






3 评估重新标注的数据集
有了重新标注的数据集后,我们开始评估训练模型对合成文本的影响。我们试图回答两个问题:
1. 使用每种类型的合成题注对性能的影响。
2. 合成题注与真实题注的最佳混合比。
3.1 混合合成题注和真实题注
我们的文本转图像扩散模型是一种似然模型(Likelihood model),有一种众所周知的倾向,即过度拟合数据集中的分布规律。例如,如果您尝试使用不以空格开头的提示进行推理,则对始终以空格字符开头的文本进行训练的文本转图像模型将可能无法正常工作。
当谈到对合成图像题注的训练时,我们需要考虑这个问题。我们的题注模型可能有许多难以检测的模态行为,但如果对那些题注进行训练,这些行为将成为我们的文本转图像模型的偏差。这种情况可能发生的例子有:字母大小写、题注中标点的位置(例如,它总是以句号结尾吗?)、题注的长度,或者文体风格,例如所有题注都以单词“a”或“an”开头。(针对英语来说的)
解决这个问题的最好方法是将我们的输入规范化为更接近人类可能使用的风格和格式的文本分布。当使用基本事实的题注时,您可以“免费”获得它,因为这些题注实际上是从人类书写的文本分布中提取的。为了在使用合成题注时将一些正则化引入到我们的模型训练中,我们选择将合成题注与真实题注相混合。
混合发生在数据采样时,我们以固定的百分比概率随机选择基本事实或合成题注。我们将在下一节中分析不同混合比率对性能的影响。
3.2 评估方法
为了评估,我们在同一数据集上训练了相同的 T5 条件(T5-conditioned)图像扩散模型。所有模型都经过 500,000 个训练步的训练,批量大小为 2048,总共对应 1B 个训练图像。
训练完成后,我们使用一个评估数据集中的题注从每个模型生成 50,000 张图像。然后,我们使用 Hesselet al. (2022) 中概述的 CLIP-S 评估指标评估了这些生成的图像。我们选择 CLIP 分数作为指标,因为它与文本/图像相似度有很强的相关性,这正是我们想要的。简单回顾一下,该指标的计算方法如下:
首先,我们使用公共 CLIP ViT-B/32[17] 图像编码器生成图像嵌入 zi,然后使用文本编码器为图像题注 zt 创建文本嵌入。最后,我们将 CLIP 得分计算为余弦相似度 C:
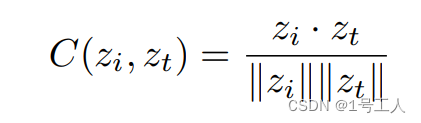
然后对该指标进行平均,计算所有 50,000 个文本/图像对的距离,并按 100 倍缩放。我们在训练期间对多个模型检查点执行此评估,始终使用模型学习权重的指数加权平均值进行评估。
图 4 针对不同题注类型进行训练的文本转图像模型的 CLIP 分数。左侧是使用我们的评估数据集上的真实题注评估结果。右侧使用来自同一数据集的描述性合成题注。
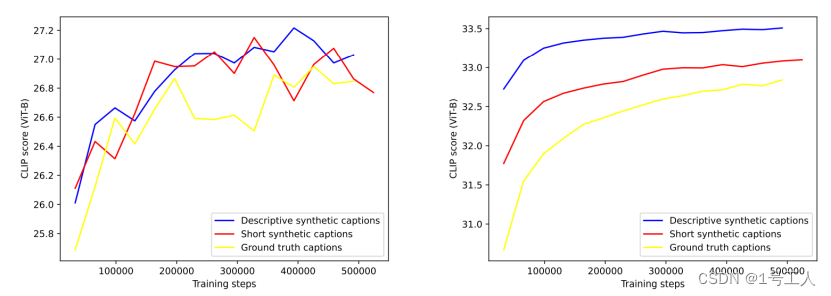
在计算 CLIP 分数时,选择使用哪个题注进行上述计算非常重要。对于我们的测试,我们要么使用基本事实题注,要么使用描述性合成题注。每次评估中都会注明使用哪种题注。
3.3 题注类型结果
在不同类型的题注训练的模型之间,我们首先分析他们的性能差异。为了这次评估,我们训练了三个模型:
