






从标题可以看出,论文介绍了Facebook(以下简称FB)的向量召回技术,也就是Embedding-Based Retrieval(EBR)。让我们开始吧,祝开卷有益!论文地址:
这是一篇Applied Data Science Track Paper,非Research Track Paper,侧重于工业界技术的落地。
ACM:https://dl.acm.org/doi/10.1145/3394486.3403305
arXiv:https://arxiv.org/abs/2006.11632
1. 预备知识
首先,搜索引擎的匹配策略按照查询关键词(Query)是否完全命中文档(Document,以下简称doc),可以分为两大类:term matching(以下译作文本匹配)与semantic matching(语义匹配)。
文本匹配,能够做到完全精确的匹配(Exact Match)。如果是中文,通常先对query进行分词,得到更细粒度的词(Term);再用term去检索doc,term出现于doc则命中;然后取各个term检索结果的交集返回。
我之前看过一点《Introduction to Information Retrieval》,它的第一章就在讲布尔召回(Boolean Retrieval),正是上面这一套传统的做法。如果本文点赞破100,我就是不吃不喝也要啃完这部经典,与诸君交流分享。
语义匹配,不再追求完全精确的匹配,而是力图满足用户的搜索意图(Search Intent),也就是意会。用户输入的query,只是Ta搜索意图的一种表达形式而已,比如“美国前总统”、“唐纳德・特郎普”、“川普”都是“懂王”。要表示用户意图,就用到了本文的主角embedding,一种用稠密向量(Dense Vector,没有特殊说明,后文的向量都指稠密向量)来表征对象的形式(Representation)。然后基于query embedding与doc embedding来计算结果。
一个有趣的说法:万物皆可embedding。没那么高深,就是用向量来表示对象,然后用向量之间的计算来表示对象之间的关系。换个说法,如果你是一个丹青圣手,万物皆可入画,你可以用画中世界来反映现实世界。Embedding也是类似,不过是以它的方式来描摹这个世界。
按阶段划分,搜索引擎通常有两个大的步骤:召回(Retrieval)与排序(Ranking)。召回,算是一个比较生僻的词,新闻里偶尔报道“问题产品的召回”,搜索中召回是同样的意思,就是尽可能把涉及的相关的doc一个不漏找全了,宁抓错不放过,前文的两类匹配策略也可以说是召回策略;排序的话,就是在召回的基础上,把更相关的、更符合用户意图的doc排在更显眼的位置。
说到这儿,论文将要介绍的EBR应该比较清晰了:用embedding来表示query与doc,得到query embedding与doc embedding,将召回问题转化为向量空间中的最近邻搜索问题。
在搜索召回时应用EBR的一个挑战是:召回是万里挑一的工作,从海量的数据——上千万甚至亿级的doc中,找出成百上千相关的doc。这对于embeddings的训练与使用都是极其严峻的考验。
且看,FB是如何迎难而上的。
2. 本文工作
FB按照阶段划分了面临的挑战,并提出了不同的解决方案:
建模(Modeling)。他们提出了unified embedding——一个双塔模型,一端是query,另一端是doc;
服务(Serving)。针对多通道召回(EBR 与布尔召回)的问题,他们开发了一个混合召回框架;
全栈优化。为了对整个搜索系统进行全面的优化,他们将embeddings 集成到了排序层,构造了一个数据闭环,以学习更好的embeddings。
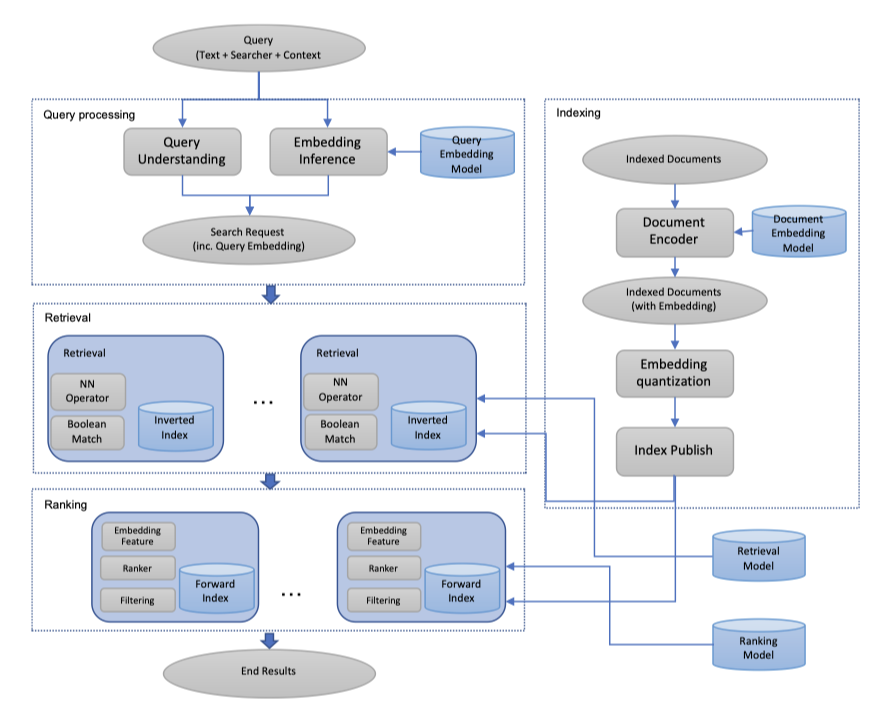
上图是FB的EBR召回系统的概览,各位不妨先花两分钟研究一下,再继续往下看。
2.1 建模
搜索召回任务可以公式化为召回优化问题,即给定query、与query相关的doc全集
