






本自然语言处理(NLP)程序主要实现以下功能:
- 文本处理:包括分词、词频统计、词性分类等功能。
- 数据存储:统计人名、地名、武器等,并将结果存储到 TXT 文件。
- 可视化:支持饼状图、柱状图、关系图、词云的生成。
- 用户自定义:允许用户建立自定义词典。
- 界面:提供 GUI 或 Web 界面(easygui/tkinter 或 Django)。
2. 设计思想
- 模块化编程:将每个功能封装成独立的函数,在主程序中调用,提高代码复用性和可维护性。
- 面向对象编程(可选):如果代码复杂度较高,可采用面向对象方式,提高可扩展性。
- 数据可视化:利用
matplotlib、pyecharts等库,实现多种可视化形式。 - 用户交互:提供 GUI 或 Web 界面,提高可操作性。
3. 主要库和库函数
| 库 | 主要功能 | 关键函数/模块 |
|---|---|---|
jieba | 中文分词 | jieba.cut()、jieba.load_userdict() |
collections | 词频统计 | Counter() |
matplotlib | 数据可视化(柱状图、饼图) | plt.bar()、plt.pie() |
wordcloud | 生成词云 | WordCloud() |
pandas | 处理数据 | pd.DataFrame() |
networkx | 关系图可视化 | nx.Graph()、nx.draw() |
tkinter/easygui | GUI 界面 | Tk()、msgbox() |
Django | Web 界面 | views.py、templates/ |
import jieba
import jieba.posseg as pseg
import collections
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import networkx as nx
import re
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 读取《三国演义》文本
def read_text(file_path):
with open(file_path, "r", encoding="ANSI") as f:
return f.read()
# 2. 分词(去除符号和单字)
def segment_text(text):
words = jieba.cut(text)
cleaned_words = [word for word in words if len(word) > 1 and re.match(r"[\u4e00-\u9fa5]+", word)]
return cleaned_words
# 3. 词频统计
def word_frequency(words, top_n=20):
word_counts = collections.Counter(words)
return word_counts.most_common(top_n)
# 4. 词性分类:提取人名、地名、武器(去除符号和单字)
# 4. 词性分类:提取人名、地名、武器(去除符号和单字)
def extract_entities(text):
persons, locations, weapons = [], [], []
# 扩展武器词典
weapon_dict = {"剑", "刀", "矛", "戟", "弓", "弩", "长枪", "铁锤", "方天画戟", "青龙偃月刀", "丈八蛇矛"}
words = pseg.cut(text)
for word, flag in words:
if len(word) > 1 and re.match(r"[\u4e00-\u9fa5]+", word): # 过滤单字和符号
