







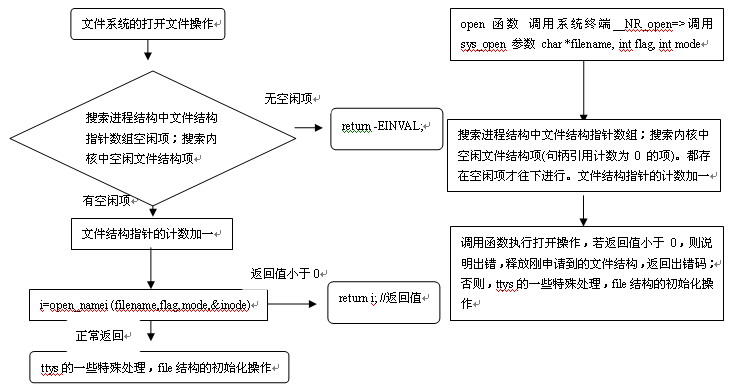
从linux 0.11种可以清晰地看出文件操作的底层处理流程:
1、 文件打开操作的系统调用:
2、 open_namei函数
// 这是在内存中的i 节点结构。前7 项与d_inode(磁盘上的i节点结构) 完全一样。
struct m_inode
{
unsigned short i_mode; // 文件类型和属性(rwx 位)。
unsigned short i_uid; // 用户id(文件拥有者标识符)。
unsigned long i_size; // 文件大小(字节数)。
unsigned long i_mtime; // 修改时间(自1970.1.1:0 算起,秒)。
unsigned char i_gid; // 组id(文件拥有者所在的组)。
unsigned char i_nlinks; // 文件目录项链接数。
unsigned short i_zone[9]; // 直接(0-6)、间接(7)或双重间接(8)逻辑块号。
/* these are in memory also */
struct task_struct *i_wait; // 等待该i 节点的进程。
unsigned long i_atime; // 最后访问时间。
unsigned long i_ctime; // i 节点自身修改时间。
unsigned short i_dev; // i 节点所在的设备号。
unsigned short i_num; // i 节点号。
unsigned short i_count; // i 节点被使用的次数,0 表示该i 节点空闲。
unsigned char i_lock; // 锁定标志。
unsigned char i_dirt; // 已修改(脏)标志。
unsigned char i_pipe; // 管道标志。
unsigned char i_mount; // 安装标志。
unsigned char i_seek; // 搜寻标志(lseek 时)。
unsigned char i_update; // 更新标志。
};
// 缓冲区头数据结构。(极为重要!!!)
// 在程序中常用bh 来表示buffer_head 类型的缩写。
struct buffer_head
{
char *b_data; /* pointer to data block (1024 bytes) *///指针。
unsigned long b_blocknr; /* block number */// 块号。
unsigned short b_dev; /* device (0 = free) */// 数据源的设备号。
unsigned char b_uptodate; // 更新标志:表示数据是否已更新。
unsigned char b_dirt; /* 0-clean,1-dirty *///修改标志:0 未修改,1 已修改.
unsigned char b_count; /* users using this block */// 使用的用户数。
unsigned char b_lock; /* 0 - ok, 1 -locked */// 缓冲区是否被锁定。
struct task_struct *b_wait; // 指向等待该缓冲区解锁的任务。
struct buffer_head *b_prev; // hash 队列上前一块(这四个指针用于缓冲区的管理)。
struct buffer_head *b_next; // hash 队列上下一块。
struct buffer_head *b_prev_free; // 空闲表上前一块。
struct buffer_head *b_next_free; // 空闲表上下一块。
};
// 文件目录项结构。
struct dir_entry
{
unsigned short inode; // i 节点。
char name[NAME_LEN]; // 文件名。
};
首先,给定文件的全路径名。
根据这个全路径名把文件加载到内存中进行操作,以下是操作步骤:
a、判断是绝对路径还是相对路径,从当前进程的task_struct中取出相应的根目录
绝对的就取 inode = current->root; 相对的:inode = current->pwd; (struct m_inode *inode;)
b、对路径中的目录依次做如下循环找出下一级目录是否在上一级目录中,并返回dir_entry
以供下一级循环使用,每个目录的引用数加一
i、找到上一级目录的文件内容所在的缓存块开始查找block = (*dir)->i_zone[0]) //i_zone[0]代表目录内容的入口块;bh = bread ((*dir)->i_dev, block)//从磁盘中把这个块读到缓冲区中(如果可用就不用读了,直接使用)
ii、使用match (namelen, name, de)逐个的拼配,来查找上一级目录中是否存在要查找的下一级目录名如果存在返回查找到的dir_entry
iii、循环结束的条件是:已经遍历了超过entries 数目dir_entry(说明没有找到);或者找到推出循环
//entries = (*dir)->i_size / (sizeof (struct dir_entry)); 其中如果当前的bh已经查完进入下一个bh(目录的内容可能很多超过了一个块的容量)按如下操作来获取新的bh block = bmap (*dir, i / DIR_ENTRIES_PER_BLOCK) bh = bread ((*dir)->i_dev, block)
c、再到找到的最后一级目录中找出文件的entry,最后通过 iget (dev, inr)获取inode,如果找不到创建一个文件即可inode = new_inode (dir->i_dev);
// 否则使用该新i 节点,对其进行初始设置:置节点的用户id;对应节点访问模式;置已修改标志。
inode->i_uid = current->euid;
inode->i_mode = mode;
inode->i_dirt = 1;
// 然后在指定目录dir 中添加一新目录项。
bh = add_entry (dir, basename, namelen, &de);
最后初始化file结构
f->f_mode = inode->i_mode;
f->f_flags = flag;
f->f_count = 1;
f->f_inode = inode;
f->f_pos = 0;
这样所有的操作完成















 2421
2421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









