







A novel multi-population evolutionary algorithm based on hybrid collaboration for constrained multi-objective optimization
原文链接: https://doi.org/10.1016/j.swevo.2024.101581
Wang Q, Li Y, Hou Z, et al. A novel multi-population evolutionary algorithm based on hybrid collaboration for constrained multi-objective optimization[J]. Swarm and Evolutionary Computation, 2024, 87: 101581.
只供学习使用,不作商业用途,侵权删除
A novel multi-population evolutionary algorithm based on hybrid
collaboration for constrained multi-objective optimization
摘要: 基于多群体的方法被广泛用于解决约束多目标优化问题(CMOP)。 群体协作策略是多群体算法的关键部分,不同的协作策略在不同的复杂 CMOP 上表现良好。 然而,这些单群体协作策略仍然难以适应具有不同特征的各种 CMOP。 为了解决这个问题,我们提出了一种名为 TPHCEA 的新型三种群混合协作进化算法,其中包括一个约束松弛种群(表示为 𝑚𝑎𝑖𝑛𝑝𝑜𝑝)、一个忽略约束的辅助种群(表示为 𝑎𝑢𝑥𝑝𝑜𝑝1)和一个辅助种群(表示为 𝑎𝑢𝑥𝑝𝑜𝑝1)。 如𝑎𝑢𝑥𝑝𝑜𝑝2)对于原始CMOP,在可行区域中搜索最优解。 具体来说,由于两个辅助群体的互补性不同,𝑚𝑎𝑖𝑛𝑝𝑜𝑝与𝑎𝑢𝑥𝑝𝑜𝑝1和𝑎𝑢𝑥𝑝𝑜𝑝2在强合作和弱合作之间进行动态选择。 TP-HCEA 的有效性通过与四个 CMOP 基准套件中的七种最先进算法和九个实际问题的比较分析得到验证。
一、介绍
实际应用中的各种挑战通常需要同时优化多个目标,并且这些目标有时可能会出现相互冲突的优先级。 此类场景的示例包括汽车设计的优化 [1] 和电网效率的提高 [2]。 约束多目标优化问题 (CMOP) 是指必须在遵守一个或多个约束的同时实现多个目标的同时优化的问题 [3]。 常见的 CMOP 可以表述为 [4]:
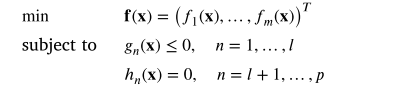 其中 𝐱 = (𝑥1, 𝑥2,…, 𝑥𝐷) 是 D 维决策向量; 𝑓 代表 𝑚 目标函数; 𝑔𝑛(𝐱) 对应于不等式约束,ℎ𝑛(𝐱) 表示等式约束。 计算约束违规值 (𝐶𝑉𝑠) 以比较解决方案的可行性:
其中 𝐱 = (𝑥1, 𝑥2,…, 𝑥𝐷) 是 D 维决策向量; 𝑓 代表 𝑚 目标函数; 𝑔𝑛(𝐱) 对应于不等式约束,ℎ𝑛(𝐱) 表示等式约束。 计算约束违规值 (𝐶𝑉𝑠) 以比较解决方案的可行性:
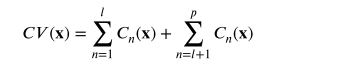
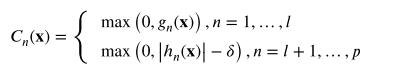
其中 𝛿 是用于处理方程约束的最小正数。
当 𝐶𝑉(𝐱) = 0 时,𝐱 是可行解。 否则,称为不可行解。 𝐶𝑉(𝐱) 值越大,解 𝐱 越违反总体约束。 满足所有约束的解空间称为可行区域,而不满足这些约束的空间称为不可行区域。
对于两个可行解𝐱1和𝐱2,𝐱2被𝐱1支配意味着在m个目标函数中,𝐱1的目标函数值没有一个比𝐱2差。 至少有一个目标函数值优于 𝐱2。 如果任何其他解决方案不占支配地位,则该解决方案是帕累托最优解决方案。 所有帕累托最优解的集合称为帕累托最优集(PS)。 同时,帕累托最优前沿(PF)代表PS在目标空间中的映射。
由于与约束相关的困难,CMOP 通常比无约束多目标优化问题更复杂。 人们已经开发了各种约束多目标进化算法(CMOEA)来解决 CMOP。 一种流行的方法是将 CMOP 转化为其他问题 [6]。 这种方法通常表现为两种类型的 CMOEA:基于多群体和基于多阶段。 在基于多群体的 CMOEA 中,普遍的策略使用分而治之的方法 [7]。 这种方法采用辅助种群,通常是忽略约束或放松约束的辅助种群,以在进化过程中协助主要种群。 值得注意的是,现有算法通常在群体协作方法上表现出一致性。 他们倾向于要么专门采用强合作,要么选择弱合作。 协作方法的选择与种群间策略的相似性以及最终的优化目标有关。 具有不同最终目标的人群之间的密切合作可能会导致不利影响。 具有相似策略的群体之间的合作薄弱,对于使用实用信息来说是低效的。 因此,忽视辅助群体之间的差异,一味地使用单一的协作策略,不仅无法解决复杂的CMOP并增强算法的效果,反而可能使算法的性能变得更差。 其次,由于约束条件导致的可行域复杂多变,大大增加了求解CMOP的难度。 使用单一辅助群体很难适应具有不同特征的 CMOP,并且不同的辅助群体可以在 CMOEA 内的 CMOP 求解过程中扮演不同的角色。 仅使用忽略约束的辅助种群可以加速跨不可行区域的收敛,但帮助主要种群在可行域内收敛并不容易。 仅使用强调约束的辅助群体增强了在可行区域中搜索的能力,但往往会陷入局部最优。 另一方面,不同的辅助群体可以在 CMOEA 内的 CMOP 求解过程中扮演不同的角色。 因此,多个群体之间的混合协作方法也可能有助于处理 CMOP。
