







 Spark的血统(lineage)机制是其容错的基础,描述了RDD之间的依赖关系,分为宽依赖和窄依赖。宽依赖中父RDD分区数据分散到多个子RDD分区,而窄依赖则是一对一的分区传递。当任务失败时,通过血统回溯到未出错的父RDD,重新计算以实现容错。
Spark的血统(lineage)机制是其容错的基础,描述了RDD之间的依赖关系,分为宽依赖和窄依赖。宽依赖中父RDD分区数据分散到多个子RDD分区,而窄依赖则是一对一的分区传递。当任务失败时,通过血统回溯到未出错的父RDD,重新计算以实现容错。
你是如何理解Spark中血统(lineage)的概念?
- lineage 是spark容错的机制的基础,它描述RDD之间的不同依赖关系,记录子RDD是如何从其它RDD中演变过来的,分为宽依赖和窄依赖。
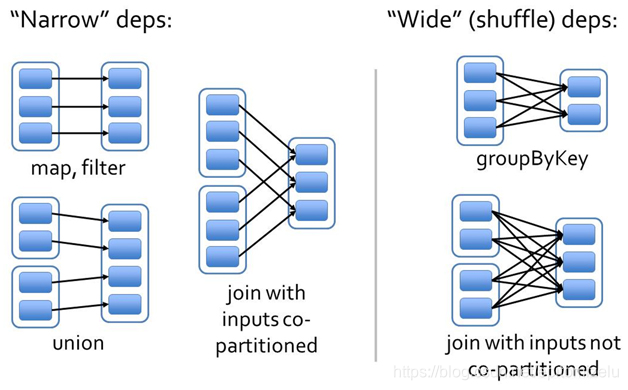
- 宽依赖:父RDD的分区数据会分发到子RDD的多个分区
- 窄依赖:父RDD的分区数据会分发到子RDD的一个分区
它的作用是什么?
主要作用是容错。当一个节点的任务失败时,通过血统关系追溯到未发生错误的父RDD,针对父RDD的分区重新计算。
你是如何理解Spark中血统(lineage)的概念?
它的作用是什么?
主要作用是容错。当一个节点的任务失败时,通过血统关系追溯到未发生错误的父RDD,针对父RDD的分区重新计算。
 1906
300
408
346
1906
300
408
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























