









在实际工作中,性能调优是必不可少的,虽然业务千种百样,实际落地的解决方案可能也不尽相同,但归根结底,调优的最终目的是使得内存、CPU、IO均衡而没有瓶颈。
基本上,思路都是结合实际业务、数据量从硬件出发,考虑如何充分利用CPU、内存、IO。
除了对业务的理解之外,对于Spark本身的机制也要深入理解,这样才能通过各种调整,充分发挥Spark的优势,达成调优的目的。
下面以一个案例尝试总结常用的Spark调优思路和实践。
案例数据来源极客时间Spark 性能调优实战,数据地址百度网盘,提取码 ajs6 。
数据结构如下所示:
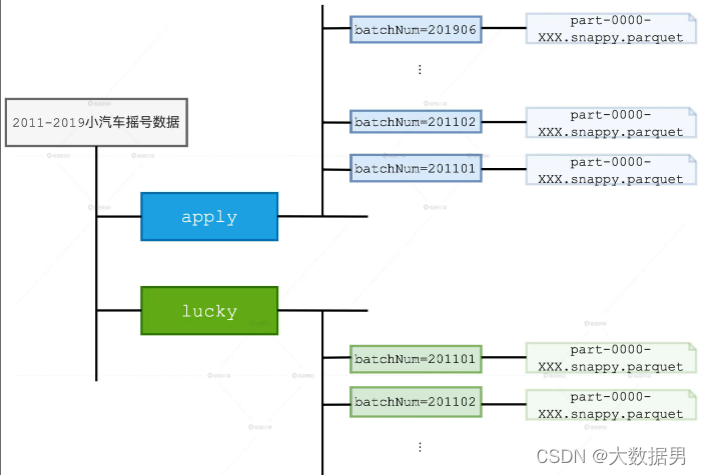
数据分为两部分:
- ①apply文件夹下是摇号者数据,一月抽一次,称之为一个批次batchNum
- ②lucky文件下是成功摇到车牌的幸运儿
- ③以parquet文件作为存储格式
- ④数据只有两列:batchNum:批次号,carNum:车牌号
- ⑤对于同一个申请者,多次申请会以重复记录出现在之后的批次中,即如果一个申请者已经申请过2次,则在下一次申请时,这个申请者会有三条申请数据,以提高多次申请者的中号概率
下载数据,导入到HDFS;
一,认识数据
1,Schema和数据量
代码:
val spark = SparkSession
.builder
.appName("SkewTestApp")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.debug.maxToStringFields", "100")
.getOrCreate
val rootPath: String = "hdfs://HD1/data"
// 申请者数据(因为倍率的原因,每一期,同一个人,可能有多个号码)
val hdfs_path_apply = s"${rootPath}/apply"
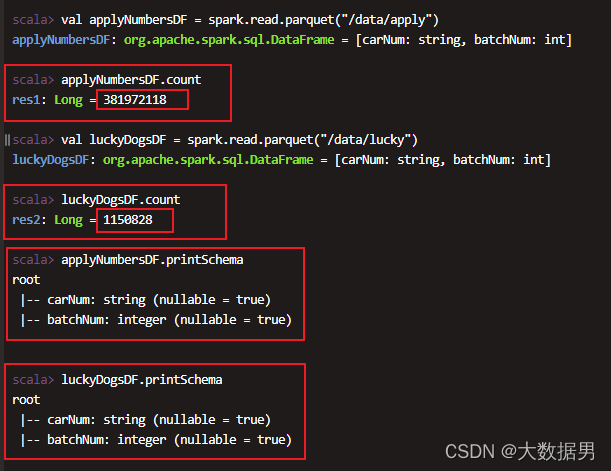
val applyNumbersDF = spark.read.parquet(hdfs_path_apply)
// 中签者数据
val hdfs_path_lucky = s"${rootPath}/lucky"
val luckyDogsDF = spark.read.parquet(hdfs_path_lucky)
结果:
- 申请摇号的数据大约有3.8亿
- 摇中的幸运儿115万
- 两份数据都是两个字段:carNum,batchNum
二,第一个案例:摇号次数与摇号人数
1,目标:统计每个申请者的摇号次数,统计各个摇号次数的人数
2,数据预处理
因为每个批次的数据还包含了反映申请者历史申请次数的重复数据,所以首先要在批次内对重复数据去重:
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
3,每个摇号次数对应的人数
import org.apache.spark.sql.functions._
val result = applyDistinctDF
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis"))
.agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
println(s"result.count:${result.count}")
result.write.format("csv").save("geektime/result/")
4,资源
spark-submit --master yarn --num-executors 1 --executor-cores 4 --executor-memory 20g --deploy-mode cluster --class com.app.test.GeekTimeProgramTest2 gt-1.0-SNAPSHOT.jar
5,结果
耗时: 4min31s
6,优化1-提高并行度
从SparkUI可以看到,Spark的任务并行度很高:72