基于此分析,本文提出了一种使用具有不同约束处理技术(CHT)的多个群体的协同进化策略。这项工作的主要贡献可概括如下:
- 分析了现有使用强合作和弱合作的多群体算法的优缺点,并讨论了群体之间不同类型协作的适应场景。 提出了一种基于三子种群框架的混合协作多种群进化算法(TP-HCEA)。 所选择的辅助种群和协作方法将随着进化代数的增加而逐渐变化,使得算法能够适应各种具有不同特征的CMOP。
- 我们提出了一个基于不同 CHT 的三个种群的进化框架,包括约束松弛的主要种群、基于帕累托优势的忽略约束的辅助种群 (𝑃𝐷) 和约束主导原则 (𝐶𝐷𝑃) 的辅助种群 。 这三个群体中的每一个都适应具有不同特征的 CMOP。 复杂多样的 CMOP 可以通过三个群体的共同进化来解决。
二、背景
2.1 现存的约束多目标进化算法
不同CMOEA的本质区别在于对目标函数和约束条件的处理。 应用不同约束处理技术的 CMOEA 旨在找到 CMOP 的真实 PF。
通常,约束处理技术可分为五类:
(1) 𝐶𝐷𝑃(约束主导原则);
(2) 处罚方法;
(3)随机排序;
(4) 𝜀约束方法;
(5) 多目标方法。
- 𝐶𝐷𝑃 方法总是倾向于选择可行的解决方案; 可行性优先。 对于不可行解,可行解始终是非支配解。 非支配排序决定了两个可行解之间的支配关系。 对于两个不可行解,支配关系由𝐶𝑉值决定。 该方法可以提高可行性并易于与其他 CMOEA 结合。 然而,适应具有复杂可行区域的 CMOP 是很困难的,最终使算法陷入局部最优区域。
- 惩罚方法主要基于CV构建惩罚项。 向目标函数添加惩罚项将受约束问题转化为无约束问题。 虽然该方法简单,并且在一些约束简单的 CMOP 上有较好的结果,但很难确定合适的惩罚因子来适应不同的 CMOP。
- 随机排序方法使用概率参数𝑝𝑓引入随机性; 当比较两个解时,𝑝𝑓是仅比较目标值的概率,(1-𝑝𝑓)是比较CV值的概率。 这种方法通过概率保留一些更差的解决方案来保持多样性,从而更好地探索解决方案空间。
- 在 𝜀 约束方法中,小于 𝜀 的 CV 值被认为是可行的解决方案,并且根据 𝜀 的值,改变对约束和目标的重视。
- 最后一种方法是基于多目标优化的方法。 这种方法将约束视为一个或多个附加目标,将 CMOP 转化为无约束问题 [20]。 由于必须优化更多目标,它还可能增加问题的计算复杂性。
2.2 单种群算法
