







文章目录
- 一,flink集群启动失败。
- 二,UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
- 三,javademo错误
- 四,flink wordcount没有输出
- 五,Hadoop is not in the classpath/dependencies.
- 六,结果写入hdfs报错
- 七,命令行提交per job报错
- 八,运行滚动窗口demo报错
- 九,使用flink sql时报错
- 十,使用flink sql报错
- 十一,BroadcastStream做多流合并时报空指针异常
- 十二,flink 用https连接es报错
- 十三,设置时间窗口后不起作用
- 十四,flink作业异常
- 十五,scala.Predef$.refArrayOps
- 十六 Provider org.apache.flink.connector.jdbc.catalog.factory.JdbcCatalogFactory not a subtype
- 十六,flink socket 流转换空指针异常
- 十七,设置watermark没有触发执行
- 十八,Could not forward element to next operator
- 十九:standalone集群起不来,任务提交不上
- 二十,flinck-cdc Connected to node3:3306 at mysql-bin.000003/154 (sid:6303, cid:103)
- 二十一,java.sql.SQLException: The connection property 'zeroDateTimeBehavior' only accepts values of the form: 'exception', 'round' or 'convertToNull'. The value 'CONVERT_TO_NULL' is not in this set.
- 二十二,flinkc-cdc读不到binlog日志
- 二十三,idea调试flink,启动后卡住不动
- 二十四,Flink 解决 No ExecutorFactory found to execute the application
- 二十五,'connector.type' expects 'filesystem', but is 'kafka'
- 二十六 Could not find required property 'connector.properties.bootstrap.servers'
- 二十七, The rowtime attribute can only replace a field with a valid time type, such as Timestamp or Long.
- 二十八,Caused by: java.lang.NullPointerException
- 二十九,but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed
- 三十, Could not complete snapshot 1 for operator Sink: kafka-sink (1/4)#0. Failure reason: Checkpoint was declined.
- 三十一, flinkcdc读取mysql,控制台一直打印下面日志,读不出日志
- 三十二,standalone模式下提交job报错
- 三十三,flink yarn-session模式下提交job失败
- 三十四,mysql开启binlog无效
- 35,设置并行度不生效
- 36,jobmanager报错:Flink异常:Could not acquire the minimum required resources.
一,flink集群启动失败。
原因:从node1分发到其他节点,在node1上建立了到flink的软连接,使用软连接来操作。分发到其他服务器后,并没有建立软连接。导致集群启动失败,甚至影响了虚拟机的运行,导致虚拟机假死。
二,UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
flink跑自带测试wordcount失败,报如上错误。

解决方案:
1,/etc/profile文件配置
export HADOOP_CLASSPATH=`hadoop classpath`
2,从下面地址下载一个jar包,上传到flink的lib目录下。
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/
3,重启flink集群。
三,javademo错误
1,
Flink java.lang.NoClassDefFoundError: org/apache/flink/api/common/functions/FlatMapFunction

解决办法:

2,
No ExecutorFactory found to execute the application
从Flink 1.11.0 开始flink-streaming-java不再依赖flink-client需要单独引用,那么增加相应依赖即可解决
解决办法,添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.0</version>
<scope>provided</scope>
</dependency>
20210518下午因为这个问题又搞了半天,都是jar包的问题。
3,Exception in thread "main" java.lang.NullPointerException: No execution.target specified in your configuration file.
原因:
不要使用new
解决方案:
StreamExecutionEnvironment senv=new StreamExecutionEnvironment();
改成:
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
四,flink wordcount没有输出
使用RuntimeExecutionMode.AUTOMATIC模式没有输出,原因不知。使用RuntimeExecutionMode.STREAMING正常输出。

五,Hadoop is not in the classpath/dependencies.
