数,M表示特征数目。
- 从N个训练样本中以有放回抽样的方式,取样N次,形成一个训练集(即bootstrap取样),并用未抽到的用例(样本)作预测,评估其误差。
- 输入特征数目m,用于确定决策树上一个节点的决策结果;其中 m<<M 2。
- 对于每一个节点(每个样本有M个属性时),随机选择m个特征,采用某种策略(比如信息增益)来选择1个属性作为该节点的分裂属性并进行分裂。
- 每棵树都会完整成长而不会剪枝(Pruning,这有可能在建完一棵正常树状分类器后会被采用)。
- 将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。
3.比较
sklearn给出的图像展示了单个决策树、随机森林和其他算法的决策边界和模型容量
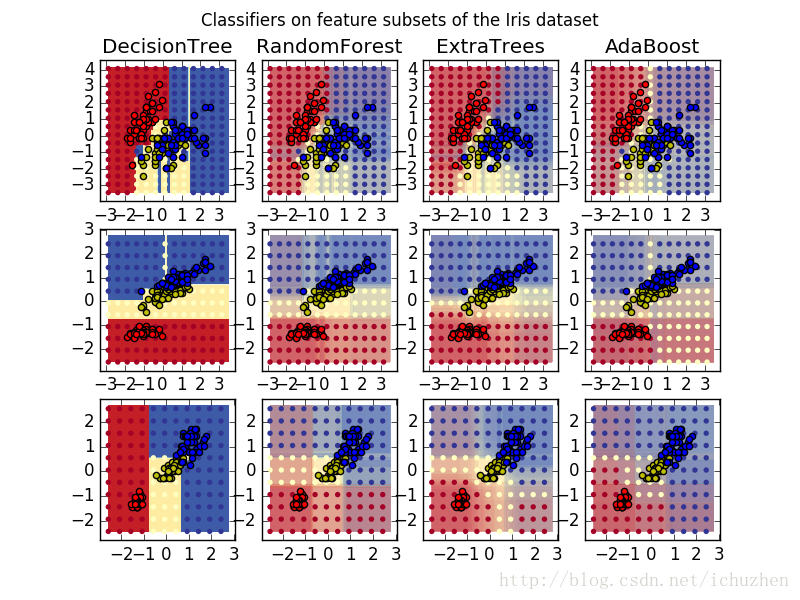
DecisionTree with features [0, 1] has a score of 0.926666666667
RandomForest with 30 estimators with features [0, 1] has a score of 0.926666666667
ExtraTrees with 30 estimators with features [0, 1] has a score of 0.926666666667
AdaBoost with 30 estimators with features [0, 1] has a score of 0.84
DecisionTree with features [0, 2] has a score of 0.993333333333
RandomForest with 30 estimators with features [0, 2] has a score of 0.993333333333
ExtraTrees with 30 estimators with features [0, 2] has a score of 0.993333333333
AdaBoost with 30 estimators with features [0, 2] has a score of 0.993333333333
DecisionTree with features [2, 3] has a score of 0.993333333333
RandomForest with 30 estimators with features [2, 3] has a score of 0.993333333333
ExtraTrees with 30 estimators with features [2, 3] has a score of 0.993333333333
AdaBoost with 30 estimators with features [2, 3] has a score of 0.9933333333334.优缺点
优点
- 在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合
- 在当前的很多数据集上,相对其他算法有着很大的优势
- 能够处理很高维度的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 可生成一个Proximities=(pij)矩阵,用于度量样本之间的相似性: pij=aij/N, aij表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数
- 在创建随机森林的时候,对generlization error使用的是无偏估计
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
缺点
RF 算法的主要缺点就是模型规模。模型很容易就以会花费成百上千兆字节内存,最后会因为评估速度慢而结束。另一个可能会引发担忧的缺点就是随机森林模型过程是很难解释清楚的黑箱。
- https://zh.wikipedia.org/wiki/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97 ↩
- 在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回的抽取的,根据Leo Breiman的建议,假设总的特征数量为M,这个比例可以是 M−−√ , 12M−−√ , 2M−−√ 。 ↩














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









