







 本文介绍了CRIS模型,一种利用CLIP模型知识的Referring Image Segmentation方法。通过ResNet和Transformer提取图像与文本特征,结合视觉语言解码器与文本到像素对比学习,实现文本到像素的对齐。在RefCOCO等数据集上,CRIS表现出优越性能。
本文介绍了CRIS模型,一种利用CLIP模型知识的Referring Image Segmentation方法。通过ResNet和Transformer提取图像与文本特征,结合视觉语言解码器与文本到像素对比学习,实现文本到像素的对齐。在RefCOCO等数据集上,CRIS表现出优越性能。
此论文的贡献
1.作者提出了一个CLIP驱动的Referrring Image Segmentation(CRIS)来传递CLIP模型的知识,以实现文本到像素的对齐。
2.充分利用了多模态知识,设计了视觉语言解码器和文本到像素对比学习两种创新设计。
3.在三个具有挑战性的基准数据集(RefCOCO、RefCOCO+、GRef)上的实验结果明显优于以前的最先进的方法。
CRIS模型
模型整体框架
首先,我们使用ResNet和Transformer分别提取图像和文本特征,并进一步融合得到简单的多模态特征。其次,将这些特征和文本特征输入到视觉语言解码器中,将细粒度的语义信息从文本表示传播到像素级的视觉激活。最后,使用两个Projector生成最终的预测掩码,并采用文本-像素对比损失将文本特征与相关像素级视觉特征显式对齐。
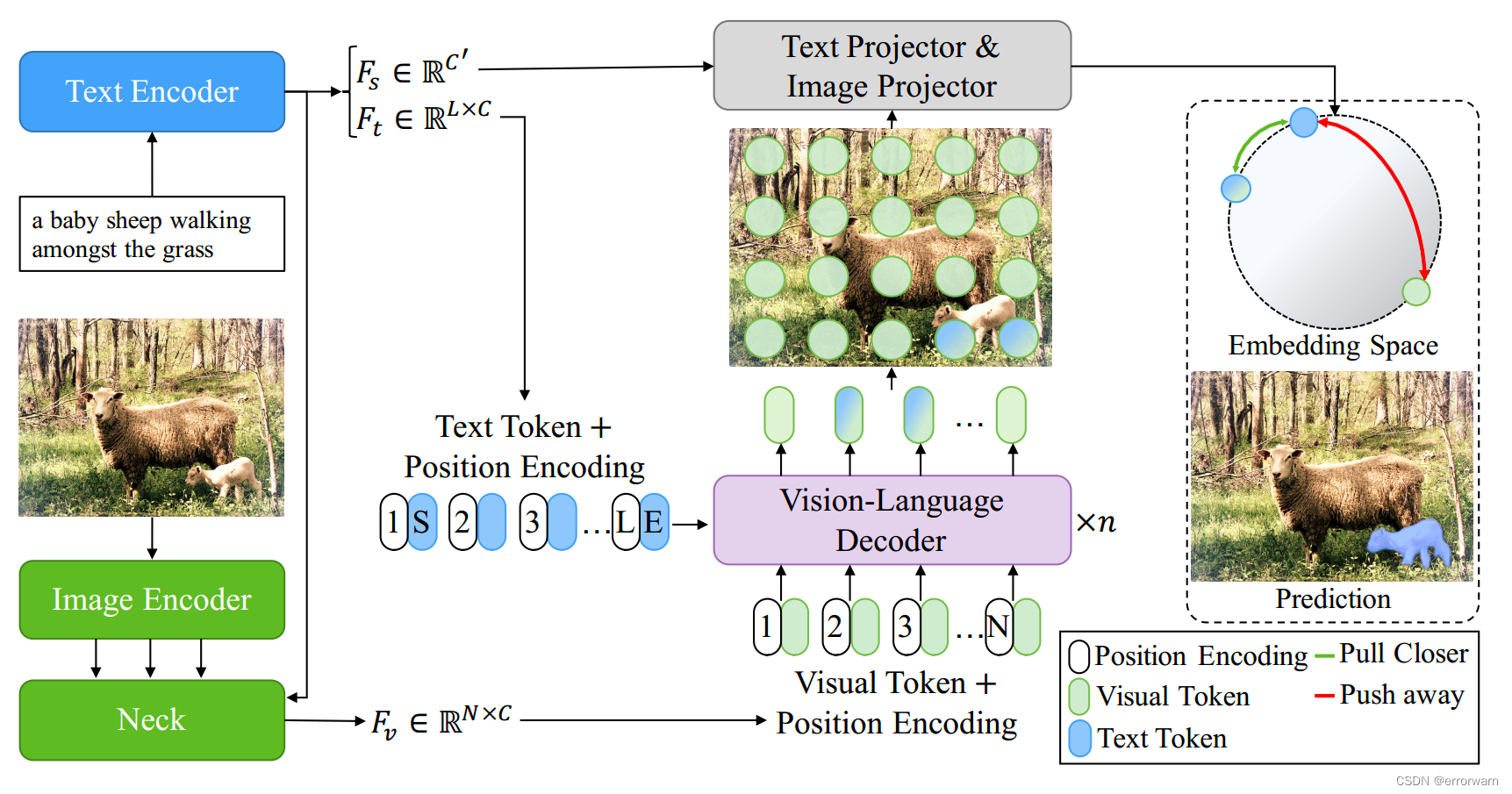
图像和文本特征提取
图像编码器
对于输入图像,输入ResNet得到其2-4阶段的多个视觉特征,分别定义为
,
和
。
文本编码器
对于输入表达式,作者采用经过修改的Transformer来提取文本特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