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:58)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:487)
... 23 more
解决办法:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
六,结果写入hdfs报错
结果写入hdfs报错,如果是权限问题,可以按照如下方式设置权限。
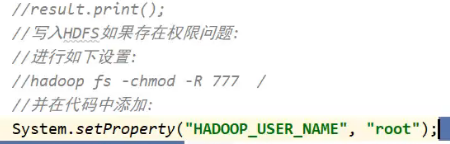
七,命令行提交per job报错
Failed to submit application_1619918841710_0003 to YARN : Application application_1619918841710_0003 submitted by user root to unknown queue: default
要指定yarn队列。
在命令行加 -yqu参数。
八,运行滚动窗口demo报错
Exception in thread "main" org.apache.flink.api.common.typeutils.CompositeType$InvalidFieldReferenceException: Cannot reference field by field expression on GenericType<UserActionLogPOJO>Field expressions are only supported on POJO types, tuples, and case classes. (See the Flink documentation on what is considered a POJO.)
at org.apache.flink.streaming.util.typeutils.FieldAccessorFactory.getAccessor(FieldAccessorFactory.java:193)
at org.apache.flink.streaming.api.functions.aggregation.ComparableAggregator.<init>(ComparableAggregator.java:67)
at org.apache.flink.streaming.api.datastream.KeyedStream.max(KeyedStream.java:836)
at Aggregate.main(Aggregate.java:52)
flink的POJO要实现无参和有参构造函数,set和get函数都要有。
九,使用flink sql时报错
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Exception in thread "main" org.apache.flink.table.api.TableException: Could not instantiate the executor. Make sure a planner module is on the classpath
at org.apache.flink.table.api.scala.internal.StreamTableEnvironmentImpl$.lookupExecutor(StreamTableEnvironmentImpl.scala:365)
at org.apache.flink.table.api.scala.internal.StreamTableEnvironmentImpl$.create(StreamTableEnvironmentImpl.scala:321)
at org.apache.flink.table.api.scala.StreamTableEnvironment$.create(StreamTableEnvironment.scala:425)
at com.lm.flink.dataset.table.TableToDataStream$.main(TableToDataStream.scala:31)
at com.lm.flink.dataset.table.TableToDataStream.main(TableToDataStream.scala)
Caused by: org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.delegation.ExecutorFactory' in
the classpath.
Reason: No factory supports the additional filters.
The following properties are requested:
class-name=org.apache.flink.table.planner.delegation.BlinkExecutorFactory
streaming-mode=true
The following factories have been considered:
org.apache.flink.table.executor.StreamExecutorFactory
at org.apache.flink.table.factories.ComponentFactoryService.find(ComponentFactoryService.java:71)
at org.apache.flink.table.api.scala.internal.StreamTableEnvironmentImpl$.lookupExecutor(StreamTableEnvironmentImpl.scala:350)
... 4 more
Process finished with exit code 1
网上说是要添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
其实是添加过的,不过在工程的依赖里面没找到,我猜是maven的问题,我把本地仓库对应的包删掉,然后refresh maven,之后就好使了。
十,使用flink sql报错
Exception in thread "main" org.apache.flink.table.api.ValidationException: Too many fields referenced from an atomic type.