- 仅针对真实内容(ground-truth)题注进行训练的文本转图像模型。
- 基于 95% 简单合成题注进行训练的文本转图像模型。
- 基于 95% 描述性合成题注进行训练的文本转图像模型。
我们进行了两次评估:一次使用根据基本事实题注计算出的 zt,一次使用根据描述性合成题注计算出的 zt。我们不会对简短的合成题注进行此操作,因为它们在本次评估中与事实题注非常相似。
结果如 图 4 所示,表明在对真实(ground-truth)题注进行评估时,对合成题注进行训练的两个模型的 CLIP 分数表现均略优于基线模型,而在对描述性合成题注进行评估时,其表现明显更佳。这表明在训练文本转图像模型时使用合成题注没有任何不利之处。
有趣的是,合成题注的评估曲线的方差要低得多。这支持了我们的理论,即改进题注可以看作是一种均衡操作。在合成题注上评估的图像生成模型也在所有训练的模型中获得了更高的净 CLIP 分数,这支持了合成题注与其对应图像具有更好的结合的观点。
3.4 题注混合比率
为了评估题注混合比率,我们使用不同混合比率的描述性合成题注,训练了四个图像生成模型。我们选择了 65%、80%、90% 和 95% 的合成题注混合比率。实验进行到中途,评估显示 65% 的混合比率在所有评估中都远远落后于其他混和比率,因此我们放弃了它。
图 5 – 针对各种混合比例的描述性合成题注和真实内容题注进行训练的文本转图像模型的 CLIP 分数。使用真实内容题注进行评估。
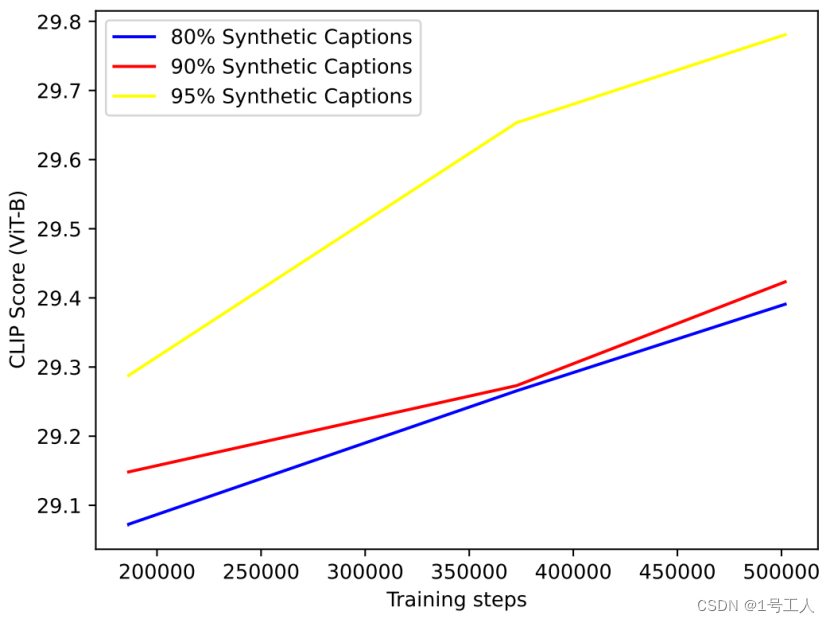
图 5 中的结果表明,更高程度的合成题注混合总是能提高模型的 CLIP 分数。
3.5 高度描述性题注的实际用途
上述实验表明,我们可以通过在高占比的合成题注上训练可以最大化提高模型的性能。然后,这样做导致模型自然地适应题注制作者发出的长而高度描述性题注的分布。
众所周知,生成类模型从他们的训练分布中采样时会产生较差的结果。因此,为了从我们的模型中挖掘出最大的潜力,我们需要从中专门抽取具有高度描述性的题注。幸运的是,随着大型语言模型的最新突破,这个问题可以得到解决。像 GPT-4这样的模型已经在讲故事和写诗等需要想象力的任务上表现得非常出色。按理说,他们也可能擅长在图像描述中提出合理的细节。
事实上,给出提示,我们发现 GPT-4 会很容易地将任何题注“上采样(upsample)”为高度描述性的题注。为了证明这种方法的实用性,我们对 drawbench 数据集[24]中的题注执行了此过程,并在表 7 中将结果可视化。
如图 7 所示,利用 LLM 对题注进行“上采样”不仅可以用来添加消失的细节,还可以消除复杂的关系歧义,而这种关系歧义对于一个相对小的图像生成模型来说是很难学习的。最终的结果是,模型通常会正确地渲染原本会出错的图像。
图6-使用“上采样(upsample)”drawbench 题注通过 DALL-E 3 创建样本的效果。前两张图片是使用原始的drawbench 题注;后两张是“上采样(upsample)”题注。每张字幕的图片均为 4 张中的最佳图片。
一只鸟吓唬稻草人。

