






迁移学习 (Transfer Learning,TL)
2005年,杨强提出了迁移学习的概念,目标是让计算机把大数据领域习得的知识和方法迁移到数据不那么多的领域,这样,计算机也可以“举一反三”“触类旁通”,而不必在每个领域都依赖大数据从头学起。
迁移学习,对于人类来说,就是掌握举一反三的学习能力。比如我们学会骑自行车后,学骑摩托车就很简单了;在学会打羽毛球之后,再学打网球也就没那么难了。对于计算机而言,所谓迁移学习,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术。

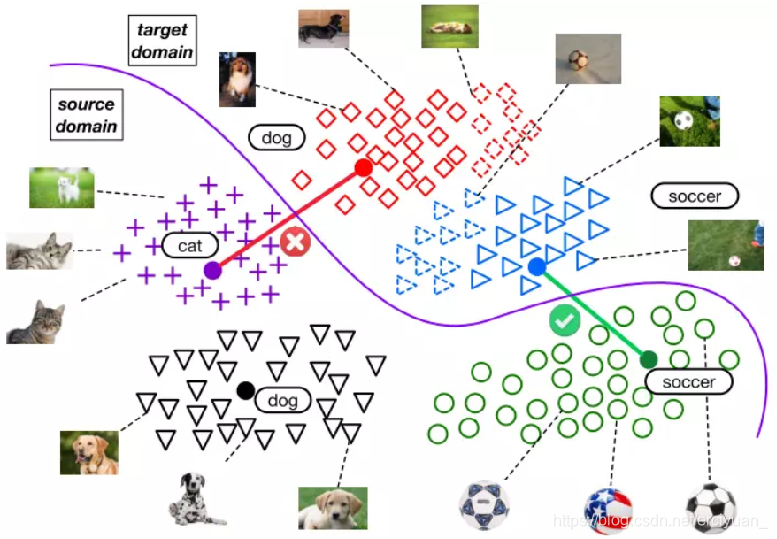
上面这个图片就是迁移学习一个简单的例子,迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可以顺利地实现知识的迁移。迁移学习:是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
简单了解了迁移学习的概念之后,那我们为什么需要迁移学习呢?
1、我们正处在一个大数据时代,每天每时,社交网络、智能交通、视频监控、行业物流等,都产生着海量的图像、文本、语音等各类数据。这些数据往往是很初级的原始形态。
做法:我们可以寻找一些与目标数据相近的有标注的数据,从而利用这些数据来构建模型,增加我们目标数据的标注。

2、公司有着雄厚的计算能力去利用这些数据训练模型。例如, ResNet 需要很长的时间进行训练。Google TPU 也都是有钱人的才可以用得起的。绝大多数普通用户是不可能具有这些强计算能力的。这就引发了大数据和弱计算之间的矛盾。
做法:将那些大公司在大数据上训练好的模型,迁移到我们的任务中。针对于我们的任务进
行微调,从而我们也可以拥有在大数据上训练好的模型。
3、人们的个性化需求五花八门,短期内根本无法用一个通用的模型去满足。
做法:进行自适应的学习。考虑到不同用户之间的相似性和差异性,我们对普适化模型进行灵活的调整,以便完成我们的任务。
4、一些特定的应用,它们面临着一些现实存在的问题。
做法:为了满足特定领域应用的需求,我们可以利用上述介绍过的手段,从数据和模型方法上进行迁移学习。
迁移学习的问题形式化,是进行一切研究的前提。在迁移学习中,有两个基本的概念:
领域 (Domain) 和任务 (Task)。它们是最基础的概念。定义如下:
领域 (Domain): 是进行学习的主体。领域主要由两部分构成: 数据和生成这些数据的概率分布。通常我们用花体 D 来表示一个 domain,用大写斜体 P 来表示一个概率分布。
特别地,因为涉及到迁移,所以对应于两个基本的领域: 源领域 (Source Domain) 和目标领域 (Target Domain)。这两个概念很好理解。源领域就是有知识、有大量数据标注的领域,是我们要迁移的对象;目标领域就是我们最终要赋予知识、赋予标注的对象。知识从源领域传递到目标领域,就完成了迁移。
领域上的数据,我们通常用小写粗体 x 来表示,它也是向量的表示形式。例如, xi 就表示第 i 个样本或特征。用大写的黑体 X 表示一个领域的数据,这是一种矩阵形式。我们用大写花体 X 来表示数据的特征空间。
通常我们用小写下标 s 和 t 来分别指代两个领域。结合领域的表示方式,则: Ds 表示源领域, Dt 表示目标领域。值得注意的是,概率分布 P 通常只是一个逻辑上的概念,即我们认为不同领域有不同的概率分布,却一般不给出(也难以给出) P 的具体形式。