at org.apache.flink.table.typeutils.FieldInfoUtils.extractFieldInfoFromAtomicType(FieldInfoUtils.java:445)
at org.apache.flink.table.typeutils.FieldInfoUtils.extractFieldInformation(FieldInfoUtils.java:277)
at org.apache.flink.table.typeutils.FieldInfoUtils.getFieldsInfo(FieldInfoUtils.java:242)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.lambda$asQueryOperation$0(StreamTableEnvironmentImpl.java:384)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl$$Lambda$224/951819642.apply(Unknown Source)
at java.util.Optional.map(Optional.java:215)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.asQueryOperation(StreamTableEnvironmentImpl.java:383)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.fromDataStream(StreamTableEnvironmentImpl.java:230)
at org.apache.flink.table.api.bridge.java.internal.StreamTableEnvironmentImpl.createTemporaryView(StreamTableEnvironmentImpl.java:262)
at flink.sql.TableSqlAPI.main(TableSqlAPI.java:36)
原因:POJO类必须要有无参构造器、有参构造器、get/set方法。
十一,BroadcastStream做多流合并时报空指针异常
Caused by: java.lang.NullPointerException
at flink.broadcast.BroadCastStream$1.processElement(BroadCastStream.java:59)
at flink.broadcast.BroadCastStream$1.processElement(BroadCastStream.java:51)
at org.apache.flink.streaming.api.operators.co.CoBroadcastWithNonKeyedOperator.processElement1(CoBroadcastWithNonKeyedOperator.java:98)
原因是两个流产生数据的时间不一致,需要判空。

十二,flink 用https连接es报错
参考文章flink连接es
连接失败,原因是SerializableCredentialsProvider这个类找不到,我用BasicCredentialsProvider,又报错说这个类不能序列化;
后来在stackoverflow找到一个方法:
十三,设置时间窗口后不起作用
给datastream设置水印后,应该用设置水印后新生成的datastream。
十四,flink作业异常
INFO executiongraph.ExecutionGraph: Source: Custom Source -> Filter -> Map (1/1) (eebbca70242517443aed5f427d7cb8b1) switched from RUNNING to FAILED
jdk版本的问题,将jdk改为jdk1.8.0_162就可以
十五,scala.Predef$.refArrayOps
2019-07-30 11:36:46,193 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint - Could not start cluster entrypoint YarnJobClusterEntrypoint.
org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint YarnJobClusterEntrypoint.
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:181)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:517)
at org.apache.flink.yarn.entrypoint.YarnJobClusterEntrypoint.main(YarnJobClusterEntrypoint.java:102)
Caused by: java.lang.Exception: Could not create actor system
at org.apache.flink.runtime.clusterframework.BootstrapTools.startActorSystem(BootstrapTools.java:276)
at org.apache.flink.runtime.clusterframework.BootstrapTools.startActorSystem(BootstrapTools.java:162)
at org.apache.flink.runtime.clusterframework.BootstrapTools.startActorSystem(BootstrapTools.java:121)
at org.apache.flink.runtime.clusterframework.BootstrapTools.startActorSystem(BootstrapTools.java:96)
at org.apache.flink.runtime.rpc.akka.AkkaRpcServiceUtils.createRpcService(AkkaRpcServiceUtils.java:78)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.createRpcService(ClusterEntrypoint.java:284)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.initializeServices(ClusterEntrypoint.java:255)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:207)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:163)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754)
at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:162)
... 2 more
Caused by: java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
at org.apache.flink.runtime.akka.AkkaUtils$.getRemoteAkkaConfig(AkkaUtils.scala:471)
at org.apache.flink.runtime.akka.AkkaUtils$.getAkkaConfig(AkkaUtils.scala:218)
at org.apache.flink.runtime.akka.AkkaUtils.getAkkaConfig(AkkaUtils.scala)
at org.apache.flink.runtime.clusterframework.BootstrapTools.startActorSystem(BootstrapTools.java:256)
... 15 more
原因是project setting设置的scala版本和flink-runtime的scala版本不一致。

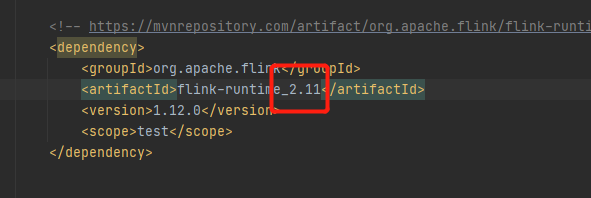
上图中的两个scala版本号要保持一致
十六 Provider org.apache.flink.connector.jdbc.catalog.factory.JdbcCatalogFactory not a subtype
使用flink sql 连接kafka报错。
Exception in thread "main" org.apache.flink.table.api.ValidationException: Unable to create a source for reading table 'default_catalog.default_database.input_kafka'.