用一枚披萨大小的 25 美分硬币来买一份 25 美分大小的披萨。

一只巨大、充满活力、翼展惊人的鸟儿从天而降,发出刺耳的叫声,靠近一个阳光照耀的田野中饱经风霜的稻草人。稻草人穿着破烂的衣服,戴着草帽,似乎在颤抖,仿佛因为害怕接近的鸟儿而被吓活了。

一个人站在披萨柜台前,手里拿着一个披萨大小的巨型 25 美分硬币。收银员惊讶地睁大了眼睛,递给他一个 25 美分硬币大小的小披萨。背景是各种披萨配料和其他顾客,他们都对这笔不寻常的交易感到惊讶。

4 DALL-E 3
为了大规模测试我们的合成题注,我们训练了 DALL-E 3,,这是一种最先进的文本转图像生成器。为了训练这个模型,我们使用了 95% 的合成题注和 5% 的真实题注的混合体。(DALL-E 3 相对于 DALL-E 2 有很多改进,其中许多改进未在本文档中介绍,并且由于时间和计算原因无法消除。本文档中讨论的评估指标不应被解释为仅仅对合成题注进行训练所产生的性能比较。)
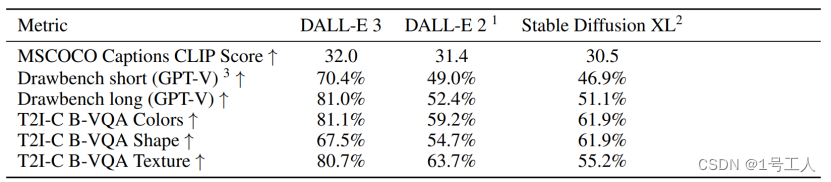
表 1 – 文本转图像模型在提示跟随相关各种评估中的比较