、模型召回的topK个结果
,最大化: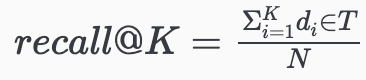 也就是,尽可能将相关的doc找全了。
也就是,尽可能将相关的doc找全了。
前文提到EBR将召回问题转化为向量空间中的最近邻搜索问题,EBR模型返回的topK个结果就是“向量空间中,与query embedding‘距离’最近的doc embeddings表示的K个docs”。
建模的目的就在于:如何构造query embedding与doc embedding。在此,FB并没有太多的创新,使用了目前业界常用的双塔模型——用两个神经网络分别作为query与doc的编码器,如下所示。

与常规方法(仅文本进行编码)不同的是,他们在query侧与doc侧都加入了辅助特征,比如query侧加入了用户的位置、社交关系等,是为unified(大一统的) embedding。
值得注意的是,对于类别特征(Categorical Feature),他们的处理与文本一样,先做embedding,再将得到的特征向量输入编码器,同其他特征一起计算unified embedding。
从信息的视角来看,unified embedding的有效性高度依赖于添加的特征补充的信息量。
文章简要介绍了几点特征工程的工作:
文本特征:通过char n-gram补充了subword信息;
位置特征:在query侧,补充了搜索发起者的城市、地域、国家、使用语言;在document侧,补充了开放性的位置信息,比如群组的位置;
社交embedding特征:为了更好地利用社交网络信息,基于社交图谱训练了一个embedding模型。
2.2 训练
训练使用的损失函数则是一个三元(Triplet)的间隔损失(Margin Loss):

其中, 、 、 分别表示query、与query相关的doc(正样本)、不相关的doc(负样本), 是距离函数, 则是间隔(Margin)。
距离函数与相似度函数是一组相对的概念。作者使用常规的余弦相似度(Cosine Similarity)来度量query embedding与doc embedding的相似度: 因此,距离函数 。
根据作者们的说法,损失函数中, 的选择很重要,会导致5-10%的离线召回偏差。
此外,训练样本的选择对于训练效果同样至关重要。本文的做法是,对于负样本,使用随机样本而不是展现未点击的样本。
这一点,有数据的支撑——使用展现未点击样本的召回效果明显更差。不过也很好理解:模型工作在召回层,召回的目的是海量样本中找全相关的样本。使用随机样本,召回候选集是全体样本,能够模拟真实自然的召回过程;而使用展现未点击样本,召回候选集是既有召回算法过滤后的、是有偏的,将导致模型习得的embeddings也是有偏的,无法习得未展现样本的特征。
至于正样本的选择,文章实验了点击样本与展现样本,在数据量相当的情况下,两种策略的效果相近。
2.3 线上服务
2.3.1 近似近邻搜索
向量召回的线上服务主要依赖于近似近邻搜索算法(Approximate Near Neighbor,ANN)来建立倒排索引。这一技术方案的优点在于:
向量量化(Quantization of embedding vectors)使得存储的成本更低;
保留了倒排索引,易于集成到当前的检索系统中。
具体的实现则依赖于FB自家的Faiss。
向量量化有两大组件:Coarse Quantization(CQ)和Product Quantization(PQ),前者主要使用K-means将向量转成相对粗糙的聚类,后者则通过更加精细的量化来支持高效的距离计算。
CQ、PQ都有一些算法以及参数可供选择与调整(统称ANN的参数调整),对此感兴趣的同学可以去看原文或Faiss的Wiki。以下是几点tricks:
参数调整时,以召回率/扫描的文档数为指标,比如recall@10;
最后再调整ANN的参数,或者说一旦向量召回的模型重大变更,ANN的参数务必重新调整;