我们看一下领域适配的模型图:
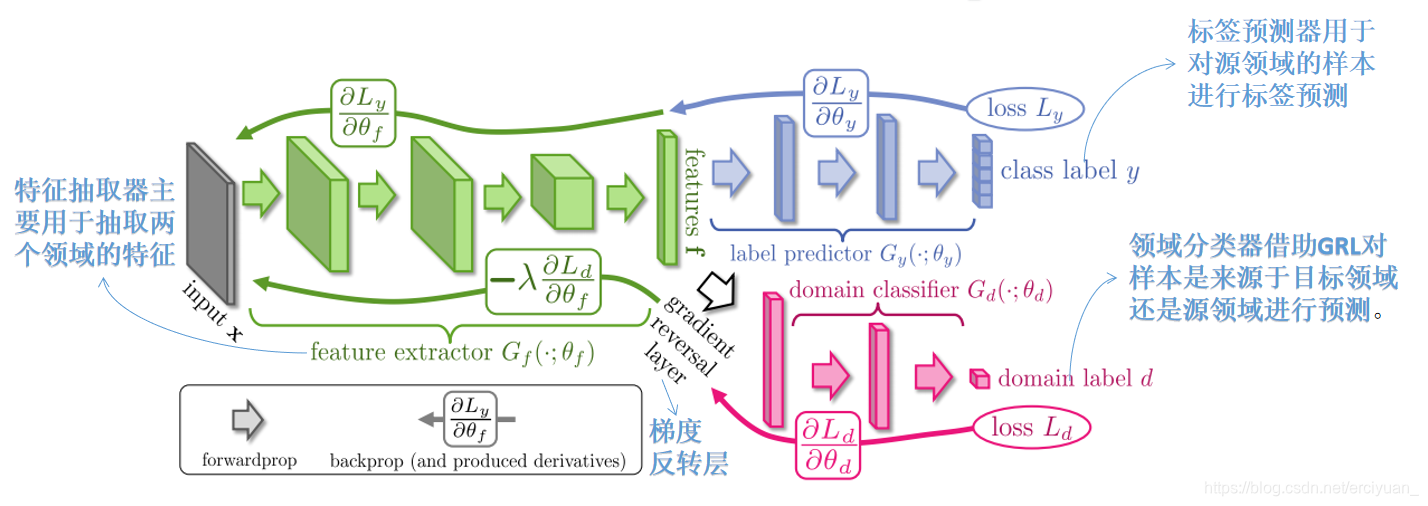
解析:
其中,我们为了实现domain adaptation这个结构总共有三部分构成,绿色的feature extractor(特征提取器),紫色的class label(标签预测器),红色的domain label(域分类器),当我们输入一样样本x的时候,我们把源域和目标域里的数据混合在一起,然后提取这两个域中的共同特征,针对这个共同特征之后,我们对源域里面的样本进行标签预测,然后判断这个样本是来源于源域还是目标域进行预测。
一开始我们源域里面的数据是有标注的,分好类的,我们希望学习到一个分类器,可以对目标域里面的数据也能进行分类,因为目标域里面的数据都是没有标注,未分类的。
梯度反转层:
作者引入了梯度反转层gradient reversal layer (GRL) 来实现上述优化的SGD(因为参数−λ的存在,这个式子不能用SGD直接实现)
在前向传播( forward propagation)的过程中,GRL是个恒等变换
在backpropagation阶段,GRL从后一层获取梯度,乘以−λ后再传给前一层
训练过程:
先训练使得参数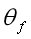 能够最大化Domain classification loss(混淆),以保证提取的特征是 domain-invariant feature。这里同时也拿标签预测器的参数
能够最大化Domain classification loss(混淆),以保证提取的特征是 domain-invariant feature。这里同时也拿标签预测器的参数 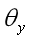 一起训练的.之后训练域分类器的参数
一起训练的.之后训练域分类器的参数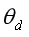 最小化Domain classification loss.
最小化Domain classification loss.
损失函数:
这个模型的损失函数分为两个部分,标签预测的损失和域分类的损失,Ly即为标签预测的损失,针对源域,n为样本数,Ld为域判别器的损失,针对源域和目标域,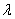 为一个常数,用来衡量两个损失函数之间的权重。
为一个常数,用来衡量两个损失函数之间的权重。
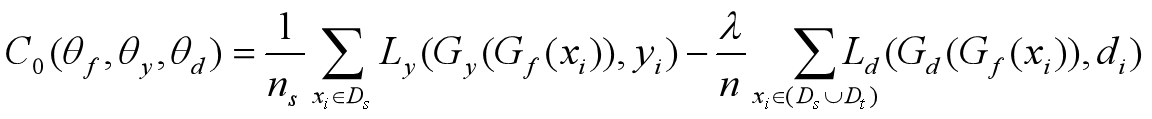


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