但我们给的资源有限,只有4个并行度,显然,在执行的过程中会有大量的任务排队,所以,第一个思路,增加资源,扩大并行度:
spark-submit --master yarn --num-executors 2 --executor-cores 10 --executor-memory 20g --class com.app.test.CreateSkewDataExampleNoBroadcast2 cnter-1.0-SNAPSHOT.jar
将集群并行度扩大到 2 * 10 = 20 后,耗时变成了 **耗时: 1min31s**,耗时降低了2/3。
总结:数据并行度高但集群资源并行度低时,增加集群并行度是简单而且有效的方式。
三,第二个案例:中号人的摇号次数与人数
1,目标:在第一个需求之后,统计每个摇中者的摇号次数,统计各个摇号次数的人数
2,数据预处理
因为每个批次的数据还包含了反映申请者历史申请次数的重复数据,所以首先要在批次内对重复数据去重:
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
3,每个摇号次数对应的人数
val result = applyDistinctDF
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis"))
.agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result.write.format("csv").save("geektime/result/")
val result02 = applyDistinctDF
.join(luckyDogsDF.select("carNum"), Seq("carNum"), "inner")
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1))
.alias("y_axis"))
.orderBy("x_axis")
result02.write.format("csv").save("geektime/result02/")
4,资源
并行度:20
spark-submit --master yarn --num-executors 2 --executor-cores 10 --executor-memory 20g --deploy-mode cluster --class com.app.test.GeekTimeProgramTest2 gt-1.0-SNAPSHOT.jar
执行耗时:1mins, 36sec
5,优化1: cache
我们发现applyDistinctDF被使用了两次,在得到applyDistinctDF的过程中使用了distinct,这是一个耗时的算子,如果把applyDistinctDF缓存即调用cache方法,减少一次applyDistinctDF的计算。
applyDistinctDF.cache()
applyDistinctDF.count()
val result = applyDistinctDF
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis"))
.agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result.write.format("csv").save("geektime/result/")
val result02 = applyDistinctDF
.join(luckyDogsDF.select("carNum"), Seq("carNum"), "inner")
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1))
.alias("y_axis"))
.orderBy("x_axis")
result02.write.format("csv").save("geektime/result02/")
执行耗时:1mins, 23sec
优化后,性能提升不明显,应该是我们使用的数据集还不够大。
6,优化2: 使用广播
在求得Result2的过程中,使用了join,在另一篇文章中总结过spark的多种join方式,其中BroadcastJoin是在性能调优中值得考虑的一种优化手段,要使用BroadcastJoin有如下方式:
- ①在配置中设置Broadcast的阈值范围,只要在这个范围内,Spark会自动选择BroadcastJoin
- ②在spark sql中使用Hint
这里采用第一种方式:
.config("spark.sql.autoBroadcastJoinThreshold","2073741824")
val spark = SparkSession
.builder
.appName("SkewTestApp")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.adaptive.enabled", "true")
.config("spark.sql.debug.maxToStringFields", "100")
.config("spark.sql.autoBroadcastJoinThreshold","2073741824")
.getOrCreate
val result = applyDistinctDF
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis"))
.agg(count(lit(1)).alias("y_axis"))
.orderBy("x_axis")
result.write.format("csv").save("geektime/result/")
val result02 = applyDistinctDF
.join(luckyDogsDF.select("carNum"), Seq("carNum"), "inner")
.groupBy(col("carNum"))
.agg(count(lit(1)).alias("x_axis"))
.groupBy(col("x_axis")).agg(count(lit(1))
.alias("y_axis"))
.orderBy("x_axis")
result02.write.format("csv").save("geektime/result02/")

执行耗时:1mins, 16sec
优化后,性能提升不明显,应该是我们使用的数据集还不够大。
四,第三个案例:计算每期的中签率
1,目标:统计出每期的申请人数,统计每期的中号人数,二者关联相除,得到中签率
2,代码
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
import org.apache.spark.sql.functions._
val lucky_molecule_2018 = luckyDogsDF
.groupBy(col("batchNum"))
.agg(count(lit(1)).alias("molecule"))
// 通过与筛选出的中签数据按照批次做关联,计算每期的中签率
val apply_denominator = applyDistinctDF
.groupBy(col("batchNum"))
.agg(count(lit(1))
.alias("denominator"))
val result04 = apply_denominator
.join(lucky_molecule_2018, Seq("batchNum"), "inner")
.withColumn("ratio", round(col("molecule")/col("denominator"), 5))
.orderBy("batchNum")
result04.write.format("csv").save("/data/res/geektime/result4/")
执行耗时:47sec
3,优化1:DPP动态分区裁剪
DPP(Dynamic Partition Pruning,动态分区剪裁)是 Spark3的新特性,简单说就是根据维表的过滤条件对事实表进行分区过滤,类似于列裁剪,用来降低磁盘IO。
满足下列三个条件,Spark即会进行DPP优化:
- ①事实表必须是分区表,并且分区字段必须包含 Join Key
- ②动态分区剪裁只支持等值 Joins,不支持大于、小于这种不等值关联关系
- ③维度表过滤之后的数据集,必须要小于广播阈值,因此,开发者要注意调整配置项 spark.sql.autoBroadcastJoinThreshold
所以,在维表即lucky表添加过滤条件:
.filter(col("batchNum").like("2018%"))
再加上hdfs上存储的事实表数据apply是以batchNum分区的,而lucky表在过滤后可以满足广播的条件。
所以,满足了动态DPP的条件。
val applyDistinctDF = applyNumbersDF.select("batchNum", "carNum").distinct
import org.apache.spark.sql.functions._
val lucky_molecule_2018 = luckyDogsDF
.filter(col("batchNum").like("2018%"))
.groupBy(col("batchNum"))
.agg(count(lit(1)).alias("molecule"))
// 通过与筛选出的中签数据按照批次做关联,计算每期的中签率
val apply_denominator = applyDistinctDF
.groupBy(col("batchNum"))
.agg(count(lit(1))
.alias("denominator"))
val result04 = apply_denominator
.join(lucky_molecule_2018, Seq("batchNum"), "inner")
.withColumn("ratio", round(col("molecule")/col("denominator"), 5))
.orderBy("batchNum")
result04.write.format("csv").save("/data/res/geektime/result4/")
执行耗时:26sec
耗时减小了50%,性能得到了可观的提升。
4,总结
结合业务,减小要扫描的数据范围,从而减小磁盘IO和网络IO以及计算量,能够大幅提升作业性能。其中DPP能够自动的执行这些过程,但要满足3个条件。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