if flag == "nr": # 人名
persons.append(word)
elif flag == "ns": # 地名
locations.append(word)
# 改进武器匹配(考虑武器作为子串的情况)
for weapon in weapon_dict:
if weapon in word: # 允许匹配长武器名称
weapons.append(weapon)
break # 防止重复匹配
return persons, locations, weapons
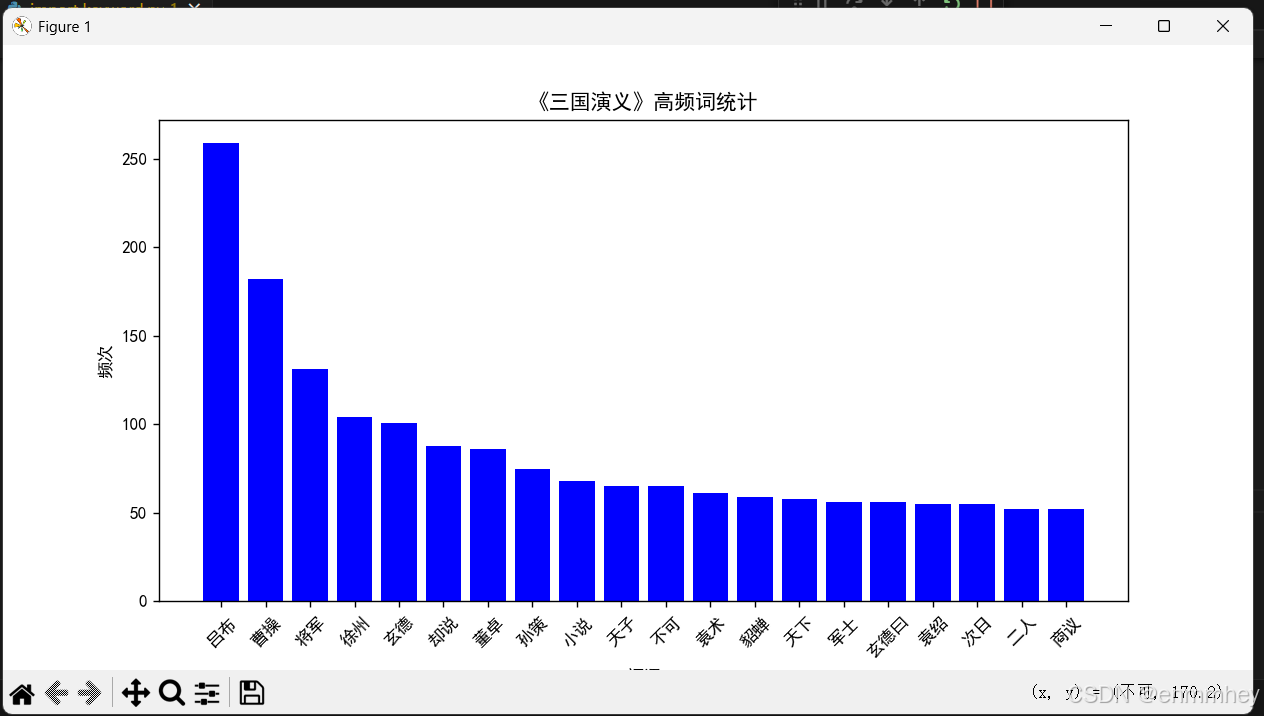
# 5. 词频可视化(柱状图)
def plot_bar_chart(word_counts, title="词频统计"):
words, counts = zip(*word_counts)
plt.figure(figsize=(10, 5))
plt.bar(words, counts, color="blue")
plt.xticks(rotation=45)
plt.xlabel("词语")
plt.ylabel("频次")
plt.title(title)
plt.show()
# 6. 生成词云
def generate_wordcloud(word_counts):
wc = WordCloud(font_path="msyh.ttc", background_color="white", width=800, height=400)
wc.generate_from_frequencies(dict(word_counts))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.show()
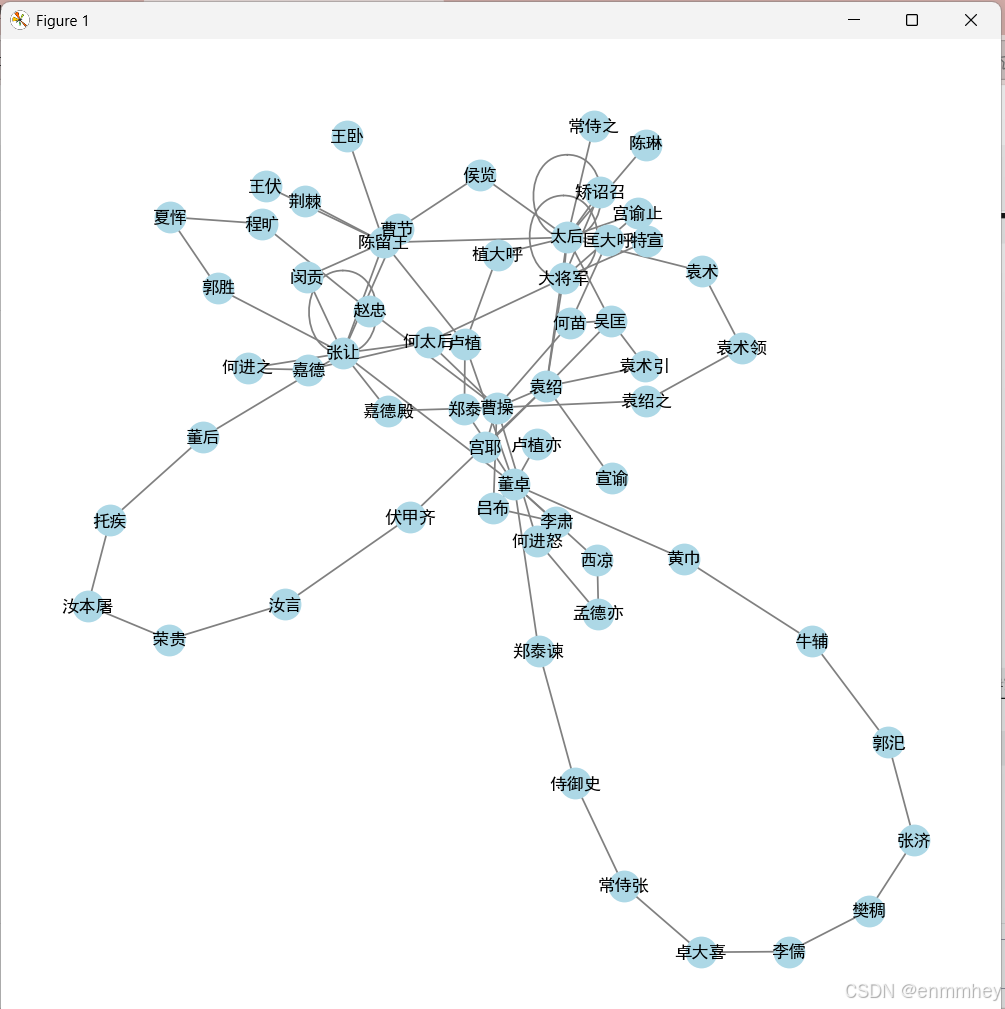
# 7. 关系图(模拟人物关系)
def generate_relation_graph(person_list):
G = nx.Graph()
for i in range(len(person_list) - 1):
G.add_edge(person_list[i], person_list[i + 1])
plt.figure(figsize=(8, 8))
nx.draw(G, with_labels=True, node_color='lightblue', edge_color='gray', font_size=10)
plt.show()
# 8. 结果保存到 TXT 文件
def save_to_txt(filename, data):
with open(filename, "w", encoding="utf-8") as f:
for item in data:
f.write(item + "\n")
# 9. 读取人物频率文件并绘制饼状图
def plot_pie_chart(file_path):
names, freqs = [], []
with open(file_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip() # 去掉首尾空格
if not line: # 跳过空行
continue
parts = line.split()
if len(parts) < 2: # 确保至少有“姓名 频率”
continue
name, freq = parts[0], parts[1]
if not freq.isdigit(): # 确保频率是数字
continue
names.append(name)
freqs.append(int(freq))
# 确保数据非空
if not names or not freqs:
print("错误:没有有效数据,请检查文件格式!")
return
# 设置颜色和标签
colors = plt.cm.tab20.colors # 使用预定义颜色
explode = [0.1 if i == 0 else 0 for i in range(len(names))] # 突出显示最高频人物
# 绘制饼状图
plt.figure(figsize=(12, 8))
wedges, texts, autotexts = plt.pie(
freqs,
labels=names,
colors=colors,
autopct="%1.1f%%",
startangle=140,
explode=explode,
textprops={"fontsize": 10, "fontfamily": "SimHei"}, # 支持中文显示
)
# 调整标签位置并添加标题
plt.setp(autotexts, size=10, weight="bold")
plt.title("《三国》人物出现频率分布", fontsize=16, fontweight="bold", pad=20)
plt.axis("equal") # 确保饼图为正圆
# 添加图例
plt.legend(
wedges,
[f"{n} ({f})" for n, f in zip(names, freqs)],
title="人物名称(频次)",
loc="center left",
bbox_to_anchor=(1, 0.5),
fontsize=9
)
plt.tight_layout()
plt.show()
# ========== 主程序 ==========
if __name__ == "__main__":
file_path = "D:\Desktop\三国演义_第一卷(第1章-20章).txt" # 你的《三国演义》文本文件路径
text = read_text(file_path)
# 分词
words = segment_text(text)
# 词频统计
top_words = word_frequency(words, top_n=20)
print("高频词:", top_words)
plot_bar_chart(top_words, "《三国演义》高频词统计")
# 提取人名、地名、武器
persons, locations, weapons = extract_entities(text)
print("人名统计:", collections.Counter(persons).most_common(10))
print("地名统计:", collections.Counter(locations).most_common(10))
print("武器统计:", collections.Counter(weapons).most_common(10))
# 生成词云
generate_wordcloud(top_words)
# 生成人物关系图(基于前100个人物)
generate_relation_graph(persons[:100])
# 保存结果
save_to_txt("三国_人名.txt", persons)
save_to_txt("三国_地名.txt", locations)
save_to_txt("三国_武器.txt", weapons)
# 读取人物频率文件并绘制饼状图
plot_pie_chart("三国人物频率.txt")


GUI界面
import tkinter as tk
from tkinter import filedialog
from tkinter import messagebox
import jieba
import jieba.posseg as pseg
import collections