Table options are:
'connector'='kafka'
'format'='json'
'properties.bootstrap.servers'='node1:9092'
'properties.group.id'='testGroup'
'scan.startup.mode'='latest-offset'
'topic'='input_kafka'
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:125)
at org.apache.flink.table.planner.plan.schema.CatalogSourceTable.createDynamicTableSource(CatalogSourceTable.java:265)
at org.apache.flink.table.planner.plan.schema.CatalogSourceTable.toRel(CatalogSourceTable.java:100)
at org.apache.calcite.sql2rel.SqlToRelConverter.toRel(SqlToRelConverter.java:3585)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertIdentifier(SqlToRelConverter.java:2507)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2144)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2093)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertFrom(SqlToRelConverter.java:2050)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertSelectImpl(SqlToRelConverter.java:663)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertSelect(SqlToRelConverter.java:644)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertQueryRecursive(SqlToRelConverter.java:3438)
at org.apache.calcite.sql2rel.SqlToRelConverter.convertQuery(SqlToRelConverter.java:570)
at org.apache.flink.table.planner.calcite.FlinkPlannerImpl.org$apache$flink$table$planner$calcite$FlinkPlannerImpl$$rel(FlinkPlannerImpl.scala:165)
at org.apache.flink.table.planner.calcite.FlinkPlannerImpl.rel(FlinkPlannerImpl.scala:157)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.toQueryOperation(SqlToOperationConverter.java:823)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.convertSqlQuery(SqlToOperationConverter.java:795)
at org.apache.flink.table.planner.operations.SqlToOperationConverter.convert(SqlToOperationConverter.java:250)
at org.apache.flink.table.planner.delegation.ParserImpl.parse(ParserImpl.java:78)
at org.apache.flink.table.api.internal.TableEnvironmentImpl.sqlQuery(TableEnvironmentImpl.java:639)
at flink.sql.TableSqlKafka.main(TableSqlKafka.java:44)
Caused by: org.apache.flink.table.api.TableException: Could not load service provider for factories.
at org.apache.flink.table.factories.FactoryUtil.discoverFactories(FactoryUtil.java:423)
at org.apache.flink.table.factories.FactoryUtil.discoverFactory(FactoryUtil.java:226)
at org.apache.flink.table.factories.FactoryUtil.getDynamicTableFactory(FactoryUtil.java:370)
at org.apache.flink.table.factories.FactoryUtil.createTableSource(FactoryUtil.java:118)
... 19 more
Caused by: java.util.ServiceConfigurationError: org.apache.flink.table.factories.Factory: Provider org.apache.flink.connector.jdbc.catalog.factory.JdbcCatalogFactory not a subtype
at java.util.ServiceLoader.fail(ServiceLoader.java:239)
at java.util.ServiceLoader.access$300(ServiceLoader.java:185)
at java.util.ServiceLoader$LazyIterator.nextService(ServiceLoader.java:376)
at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:404)
at java.util.ServiceLoader$1.next(ServiceLoader.java:480)
at java.util.Iterator.forEachRemaining(Iterator.java:116)
at org.apache.flink.table.factories.FactoryUtil.discoverFactories(FactoryUtil.java:419)
... 22 more
Disconnected from the target VM, address: '127.0.0.1:64363', transport: 'socket'
Process finished with exit code 1
错误原因,缺少jar包。
pom中加入:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
十六,flink socket 流转换空指针异常
是因为用错了Tuple2类
十七,设置watermark没有触发执行
最近在公司使用flink做项目,在本地idea中开发时,waterMark设置正确,但是窗口一直没有被触发,因为任务并行执行时,总是以最小的waterMark为准的,而我本地没有设置并行度,默认使用windows的并行度,导致窗口一直没有被触发,所以在本地开发时,将并行度设置为1
十八,Could not forward element to next operator
执行下面代码时报错:

org.apache.flink.streaming.runtime.tasks.ExceptionInChainedOperatorException: Could not forward element to next operator
at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.pushToOperator(OperatorChain.java:654)
at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:612)
at org.apache.flink.streaming.runtime.tasks.OperatorChain$CopyingChainingOutput.collect(OperatorChain.java:592)
原因是collector收集的数据需要序列化,但是PriorityQueue的父类没有实现序列化接口
解决方案:用数组代替Queue
collector.collect(new AggOrderPojo[]{queue.poll(),queue.poll(),queue.poll()});
十九:standalone集群起不来,任务提交不上
2021-12-10 06:32:41,609 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Could not start cluster entrypoint StandaloneSessionClusterEntrypoint.
org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint StandaloneSessionClusterEntrypoint.