4.1 自动评估
我们将 DALL-E 3 与 DALL-E 2 ,以及稳定的带有精简模块的Diffusion XL 1.0 进行比较。我们希望评估 DALL-E 3 在与及时跟进相关的任务上的表现。我们在下面分别描述。
4.1.1 CLIP分数
我们首先使用第 3.2 节中描述的公共 ViT-B/32 模型计算 CLIP 分数。为了进行比较,我们使用从 MSCOCO 2014 评估数据集[10]中提取的一组 4,096 个题注来生成我们的图像。(与 DALL-E 的过去版本一样,DALL-E 3 并未针对 MSCOCO 数据集进行专门训练,我们也没有对我们的模型进行任何优化以提高本次评估的性能。我们也没有在训练数据集内对 MSCOCO 进行重复数据删除,因此可能存在数据泄露。)在本次评估中,我们使用简短的真实(ground-truth)题注模型进行推断结论。
我们的模型在本次评估中表现优于 DALL-E 2 和 Stable Diffusion XL。
4.1.2 Drawbench
接下来,我们将对 drawbench中的题注进行评估。在这次测试中,我们使用基于 GPT-4 的指令调整、视觉感知的 LLM(称为 GPT-V)来评估我们的模型与其他模型的性能。对于 drawbench 中的每个提示,我们用每个模型生成四张图像。然后,我们使用提示,通过图像和文本提示我们的视觉感知 LLM。这会得出结论(“正确”/“不正确”)以及对该结论的解释。
由于我们之前观察到,当给出从一个语言模型中推断出的题注时,我们的模型表现更好,因此我们通过GPT-4 ,使用第 3.5 节中描述的方式,对 drawbench 题目进行“上采样(upsample)”。
在从所有模型中采样图像时,我们会使用这些“上采样(upsample)”题注再次执行上述自动评估。在使用视觉感知 LLM 判断输出结果时,我们会使用原始的、真实(ground-truth)的drawbench 提示。
在所有drawbench 评估中,我们的模型都胜过 DALL-E 2 和 Stable Diffusion XL。当我们使用“上采样(upsample)”字幕时,差距明显扩大。
4.1.3 T2I-CompBench
最后,我们根据 Huang 等人 (2023) 开发的 T2I-CompBench 评估套件的一个子集进行评估。该基准测试衡量一个模型在构图提示上的表现。我们报告了颜色绑定、形状绑定和纹理绑定的分数。我们使用 Disentangled BLIP-VQA 模型来评估这些结果。
DALL-E 3 在所有评估基准上都处于领先地位。
4.2 人工评估
我们提交了 DALL-E 3 和对比模型的样本以供人工评估。在此次评估中,我们向人工评分员展示了两张由相同标题生成的并排图像。然后我们向评估者提出以下三个问题之一:
1,提示跟随:评估者会看到用于文本转图像模型的完整上采样(upsample)题注,并被要求“选择哪个图像更符合题注”。
2,风格:“想象一下,您正在使用一个计算机工具,该工具可以根据一些文本生成图像。如果您正使用此工具,选择您希望看到哪幅图像。”
3,连贯性:“选择哪张图像包含更多连贯的物体。‘连贯’的物体是可能存在的物体。仔细观察身体部位、面部和人体姿势、物体的位置以及场景中的文本,以做出判断。提示:对每张图像的不连贯性实例计数,并选择问题较少的图像。”
针对提示跟随和风格,我们为本次评估组建了一个包含 170 条题注的小型数据集,该数据集专门针对一个生产文本转图像系统的典型使用。这些题注涵盖了广泛的实际用例,如生成人类、产品和地点、概念融合、文本渲染和艺术品。为了条理,我们观察到评分者会对描绘虚构场景的图像打低分。因此,我们从 MSCOCO 中随机抽取了 250 条题注,以确保用于评估的题注所描述的场景是合理地存在。请注意,对于风格和连贯性的评估,我们不会向评估者展示用于生成图像的题注,以确保他们关注风格或连贯性,而不是提示跟随。对于每个图像对和问题,我们都会收集来自评分者的 3 个回复,每个模型和问题总共有 2040 个评分。
我们将 DALL-E 3 与 Stable Diffusion XL,以及 Midjourney v5.2 进行了比较。在表 2 中,我们使用 Nichol 等人 (2022) 中概述的相同计算方法报告了 ELO 分数。
结果显示,在所有三个方面,人类评分者大多数时候都更喜欢由 DALL-E 3 生成的图像,尤其是在提示跟随方面。
表 2 – DALL-E 3 与其他文本转图像生成模型的人工评估结果。报告的分数是使用 Nichol 等人的 ELO 算法计算得出的。(2022 年)

4.2.1 Drawbench 人工评测
在上一节中,我们使用 GPT-V 评估了 drawbench。我们注意到,对于某些类型的测试,GPT-V 在判断提示跟随方面的表现并不比随机表现更好。尤其是在涉及计算图像中物体数量的任务中,情况尤其如此。为了更好地覆盖drawbench的性能,我们使用上一节中描述的步骤提交了图像和标题以供人工评估。与我们的 GPT-V drawbench评估一样,我们仅比较 DALL-E 3、带有精炼模块的 Stable Diffusion XL 和 DALL-E 2。















 1734
1734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