将 约束处理技术 嵌入单个群体中是解决约束多目标优化问题的常见方法。NSGAII-CDP是嵌入𝐶𝐷𝑃的典型算法。 研究人员已经开始利用不可行区域的信息来解决𝐶𝐷𝑃方法太容易陷入局部最优的问题。 一些算法将进化过程分为两个阶段。 在两阶段框架(ToP)中,CMOP 被转换为单目标优化问题,以在阶段 1 中找到可行且有前景的区域。然后在阶段 2 中获得最终解决方案。然而,在探索 第 1 阶段,参考向量导致解的聚合,导致第 2 阶段探索可行区域变得困难。 Fan 等人 提出了推拉搜索算法(PPS),其中在第一阶段忽略进化约束,并在第二阶段使用改进的𝜀方法进行搜索。该方法本质上是利用不可行解的信息来提高最终解的质量。 田等人提出了多阶段约束多目标进化算法(CMOEAMS)[24],将进化过程分为两个阶段。 第一阶段优先考虑约束条件,当种群中可行解的比例小于𝜆时,进入第二阶段,同等考虑约束条件和目标。 𝜆 是一个预设参数,用作比较阈值。
2.3 多种群算法
Potter 和 De Jong 提出了协同进化遗传算法(CCGA),明确地模拟了合作物种的协同进化,开创了进化计算中的协同进化方法。 随后,一些研究人员尝试将协同进化的思想引入CMOEA。 不同的CHT在多个群体中被采用,并在进化过程中相互协助。 彭等人提出了一种协作框架,利用子群体来探索信息并根据获得的信息切换搜索阶段。 明等人使用两个互补群体共同进化和自适应适应度函数尝试在收敛性、多样性和可行性之间找到平衡。 刘等人将三种不同的排序方法(非支配排序、反向非支配排序和约束拥挤距离排序)纳入双归档机制中,以解决目标函数过多的情况。 杨等人将CMOP按空间划分为多个子问题,并在子空间中使用多个CHT进行约束处理。 王等人提出了一个框架,该框架在 m 个群体中使用单目标算法,并使用特殊的 CHT 来处理优化,将可行解归档到第 (m+1) 个群体。 李等人。 提出了一种二档案进化算法(C-TAEA)。 C-TAEA分为两个群体:原始CMOP的群体(表示为CA)和忽略约束的群体(表示为DA)。田等人。 提出了一种协同进化约束多目标优化框架(CCMO)[27],其中𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛1采用基于可行性的策略,𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛2是一个约束-ign群体,并且两个群体相互作用较弱。Liu等人提出的CCMOTA。 是基于 CCMO 的改进,用于解决具有更复杂的可行区域的 CMOP [36]。 然而,当无约束 PF (UPF) 和真实 PF 之间的距离太大时,这种合作的价值就不那么高了。 邹等人。 提出了一种基于替代进化和退化(CAEAD)的双种群进化算法[29],二次种群到达PF后会逐渐退化到可行区域,然后再次返回PF。 这个过程可以为主要种群提供优秀不可行解的信息,再次提高主要种群在目标空间的可搜索性。
参考文献看原文