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:191) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runClusterEntrypoint(ClusterEntrypoint.java:529) [flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint.main(StandaloneSessionClusterEntrypoint.java:56) [flink-dist_2.12-1.12.0.jar:1.12.0]
Caused by: org.apache.flink.util.FlinkException: Could not create the DispatcherResourceManagerComponent.
at org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory.create(DefaultDispatcherResourceManagerComponentFactory.java:257) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:220) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:173) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_241]
at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_241]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) ~[flink-shaded-hadoop-2-uber-2.7.5-10.0.jar:2.7.5-10.0]
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:172) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
... 2 more
Caused by: java.net.BindException: Could not start rest endpoint on any port in port range 8081
at org.apache.flink.runtime.rest.RestServerEndpoint.start(RestServerEndpoint.java:222) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.component.DefaultDispatcherResourceManagerComponentFactory.create(DefaultDispatcherResourceManagerComponentFactory.java:162) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.runCluster(ClusterEntrypoint.java:220) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.lambda$startCluster$0(ClusterEntrypoint.java:173) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_241]
at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_241]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1754) ~[flink-shaded-hadoop-2-uber-2.7.5-10.0.jar:2.7.5-10.0]
at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
at org.apache.flink.runtime.entrypoint.ClusterEntrypoint.startCluster(ClusterEntrypoint.java:172) ~[flink-dist_2.12-1.12.0.jar:1.12.0]
... 2 more
- 8081的端口被占用,启动webui失败
- hdfs的端口不是8020,改成了8080
二十,flinck-cdc Connected to node3:3306 at mysql-bin.000003/154 (sid:6303, cid:103)
flinkcdc读取mysql日志,发现一直打印如下日志:
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:6303, cid:103)
十二月 15, 2021 7:36:38 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:5547, cid:106)
十二月 15, 2021 7:36:43 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:6104, cid:109)
十二月 15, 2021 7:36:50 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:5467, cid:112)
十二月 15, 2021 7:36:57 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:5906, cid:115)
十二月 15, 2021 7:37:03 上午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to node3:3306 at mysql-bin.000003/154 (sid:5568, cid:118)
原因是自定义序列化器有空指针异常,需要判空。
如下,获取before后,要判断before不等于null,否则会有异常。
Struct before = value.getStruct("before");
List<Field> fields = null;
JSONObject beforeJson = new JSONObject();
if (before != null) {
fields = before.schema().fields();
fields.forEach(field -> {
Object v = before.get(field.name());
beforeJson.put(field.name(), v);
});
}
二十一,java.sql.SQLException: The connection property ‘zeroDateTimeBehavior’ only accepts values of the form: ‘exception’, ‘round’ or ‘convertToNull’. The value ‘CONVERT_TO_NULL’ is not in this set.
原因:使用CDC抓取mysqlbinlog日志,报如上错误,原因是在flink的lib目录下,有一个flink的connector的jar依赖了mysql的驱动包是mysql 5.1版本的,而mysql服务器是5.7版本。
解决办法:重新对connector打包,打包时不打包mysql的驱动包
二十二,flinkc-cdc读不到binlog日志
指定读取某个表的日志,读不出任何内容,以下原因:
- 数据库指定错误
- 表名没有添加数据库限定名,如下注释
DebeziumSourceFunction<String> debeziumSourceFunction = MySQLSource.<String>builder()
.hostname("node3")
.port(3306)
.databaseList("mall-flink")
// 表名前一定要加数据库名称
.tableList("mall-flink.process")
.startupOptions(StartupOptions.initial())
.username("root")
.password("123456")
.deserializer(new CustomerTalbeDeserialization())
.build();
二十三,idea调试flink,启动后卡住不动
flink消费kafka,启动后卡住不动,也不报错。
原因是默认kafka是从消息的最新offset开始消费,如果没有新消息进入kafka,就不会有反应。
设置kafka消费者从尽可能早的消息处开始消费
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("hudi_ods_enterprise_config", new SimpleStringSchema(), prop);
consumer.setStartFromEarliest();
二十四,Flink 解决 No ExecutorFactory found to execute the application
从flink 1.11开始报错:
解决:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.12.0</version>
</dependency>
二十五,‘connector.type’ expects ‘filesystem’, but is ‘kafka’
Reason: Required context properties mismatch.