务必尝试OPO(PQ的一种算法);
将pq_bytes(PQ算法的一项参数,指定了字节数)设为d/4(d是向量的维数);
以线上实验效果为准,调整nprobe(决定了将为query_emb分配的聚类数),num_clusters,pq_bytes,从而更好地去理解它们对真实性能的影响。
2.3.1 系统实现
在集成向量召回之前,让我们先来简单地看一看FB原来的检索系统(被称为Unicorn,独角兽)是怎样的。
以bag of terms来表示一篇doc,term并不限于文本,而是可以表征任意的二值属性,比如“北京的赵喧典”拥有的属性就包括“text:赵喧典”和“location:北京”。
类似地,以上述形式来表示一个query,比如“北京或浙江的赵喧典”,它的布尔表达式就是(and (or (term location:北京)(term location:浙江)) (term text:赵喧典))。利用布尔召回,将返回所有使得表达式为真的doc。
为了支持向量召回,检索系统为每一篇doc添加了额外的embedding字段。考虑到不同模型的向量召回,一篇doc可以绑定多个embedding,以不同的<model>作为区分。相应地,在query侧增加了形如(nn <model> :radius <radius>)的算子,表示doc需要满足在<model>向量空间中,doc_emb与query_emb的余弦距离小于<radius>。
上例中,“北京或浙江的赵喧典”,在追加向量召回通道之后,其布尔表达式就变为了:
(and
(or (term location:北京) (term location:浙江))
(or (term text:赵喧典) (nn M1 :radius 0.2333))
)
此处,FB的工程师们对比过按距离召回与按TOP K召回两种形式。前者在系统性能与召回结果的质量之间能取得更好的平衡,因为它对于搜索半径以及近邻的相似性都有所限制。
此外,为了提高向量召回的效率与质量,使用了query selection和index selection。
所谓query selection,就是有选择性地触发向量召回,对于向量召回不的,比如搜索意图与模型训练的初衷不同的,或者过于简单的query,比如用户刚刚搜索过或点击过的,不进行向量召回。
所谓index selection,实际上是构建倒排索引时,只使用月活用户而不是全部用户,近期的事件,热门群组等。
通过上述描述,我们能够知道,在双塔模型训练完毕之后,query embedding模型与doc embedding模型是分开使用的,这也是业界对双塔模型的常规使用方式。具体地,query_emb是在线实时推断的,而doc embedding模型是离线部署的,批量地为各个doc生成embedding,并发布到Faiss中。
2.4 其他
2.4.1 整体优化与训练闭环
考虑到既有的排序算法是为非向量召回的结果设计的,其排序结果对于向量召回通道的结果可能是次优的。FB的工程师们提出了以下两点解决思路:
向量召回的embedding作为排序算法的特征。具体地,就是将向量相似度,或者向量召回模型吐出的原始向量透传给排序算法。实验表明,在FB的搜索场景下,透传余弦相似度对排序算法的提升最佳。
训练数据反馈闭环。相对于文本召回,向量召回提高了召回率(recall),但是精准率(precision)有所不如。财大气粗的FB引入了人工评估——将向量召回的结果落日志,人工评估召回结果的相关性,并用人工标注的结果重新训练模型,真正形成数据的闭环。
2.4.2 Hard Mining
因为诸如文本召回、向量召回以及其他不同召回技术的混合使用(多通道召回),使得召回结果的数据分布极其多样。这对于向量召回模型的训练是一个不小的挑战——embedding的学习更加困难。
Hard mining是信息检索领域进行数据挖掘、构造合适训练集的技术的统称。
本文研究探讨了两类hard mining技术:
