







 论文作者为RIS(Referring Image Segmentation)和REC(Referring Image Segmentation)引入了一个新的架构,称为PolyFormer。此模型不是直接预测分割掩码,而是一次产生边界框的角点和所预测实列的多边形顶点。是一种seq2seq的模型。
论文作者为RIS(Referring Image Segmentation)和REC(Referring Image Segmentation)引入了一个新的架构,称为PolyFormer。此模型不是直接预测分割掩码,而是一次产生边界框的角点和所预测实列的多边形顶点。是一种seq2seq的模型。
整体框架
论文作者为RIS(Referring Image Segmentation)和REC(Referring Image Segmentation)引入了一个新的架构,称为PolyFormer。此模型不是直接预测分割掩码,而是一次产生边界框的角点和所预测实列的多边形顶点。是一种seq2seq的模型。
下图为PloyFormer的整体框架: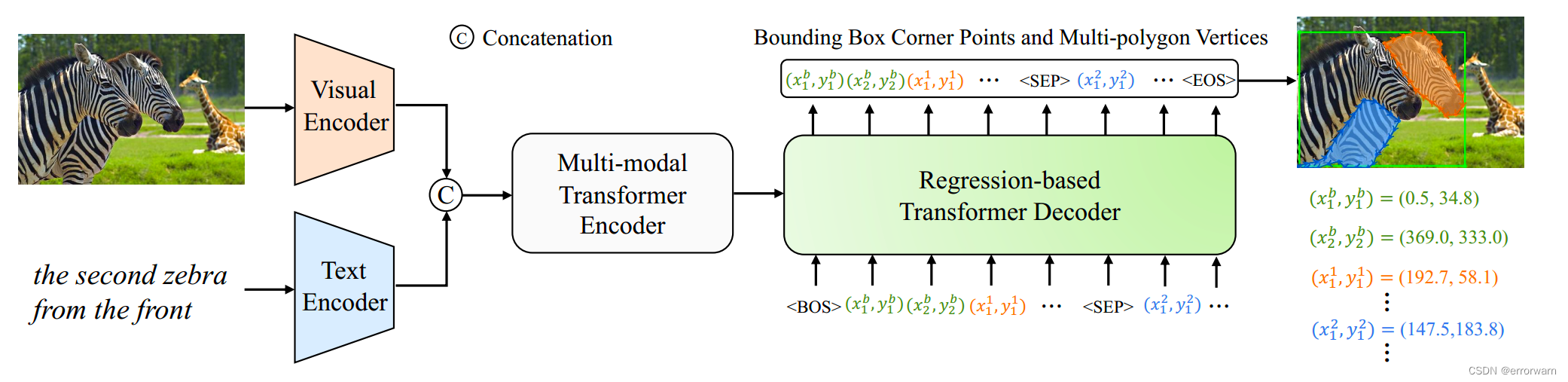
首先使用视觉编码器和文本编码器分别提取图像和文本特征,然后将其投影到共享嵌入空间中。接下来,将图像和文本特征连接起来,并将它们输入多模态transformer编码器。最后,基于回归的transformer解码器利用编码特征,以自回归的方式输出连续浮点边界框角点和多边形顶点。对应的分割掩码即是多边形所包围的区域。
如何表示多边形序列和边界框角点
首先由一个或多个(可能被遮挡)多边形来描述所引用的对象,将多边形参数化为二维顶点{(xi, yi)}的序列K i=1, (xi, yi)∈r2,按顺时针顺序。选择最接近图像左上角的顶点作为序列的起点,如下图: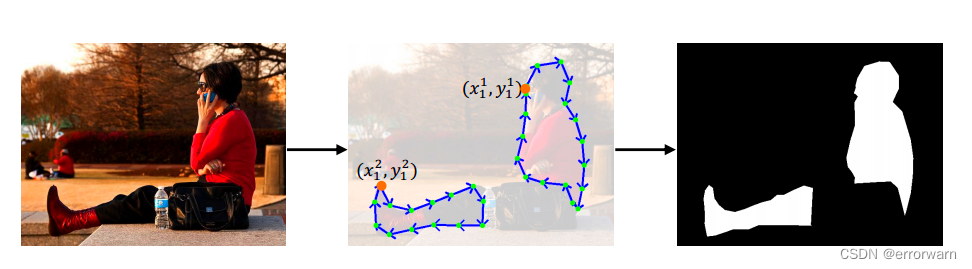
为了表示多个多边形,在两个多边形之间引入分隔符<SEP>。使用<BOS>和<EOS>指示序列的开始和结束。
边界框的坐标表示为左上角坐标和右下角坐标,边界框和多个多边形的坐标的连接方式如下: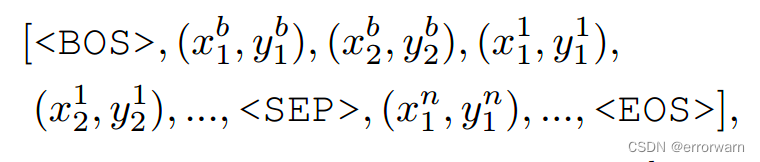
前两个坐标是边界框角点,剩下的是多个多变形顶点序列。
图像和文本特征提取
图像编码器
使用Swin Transformer的第4阶段的编码特征作为视觉表示,输入图片为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