The matching candidates:
org.apache.flink.table.sources.CsvAppendTableSourceFactory
Mismatched properties:
'connector.type' expects 'filesystem', but is 'kafka'
The following properties are requested:
connector.properties.connector.properties.bootstrap.servers=node1:9092
connector.properties.group.id=click-group
connector.properties.zookeeper.connect=node1:2181
connector.property-version=1
connector.startup-mode=earliest-offset
二十六 Could not find required property ‘connector.properties.bootstrap.servers’
如下,写property时无需写全’connector.properties.bootstrap.servers’
streamTableEnvironment.connect(
new Kafka()
.property("zookeeper.connect","node1:2181")
.property("bootstrap.servers","node1:9092")
.version("universal")
.topic("sku")
.property("group.id", "click-group")
.startFromEarliest())
.withFormat(new Csv())
.withSchema(
new Schema()
.field("sku", "STRING")
.field("price", "double")
.field("proc-time", "TIMESTAMP(3)"))
.inAppendMode()
.createTemporaryTable("MyTable");
streamTableEnvironment.executeSql("select * from MyTable").print();
二十七, The rowtime attribute can only replace a field with a valid time type, such as Timestamp or Long.
streamTableEnvironment.connect(new FileSystem().path(Constants.path))
.withFormat(new Csv())
.withSchema(new Schema()
.field("sku","varchar")
.field("price","double")
.field("ts","timestamp")
).createTemporaryTable("first_table");
Table table = streamTableEnvironment.sqlQuery("select sku, ts,price from first_table");
DataStream<Row> rowDataStream = streamTableEnvironment.toAppendStream(table, Row.class);
rowDataStream.print();
streamTableEnvironment.fromDataStream(rowDataStream,"sku,ts,price,ts.rowtime as rt").printSchema();
executionEnvironment.execute();
以上代码执行到设置rowtime时报错,原因是ts字段设置为timestamp,被系统识别为timestamp(6),timestamp(6)是13位时间戳,而eventtime是10位时间戳。
解决方案是先将ts作为string,然后转换为timestamp。
streamTableEnvironment.connect(new FileSystem().path(Constants.path))
.withFormat(new Csv())
.withSchema(new Schema()
.field("sku","varchar")
.field("price","double")
.field("ts","string")
).createTemporaryTable("first_table");
Table table = streamTableEnvironment.sqlQuery("select sku, ts,price from first_table");
DataStream<Row> rowDataStream = streamTableEnvironment.toAppendStream(table, Row.class);
rowDataStream.print();
streamTableEnvironment.fromDataStream(rowDataStream,"sku,ts,price,ts.rowtime as rt").printSchema();
executionEnvironment.execute();
二十八,Caused by: java.lang.NullPointerException
使用SQL开窗报错:
at SourceConversion$20.processElement(Unknown Source)
at org.apache.flink.streaming.runtime.tasks.CopyingChainingOutput.pushToOperator(CopyingChainingOutput.java:71)
开窗之前要设置watermark指定事件时间字段
SingleOutputStreamOperator<Row> rowSingleOutputStreamOperator = rowDataStream.assignTimestampsAndWatermarks(WatermarkStrategy.<Row>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(new SerializableTimestampAssigner<Row>() {
@Override
public long extractTimestamp(Row row, long l) {
return Long.parseLong(row.getField(1) + "");
}
}));
rowDataStream.print();
Table table1 = streamTableEnvironment.fromDataStream(rowSingleOutputStreamOperator, "sku,ts,price,ts.rowtime as rt");
二十九,but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed
完整报错如下:
-“trace”:"io.debezium.DebeziumException: The connector is trying to read binlog starting at SourceInfo [currentGtid=null, currentBinlogFilename=mysql-bin-changelog.210858, currentBinlogPosition=384, currentRowNumber=0, serverId=0, sourceTime=null, threadId=-1, currentQuery=null, tableIds=[], databaseName=null], but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed.