讨论:群体之间交换信息的方法对于多群体算法至关重要。 研究人员将这种信息交换称为协作。 合作有两种选择:强合作和弱合作。 如图1所示,强合作表明两个种群之间存在深度合作,它们在种群进化的两个或多个方面相互作用。 例如典型的强合作,从两个种群中选择父代,两个种群共享由此产生的后代。 合作弱意味着两个群体仅共享少量信息; 在进化过程中,两个种群只共享各自的后代,其他环节并不干涉。 C-TAEA和CCMO是两种典型的仅使用一种协作方法的多群体算法。 在 C-TAEA 中,两个群体采取了强有力的合作策略。 跨越大的不可行区域具有挑战性,因为 DA 更倾向于更好的分布而不是更好的目标值。 在这种情况下,两个种群共享太多信息,从而损害了各自的进化。 对于CCMO来说,两个种群总是只共享后代,这提高了CCMO的搜索能力,避免了种群之间的负面影响。 然而,与单个辅助群体的弱合作影响了算法的收敛性。
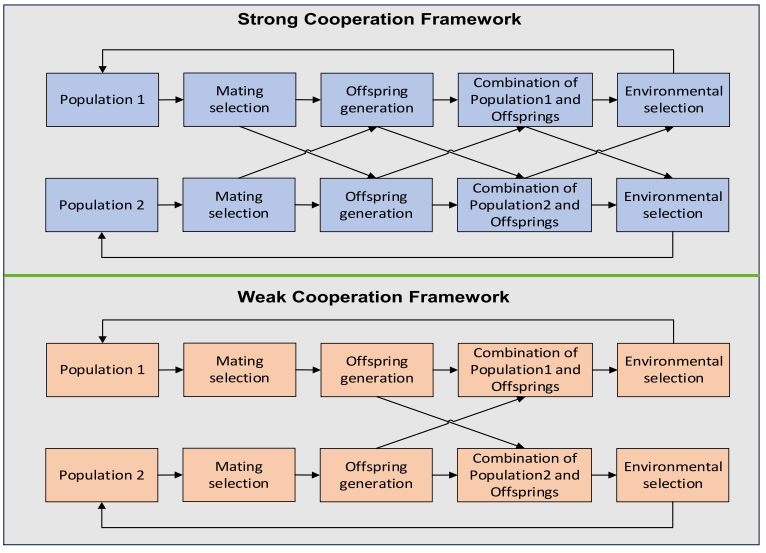
2.4 动机
CMOP 的主要困难是在由于约束而具有不同形态的不可行域中找到真实的 PF。 采用多重种群方法来提高CMOEA对不同情况的适应性。 两个种群之间的合作模式与种群的相关性有关。 单一辅助群体和协作方法不能很好地解决这些挑战,如图2所示。图2(a)说明了C-TAEA的进化结果,该C-TAEA在被几个大的不可行区域划分的CMOP中使用强合作。 在C-TAEA中,CA考虑收敛,DA考虑分布。 由于两个群体的目标相似度较低,强合作可能会产生负面影响,导致两个群体都无法实现目标,CA陷入局部可行区域,DA的分配得不到保证。 图2(b)说明了在可行区域被断开的CMOP中使用弱合作的CCMO的进化结果。 在 CCMO 中,𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛1 解决原始 CMOP,𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛2 解决忽略约束的辅助问题。 由于群体之间的合作较弱,即使该 CMOP 的真实 PF 与 UPF 部分重叠,𝑝𝑜𝑝𝑢𝑙𝑎𝑡𝑖𝑜𝑛1 也无法找到所有真实的 PF。 弱合作避免了人群之间的不利影响。 然而,当利用辅助种群来强化主要种群的某个特征时,弱合作会导致效果不佳。 通过讨论,我们可以看到不同人群之间必须使用不同的协作策略。 由于必须根据群体之间的相似性来选择协作方法,因此需要确定选择的群体来解决 CMOP。
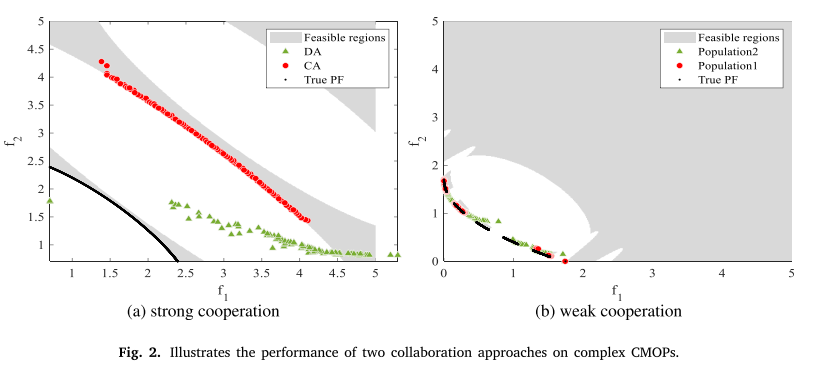
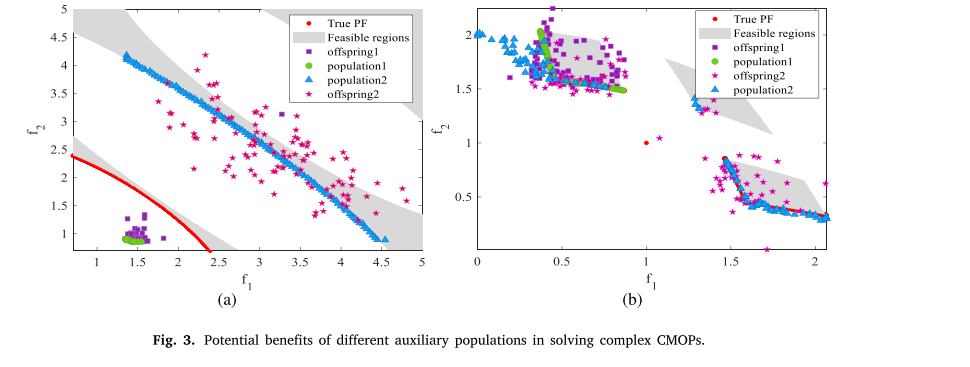
