






tkinter登录网页
import tkinter as tk
import pickle
window = tk.Tk()
window.title('Login & Sign up')
window.geometry('450x300')
tk.Label(window, text='User name: ').place(x=50, y=150)
tk.Label(window, text='Password: ').place(x=50, y=190)
var_usr_name = tk.StringVar()
var_usr_name.set('example@python.com')
entry_usr_name = tk.Entry(window, textvariable=var_usr_name)
entry_usr_name.place(x=160, y=150)
var_usr_pwd = tk.StringVar()
entry_usr_pwd = tk.Entry(window, textvariable=var_usr_pwd, show='*')
entry_usr_pwd.place(x=160, y=190)
def usr_login():
usr_name = var_usr_name.get()
usr_pwd = var_usr_pwd.get()
try:
with open('usrs_info.pickle', 'rb') as usr_file:
usrs_info = pickle.load(usr_file)
except FileNotFoundError:
with open('usrs_info.pickle', 'wb') as usr_file:
usrs_info = {'admin': 'admin'}
pickle.dump(usrs_info, usr_file)
if usr_name in usrs_info:
if usr_pwd == usrs_info[usr_name]:
tk.messagebox.showinfo(title='Welcome', message='Welcome! ' + usr_name)
else:
tk.messagebox.showerror(message='Error, your password is wrong, try again.')
else:
is_sign_up = tk.messagebox.askyesno('Welcome', 'You have not sign up yet. Sign up today?')
if is_sign_up:
usr_sign_up()
def usr_sign_up():
def sign_to_Mofan_Python():
np = new_pwd.get()
npf = new_pwd_confirm.get()
nn = new_name.get()
with open('usrs_info.pickle', 'rb') as usr_file:
exist_usr_info = pickle.load(usr_file)
if np != npf:
tk.messagebox.showerror('Error', 'Password and confirm password must be the same!')
elif nn in exist_usr_info:
tk.messagebox.showerror('Error', 'The user has already signed up!')
else:
exist_usr_info[nn] = np
with open('usrs_info.pickle', 'wb') as usr_file:
pickle.dump(exist_usr_info, usr_file)
tk.messagebox.showinfo('Welcome', 'You have successfully signed up!')
window_sign_up.destroy()
window_sign_up = tk.Toplevel(window)
window_sign_up.geometry('350x200')
window_sign_up.title('Sign up window')
new_name = tk.StringVar()
new_name.set('example@python.com')
tk.Label(window_sign_up, text='User name: ').place(x=50, y=20)
entry_new_name = tk.Entry(window_sign_up, textvariable=new_name)
entry_new_name.place(x=160, y=20)
new_pwd = tk.StringVar()
tk.Label(window_sign_up, text='Password: ').place(x=50, y=60)
entry_new_pwd = tk.Entry(window_sign_up, textvariable=new_pwd, show='*')
entry_new_pwd.place(x=160, y=60)
new_pwd_confirm = tk.StringVar()
tk.Label(window_sign_up, text='Confirm password: ').place(x=50, y=100)
entry_new_pwd_confirm = tk.Entry(window_sign_up, textvariable=new_pwd_confirm, show='*')
entry_new_pwd_confirm.place(x=240, y=100)
btn_comfirm_sign_up = tk.Button(window_sign_up, text='Sign up', command=sign_to_Mofan_Python)
btn_comfirm_sign_up.place(x=150, y=130)
btn_login = tk.Button(window, text='Login', command=usr_login)
btn_login.place(x=170, y=230)
btn_sign_up = tk.Button(window, text='Sign up', command=usr_sign_up)
btn_sign_up.place(x=270, y=230)
window.mainloop()
参数的更新
将参数的梯度(导数)作为了线索,使用参数的梯度,沿梯度方向更新参数,并重复这个步骤多次,这个过程称为随机梯度下降法
SCG
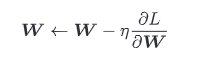
实现SCG
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
使用SCG进行神经网络的参数更新(伪代码)
network = TwoLayerNet(...)
optimizer = SGD()
for i in range(10000):
...
x_batch, t_batch = get_mini_batch(...) # mini-batch
grads = network.gradient(x_batch, t_batch)
params = network.params
optimizer.update(params, grads)
...
SGD 简单,容易实现,但是在解决某些问题时可能没有效率
Momentum
将optimizer = SGD() 这一语句换成 optimizer = Momentum(),可以从 SGD 切换为 Momentum
代码实现
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum*self.v[key] - self.lr*grads[key]
params[key] += self.v[key]
AdaGrad
学习率过小,会花费过多时间,学习率过大,则会导致学习发散而不能正确进行
AdaGrad 会为参数的每个元素适当地调整学习率
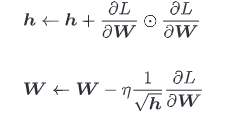
AdaGrad 会记录过去所有梯度的平方和,因此,学习越深入,更新的幅度就越小
实现AdaGrad
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
最后一行微小值 1e-7是为了防止当self.h[key] 中有 0 时,将 0 用作除数的情况
这个微小值也可以设定为参数,但这里我们用的是 1e-7 这个固定值
Adam是将Momentum和AdaGrad融合在一起,可以实现实现参数空间的高效搜索,还可以进行超参数的“偏置校正”
实权重初始值都是像 0.01 * np.random.randn(10, 100) 等,使用由高斯分布生成的值乘以 0.01 后得到的值(标准差为 0.01 的高斯分布)
但不能将权重初始值设置为0
比如设第 1 层和第 2 层的权重为 0,正向传播时,因为输入层的权重为 0,所以第 2 层的神经元全部会被传递相同的值,第 2 层的神经元中全部输入相同的值,反向传播时第 2 层的权重全部都会进行相同的更新,这使得神经网络拥有许多不同的权重丧失意义
为了防止“权重均一化”必须随机生成初始值
Batch Norm
可以使学习快速进行
不那么依赖初始值
抑制过拟合
以进行学习时的 mini-batch 为单位,按 mini-batch 进行正规化(进行使数据分布的均值为 0、方差为 1 的正规化)
发生过拟合原因
模型拥有大量参数、表现力强
训练数据少
权值衰减是一直以来经常被使用的一种抑制过拟合的方法
该方法通过在学习的过程中对大的权重进行惩罚,来抑制过拟合(很多过拟合是因为权重参数取值过大发生的)
Dropout
损失函数加上权重的 L2 范数的权值衰减方法实现简单,在某种程度上能够抑制过拟合,但是,如果网络的模型变得很复杂,只用权值衰减就难以应对了,在这种情况下,我们可以使用 Dropout 方法
Dropout 是一种在学习的过程中随机删除神经元的方法,训练时,随机选出隐藏层的神经元,然后将其删除,被删除的神经元不再进行信号的传递
实现代码
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
每次正向传播时,self.mask 中都会以 False 的形式保存要删除的神经元,self.mask 会随机生成和 x 形状相同的数组,并将值比dropout_ratio 大的元素设为 True,反向传播时的行为和 ReLU 相同


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