这里的原因是在启动flink-cdc时指定了savepoint地址,而这个savepoint地址是历史数据,导致其中保存的点位在mysqlbinlog中不存在。
三十, Could not complete snapshot 1 for operator Sink: kafka-sink (1/4)#0. Failure reason: Checkpoint was declined.
2022-01-12 17:57:21,484 WARN org.apache.flink.runtime.taskmanager.Task [] - Sink: kafka-sink (2/4)#0 (e21f054a9390ede788631fe9d5855051) switched from RUNNING to FAILED with failure cause: java.io.IOException: Could not perform checkpoint 1 for operator Sink: kafka-sink (2/4)#0.
at org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:1048)
at org.apache.flink.streaming.runtime.io.checkpointing.CheckpointBarrierHandler.notifyCheckpoint(CheckpointBarrierHandler.java:135)
at org.apache.flink.streaming.runtime.io.checkpointing.SingleCheckpointBarrierHandler.triggerCheckpoint(SingleCheckpointBarrierHandler.java:250)
at org.apache.flink.streaming.runtime.io.checkpointing.SingleCheckpointBarrierHandler.access$100(SingleCheckpointBarrierHandler.java:61)
at org.apache.flink.streaming.runtime.io.checkpointing.SingleCheckpointBarrierHandler$ControllerImpl.triggerGlobalCheckpoint(SingleCheckpointBarrierHandler.java:431)
at org.apache.flink.streaming.runtime.io.checkpointing.AbstractAlignedBarrierHandlerState.barrierReceived(AbstractAlignedBarrierHandlerState.java:61)
at org.apache.flink.streaming.runtime.io.checkpointing.SingleCheckpointBarrierHandler.processBarrier(SingleCheckpointBarrierHandler.java:227)
at org.apache.flink.streaming.runtime.io.checkpointing.CheckpointedInputGate.handleEvent(CheckpointedInputGate.java:180)
at org.apache.flink.streaming.runtime.io.checkpointing.CheckpointedInputGate.pollNext(CheckpointedInputGate.java:158)
at org.apache.flink.streaming.runtime.io.AbstractStreamTaskNetworkInput.emitNext(AbstractStreamTaskNetworkInput.java:110)
at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:66)
at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:423)
at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:204)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:684)
at org.apache.flink.streaming.runtime.tasks.StreamTask.executeInvoke(StreamTask.java:639)
at org.apache.flink.streaming.runtime.tasks.StreamTask.runWithCleanUpOnFail(StreamTask.java:650)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:623)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:779)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:566)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.runtime.checkpoint.CheckpointException: Could not complete snapshot 1 for operator Sink: kafka-sink (2/4)#0. Failure reason: Checkpoint was declined.