图3给出了不同辅助种群在原始CMOP中的作用。如图3(a)所示,UPF在真PF前面;population2以原始CMOP为目标进化,而population1忽略约束,到达UPF附近。由于图3(a)中两个可行区域之间存在较大的不可行的区域,使得population2容易被困在外可行区域。通过各自种群产生的协作(例如,共享后代),忽略约束的CMOP解决方案将帮助它们跳出并跨越不可行区域。其次,如图3(b)所示,原始CMOP的可行区域远离UPF,是以原始CMOP为目标的离散人口1,人口2是约束松弛的辅助人口。在这种情况下,population1很容易被困在一个可行域中,很难找到所有可行区域。同时,放宽约束的种群有更好的机会找到所有可行域,通过信息交换,可以找到所有可行域。
提出了三个种群的混合协同进化策略,以结合三个种群的优势并解决不同的 CMOP。 在演化过程中,𝑚𝑎𝑖𝑛𝑝𝑜𝑝的约束强度是动态调整的。 早期,首选辅助种群是𝑎𝑢𝑥𝑝𝑜𝑝1,一个忽略约束的种群。 由于两个群体的最终目标不同,因此选择弱合作作为协作方式,以避免相互拉扯。 在进化后期,𝑚𝑎𝑖𝑛𝑝𝑜𝑝达到真实PF附近,需要增强可行区域的搜索能力。 由此可见,后期选择的主要辅助群体为𝑎𝑢𝑥𝑝𝑜𝑝2,合作方式为强合作。 𝑎𝑢𝑥𝑝𝑜𝑝2 使用与𝑚𝑎𝑖𝑛𝑝𝑜𝑝 的最终目标一致的完整的基于可行性的策略。 强有力的合作使得𝑚𝑎𝑖𝑛𝑝𝑜𝑝能够在可行区域内充分扩展。
三、算法
3.1 框架
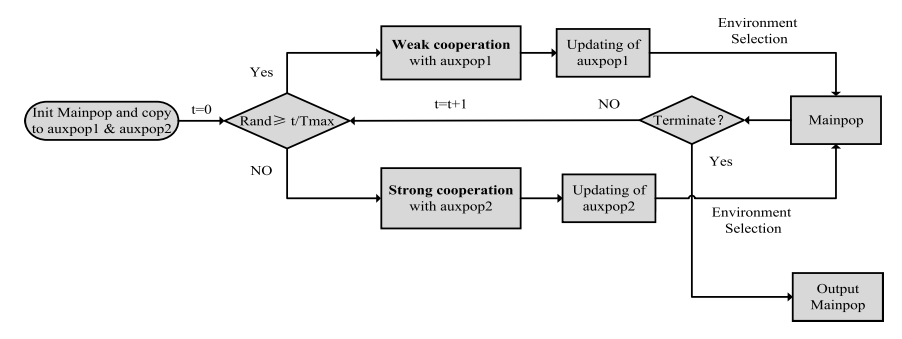
在图4中,所提出的TP-HCEA框架中的进化过程包含两种不同的协作方法和两个辅助群体。 初始化mainpop并将其复制到辅助种群后,获得三个初始种群后,算法开始运行。 𝑡是进化代数,初始值为0,𝑇𝑚𝑎𝑥是最大进化代数,rand是0到1之间的随机数。随着𝑡越来越接近𝑇𝑚𝑎𝑥,rand大于的概率 𝑡/𝑇𝑚𝑎𝑥 减少。 选择辅助种群的概率随进化代数的不同而变化。 选择辅助种群的概率随进化代数的不同而变化。 早期选择𝑎𝑢𝑥𝑝𝑜𝑝1 的概率较高,因为早期需要忽略约束𝑎𝑢𝑥𝑝𝑜𝑝1 中不可行解所携带的信息。 与𝑎𝑢𝑥𝑝𝑜𝑝1协作时,采用弱合作进行协作。 随着进化代数𝑡的增加,选择𝑎𝑢𝑥𝑝𝑜𝑝2的概率增加。 𝑎𝑢𝑥𝑝𝑜𝑝2 和𝑚𝑎𝑖𝑛𝑝𝑜𝑝之间进行了强有力的合作。 每次选择辅助群体后,辅助群体和𝑚𝑎𝑖𝑛𝑝𝑜𝑝都会更新。 更新完成后,判断是否满足终止条件。 如果有,则输出main pop; 否则,使t+1并继续循环。