Hard negative mining。分析发现:当用户搜索人名时,同名情况下,向量召回模型没有充分利用样本的社交特征。这很可能是因为以随机样本作为负样本,负样本都是异名的,模型只需要关注文本特征即可。因此,工程师们提出使用与正样本更加相似的样本作为负样本来训练模型。
Online hard negative mining(此处的online并非线上服务的意思,而是训练时构造hard negative samples的意思)。具体的做法是,对于一个query,维护了一个正样本的池子,训练时,使用与当前正样本最相似的2条作为负样本(该数量来自于实验观察),并补充上随机负样本。
优点:带来了相当显著的召回率的提升;
缺点:拥有hard negative样本的比例相对随机负样本而言,很低。
Offline hard negative mining(训练前,在构造训练样本时挖掘hard negative样本)。具体的做法是,先利用某一算法(KNN、ANN)得到与query最相似的N个doc,再基于一个基于业务特点的挑选策略选择若干负样本,然后对模型进行迭代训练。挑选负样本-模型迭代,是一个不断迭代的过程。以下是几点实验洞察:
简单地用困难负样本训练的模型比随机负样本还差。分析发现,前者为非文本特征赋予了过多的权重,在文本匹配能力上差于后者;
挑选排序模型输出的位置在100->500(适合)的doc作为负样本,模型召回效果最佳;
保留随机负样本是极其必要的,它还原了召回的自然过程。可供参考的两种混合机制:1、混合随机样本与困难负样本,FB的最佳实践比例是100:1;2、迁移学习,先难后易,反之低效;
使用KNN来生成困难样本候选集的时间成本太高,可以直接上ANN。
Hard positive mining。上文提到,使用点击样本或展现样本作为正样本的效果相似;而此处的做法是,从搜索日志中挖掘未展现的正样本。有效,但是想来成本是相当高的。
2.4.3 Embedding Ensemble
Embedding Ensemble类似于model ensemble,就是集成多个不同的向量召回模型。在前文的介绍中,不同模型将关注到不同的特征,比如完全使用随机负样本的模型将更关注文本特征、召回能力更强,而使用困难负样本的模型的精准率更高、对排序更友好,因此embedding ensemble是一个自然能想到的优化的步骤。
是故,文章提出了多阶段召唤的方法:第一步关注扩召回,第二步在第一步的基础上关注区分相似的召回结果。并且,提供了两种思路:
Weighted concatenation:
实际上该方式只有一步,以加权求和的方式对不同模型算得的余弦相似度进行汇总,作为query与doc最终的相似度,再取最相似的作为召回结果。
线上服务时,为了服务性能,将先计算余弦相似度再加权求和的方式,近似地变形为先拼接向量再计算且只计算一次余弦相似度。
因此,操作流程就是,不同向量加权拼接,以拼接后的向量在Faiss中进行查询。
瀑布模型:
第一步使用简易的召回模型,可以是完全使用随机负样本训练的模型,甚至是text embedding而非unifed embedding,目的是触达更海量的候选集,不遗漏;
第二步使用精细一些的模型,比如使用离线困难负样本训练的模型,或者使用unified embedding代替text embedding,此时的目的是做一个类似rerank的动作,重新评估第一步得到的候选集中的doc与query的相似度,再按预设的召回量取TOP N条结果。
3. 尾声
我在半年前看完这篇论文,一直想写这篇笔记,与诸君交流,但总是写写停停;半年后,我有了更多的工作积累,这篇文章反而读厚了:刚毕业那会儿,我大概只能看到建模与训练部分,现在也会关注serving以及其他的工程实践。
原文真是一篇相当nice的论文,强烈建议翻一翻原文!














 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