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.snapshotState(StreamOperatorStateHandler.java:264)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.snapshotState(StreamOperatorStateHandler.java:169)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.snapshotState(AbstractStreamOperator.java:371)
at org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl.checkpointStreamOperator(SubtaskCheckpointCoordinatorImpl.java:706)
at org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl.buildOperatorSnapshotFutures(SubtaskCheckpointCoordinatorImpl.java:627)
at org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl.takeSnapshotSync(SubtaskCheckpointCoordinatorImpl.java:590)
at org.apache.flink.streaming.runtime.tasks.SubtaskCheckpointCoordinatorImpl.checkpointState(SubtaskCheckpointCoordinatorImpl.java:312)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$performCheckpoint$8(StreamTask.java:1092)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$1.runThrowing(StreamTaskActionExecutor.java:50)
at org.apache.flink.streaming.runtime.tasks.StreamTask.performCheckpoint(StreamTask.java:1076)
at org.apache.flink.streaming.runtime.tasks.StreamTask.triggerCheckpointOnBarrier(StreamTask.java:1032)
... 19 more
Caused by: org.apache.flink.streaming.connectors.kafka.FlinkKafkaException: Failed to send data to Kafka: Expiring 4 record(s) for hudi_ods_enterprise_config-2:120001 ms has passed since batch creation
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.checkErroneous(FlinkKafkaProducer.java:1392)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.flush(FlinkKafkaProducer.java:1095)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.preCommit(FlinkKafkaProducer.java:1002)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.preCommit(FlinkKafkaProducer.java:99)
at org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction.snapshotState(TwoPhaseCommitSinkFunction.java:320)
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.snapshotState(FlinkKafkaProducer.java:1100)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.trySnapshotFunctionState(StreamingFunctionUtils.java:118)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.snapshotFunctionState(StreamingFunctionUtils.java:99)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.snapshotState(AbstractUdfStreamOperator.java:89)
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.snapshotState(StreamOperatorStateHandler.java:218)
原因未知,topic delete后重建后恢复正常
三十一, flinkcdc读取mysql,控制台一直打印下面日志,读不出日志
Connected to 10.49.2.147:3306 at d53e7f94-2fea-11ec-a449-043f72a8d2e5:1-5,f5959b13-2fea-11ec-9591-0c42a14a1f10:1-1531675633 (sid:9001, cid:182455949)
一月 12, 2022 5:44:30 下午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to 10.49.2.147:3306 at d53e7f94-2fea-11ec-a449-043f72a8d2e5:1-5,f5959b13-2fea-11ec-9591-0c42a14a1f10:1-1531675901 (sid:9001, cid:182455963)
一月 12, 2022 5:44:31 下午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to 10.49.2.147:3306 at d53e7f94-2fea-11ec-a449-043f72a8d2e5:1-5,f5959b13-2fea-11ec-9591-0c42a14a1f10:1-1531676157 (sid:9001, cid:182455970)
一月 12, 2022 5:44:32 下午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to 10.49.2.147:3306 at d53e7f94-2fea-11ec-a449-043f72a8d2e5:1-5,f5959b13-2fea-11ec-9591-0c42a14a1f10:1-1531676426 (sid:9001, cid:182455972)
一月 12, 2022 5:44:33 下午 com.github.shyiko.mysql.binlog.BinaryLogClient connect
信息: Connected to 10.49.2.147:3306 at d53e7f94-2fea-11ec-a449-043f72a8d2e5:1-5,f5959b13-2fea-11ec-9591-0c42a14a1f10:1-1531676662 (sid:9001, cid:182455976)

解决:
env.setParallelism(4);
三十二,standalone模式下提交job报错
在webui上提交job后,job没启动成功,看日志,有如下报错:
NoResourceAvailableException: Could not acquire the minimum required resources
意思是获取不到最低要求资源。
集群只有2个结点,两个taskmanger,每个结点配置了一个taskslot,而job有个算子设置了并行度是3,所以资源不足。
解决:1,所有算子并行度不能大于2;
或者2,配置文件taskslot设置为大于1.
flink-conf.yaml
taskmanager.numberOfTaskSlots: 3
三十三,flink yarn-session模式下提交job失败
使用flink-yarn-session模式提交job,job失败,报错:
Connect refused
at org.apache.flink.streaming.api.functions.source.SocketTextStreamFunction.run
原因flinkjob使用socket数据源,对应的socket服务没有开启,在对应的服务器上开启服务即可解决,如:
nc -lk 9999
三十四,mysql开启binlog无效
应该是/etc/my.cnf配置的问题:
[mysqld]
server-id=1
#log-bin=/usr/local/mysql/log-bin/mysql-bin
log-bin=mysql-bin
binlog-do-db=gmall
#binlog-do-db=test
35,设置并行度不生效
原因是taskmanager只有一个slot,在flink-conf配置文件中设置slot为更大的值。
36,jobmanager报错:Flink异常:Could not acquire the minimum required resources.
资源不足,其实是slot数量不足,假设taskmanager有10个slot,一个job要5个slot,第三个提交时就会报错,资源不足。
















 1633
1633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