提议的 TP-HCEA 由算法 1 提出。首先,𝑚𝑎𝑖𝑛𝑝𝑜𝑝 被初始化并复制到𝑎𝑢𝑥𝑝𝑜𝑝1 和𝑎𝑢𝑥𝑝𝑜𝑝2 中。 初始化完成后,开始辅助种群的选择,选择的随机性有利于跳出局部最优。 𝑀𝑎𝑖𝑛𝑝𝑜𝑝以目标函数作为附加目标来优化CV,放松约束逐渐变少,最终变为0。当随机生成的值小于当前代与最大代的比例时(𝑟𝑎𝑛𝑑 < 𝑡 ∕𝑇𝑚𝑎𝑥)、𝑚𝑎𝑖𝑛𝑝𝑜𝑝和𝑎𝑢𝑥𝑝𝑜𝑝1共同进化,通过算法2利用弱合作产生后代,这些后代与原始种群融合,共同参与环境选择。 如果𝑟𝑎𝑛𝑑≥𝑡∕𝑇𝑚𝑎𝑥,𝑚𝑎𝑖𝑛𝑝𝑜𝑝与𝑎𝑢𝑥𝑝𝑜𝑝2使用强合作算法生成后代3.后代产生后,所选择的辅助种群将通过环境选择进行更新。 具体来说,𝑎𝑢𝑥𝑝𝑜𝑝1基于𝑃𝐷进行环境选择; 𝑎𝑢𝑥𝑝𝑜𝑝2基于𝐶𝐷𝑃进行环境选择。 对于𝑚𝑎𝑖𝑛𝑝𝑜𝑝,需要先更新约束松弛度𝜀,然后用新的𝜀进行环境选择。
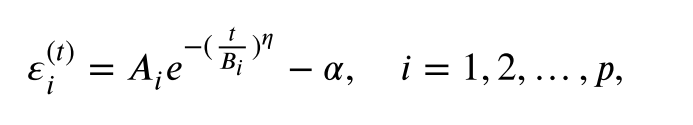
其中𝛼是几乎等于零的常数,𝜂用于控制𝜀减小的速率。 𝜂的值越大,约束强度增加得越快。 𝑇𝑚𝑎𝑥代表最大进化世代。 为了使 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 中的所有解都可行,𝜀 的初始值设置为 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 中解的约束之一的最大违反值。 约束边界调整结束时𝜀的值为0。我们可以从初始状态和最终状态得到常数𝐴𝑖和𝐵𝑖。
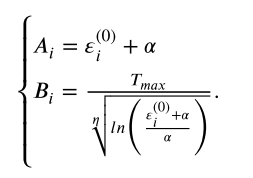

3.2 子种群
由于 𝑎𝑢𝑥𝑝𝑜𝑝1 忽略约束演化以获得更好的分布式解决方案,因此与 𝑎𝑢𝑥𝑝𝑜𝑝1 交互可以帮助𝑚𝑎𝑖𝑛𝑝𝑜𝑝 脱离此局部最优。 当脸被相当大的可行区域阻挡时,𝑎𝑢𝑥𝑝𝑜𝑝1(向UPF进化)也可以拉动𝑚𝑎𝑖𝑛𝑝𝑜𝑝穿过不可行区域。 两个群体的协作之所以选择弱合作,是因为两个群体𝑎𝑢𝑥𝑝𝑜𝑝1和𝑚𝑎𝑖𝑛𝑝𝑜𝑝用来解决不同的问题; 如果采取强有力的合作,后代将在两个亲代群体的中间产生,并且由于𝑎𝑢𝑥𝑝𝑜𝑝1和𝑚𝑎𝑖𝑛𝑝𝑜𝑝是两种彼此不同的策略,当真正的PF与UPF完全分离时。 距离远了,这样产生的后代反而会让最终的结果变得更差,所以这里选择弱合作。

当𝑎𝑢𝑥𝑝𝑜𝑝2 与𝑚𝑎𝑖𝑛𝑝𝑜𝑝 合作时,两个种群在亲本选择和后代生成方面紧密合作。 在算法 3 中,强合作产生后代和 𝑎𝑢𝑥𝑝𝑜𝑝2 更新。 具体来说,首先将𝑚𝑎𝑖𝑛𝑝𝑜𝑝和𝑎𝑢𝑥𝑝𝑜𝑝2合并为种群𝐻𝑚。 𝑃𝑎 表示合并群体 𝐻𝑚 中 𝑎𝑢𝑥𝑝𝑜𝑝2 中非支配解的比例。 𝑃𝑚表示𝑚𝑎𝑖𝑛𝑝𝑜𝑝中非支配解在𝐻𝑚中的比例。 如果 𝑃𝑎 大于 𝑃𝑚,则 𝑎𝑢𝑥𝑝𝑜𝑝2 比 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 收敛得更好。 因此,我们将从 𝑎𝑢𝑥𝑝𝑜𝑝2 中选择第一个父解决方案。 否则,将在 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 中选择第一个父解决方案。 