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import networkx as nx
import re
# GUI 类
class NlpApp:
def __init__(self, root):
self.root = root
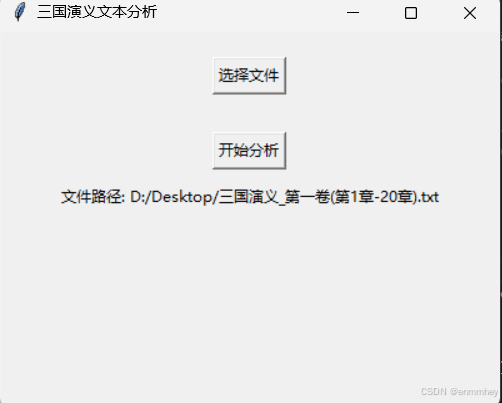
self.root.title("三国演义文本分析")
self.root.geometry("400x300")
self.file_path = ""
# 文件选择按钮
self.select_button = tk.Button(self.root, text="选择文件", command=self.select_file)
self.select_button.pack(pady=20)
# 分析按钮
self.analyze_button = tk.Button(self.root, text="开始分析", command=self.analyze_text)
self.analyze_button.pack(pady=10)
# 显示选择的文件路径
self.path_label = tk.Label(self.root, text="选择文件路径:")
self.path_label.pack()
def select_file(self):
file_path = filedialog.askopenfilename(title="选择文件", filetypes=[("Text Files", "*.txt")])
if file_path:
self.file_path = file_path
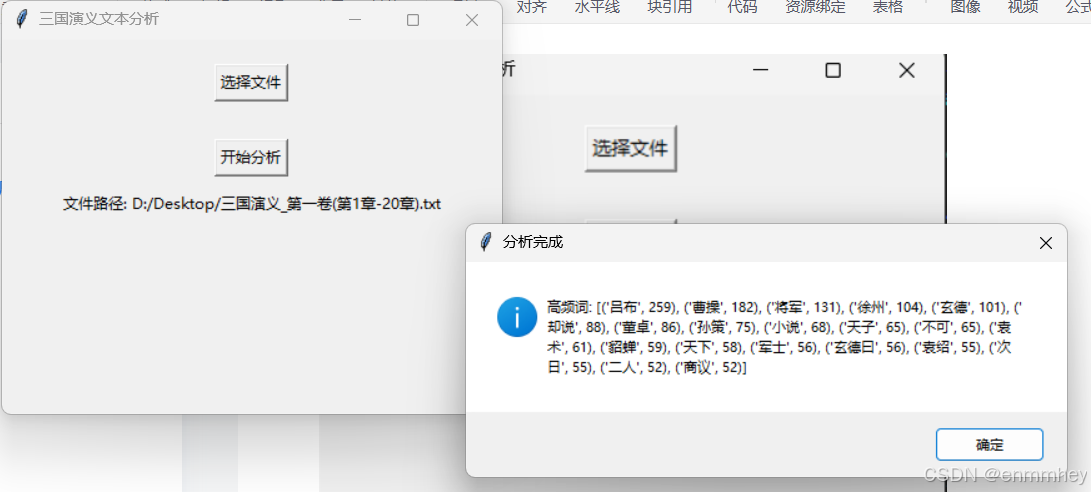
self.path_label.config(text=f"文件路径: {file_path}")
def analyze_text(self):
if not self.file_path:
messagebox.showwarning("警告", "请先选择文件!")
return
text = self.read_text(self.file_path)
words = self.segment_text(text)
top_words = self.word_frequency(words, top_n=20)
# 在 GUI 中展示分析结果
messagebox.showinfo("分析完成", f"高频词: {top_words}")
def read_text(self, file_path):
with open(file_path, "r", encoding="ANSI") as f:
return f.read()
def segment_text(self, text):
words = jieba.cut(text)
cleaned_words = [word for word in words if len(word) > 1 and re.match(r"[\u4e00-\u9fa5]+", word)]
return cleaned_words
def word_frequency(self, words, top_n=20):
word_counts = collections.Counter(words)
return word_counts.most_common(top_n)
# 启动 GUI 应用
if __name__ == "__main__":
root = tk.Tk()
app = NlpApp(root)
root.mainloop()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