至于另一个父解,从𝑎𝑢𝑥𝑝𝑜𝑝2或𝑚𝑎𝑖𝑛𝑝𝑜𝑝生成它是由𝑎𝑢𝑥𝑝𝑜𝑝2中非支配解的比例决定的。 比例越大,被用作交配池的机会就越大。 一次生成一个后代,每个获得的后代都合并到集合𝑄中,直到循环结束,将𝑎𝑢𝑥𝑝𝑜𝑝2与𝑄组合起来。 𝐴𝑢𝑥𝑝𝑜𝑝2 由𝐶𝐷𝑃 策略更新。 需要说明的是,因为锦标赛选择计算效率高、鲁棒性强,并且已被广泛引用和研究。 在选择父母时,我们在所有三个群体中都使用了锦标赛选择。
与𝑚𝑎𝑖𝑛𝑝𝑜𝑝使用的约束松弛约束不同,𝐶𝐷𝑃用于𝑎𝑢𝑥𝑝𝑜𝑝2,它对解决方案的可行性有更重要的要求。 尽管如此,这两个种群最终都会进化为真正的 PF。 两个群体试图用不同的策略解决同样的问题。 因此,这两个群体之间采取了强有力的合作。 当面对连续的可行区域时,重视可行解的𝑎𝑢𝑥𝑝𝑜𝑝2 收敛得很好。 强有力的合作使得两个种群之间能够产生大多数后代。 通过强合作产生的后代一方面可以具有𝑎𝑢𝑥𝑝𝑜𝑝2的良好收敛性,另一方面可以具有𝑚𝑎𝑖𝑛𝑝𝑜𝑝的解的合理分布的属性。
3.3 环境选择
与辅助种群合作产生后代后,我们分别对两个辅助种群和𝑚𝑎𝑖𝑛𝑝𝑜𝑝进行环境选择以更新种群解。 将后代与原始种群合并后,根据不同的支配关系(𝑎𝑢𝑥𝑝𝑜𝑝1基于PD,𝑎𝑢𝑥𝑝𝑜𝑝2基于CDP)进行非支配排序,如果得到的非支配解的数量大于原始种群的数量 ,使用截断方法删除一些解。 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 的环境选择过程大致相同。 将 𝑚𝑎𝑖𝑛𝑝𝑜𝑝 中的𝜀−可行解和𝜀−不可行解分为两组后,对 epsilon 可行解集进行非支配排序。 如果存在太多非支配可行解,则根据参考点截断该集合。 算法4详细解释了𝑚𝑎𝑖𝑛𝑝𝑜𝑝的环境选择。

当|𝑆1| >N时,执行非支配排序和基于参考点的精英选择。首先将求解的总CV值作为第m+1个目标。然后,使用基于第m+1个目标的非支配排序将𝑆1分类为不同的非支配类(𝐹1,𝐹2,…)。将CV值作为目标的意义在于,在使用一些不可行的解决方案信息的同时优化目标。这允许优化目标并同时处理约束。然后,选取前g个层次的解,g为满足|𝐹1∪𝐹2∪⋯∪𝑔| <N。然后根据解决方案与预定义参考点之间的关联,在级别g+1上选择|𝐹1∪𝐹2∪⋯∩∩𝑔∩𝑔+1|。这个过程和Deb做的一样。
K. Deb, H. Jain, An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints, IEEE Trans. Evol. Comput. 18 (4) (2013) 577–601.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









