







一、概述
逻辑回归的应用。
作业分两部分,第一部分就是两参数的线性逻辑回归,第二部分是两参数的非线性逻辑回归,需要正则化。
也是很简单,根本不必知道原理,只知道公式也可以满分,没有检测性,不怎么样,差评。

主要有五个函数要写,第一个plot函数还不算分,Predict函数是白送的分;
是否正则化也没大区别,简而言之没有难点。
二、分析
1、线性逻辑回归
需要写四个函数:plot,sigmoid,Cost Function和Predict。
plot的功能是把对应的点显示出来;
sigmoid函数要实现1/1+e^-z的功能;
Cost Function函数是重点,实现代价函数和梯度下降;
Predict函数用于生成预测矩阵。
首先是plot函数,pdf中有具体简洁的实现,我没看,自己写了一个,十分麻烦。
简而言之就是对于y=0和y=1,使用不同的标志标记并显示,我的代码如下:
ko=zeros(length(y),2);
kp=zeros(length(y),2);
j=1;k=1;
for i=1:length(y)
if y(i)==0
ko(j,1)=X(i,1);
ko(j,2)=X(i,2);
j=j+1;
else
kp(k,1)=X(i,1);
kp(k,2)=X(i,2);
k=k+1;
end
end
plot(ko([1:j-1],1),ko([1:j-1],2),'or');
hold on
plot(kp([1:k-1],1),kp([1:k-1],2),'+b');
hold off输入参数有X,y,X是矩阵,y是向量,根据y的值,用X中对应的当坐标并画出来。
我使用ko和kp分别储存X中y=0和y=1的坐标。然后分别画出来。很麻烦。
给出的推荐代码如下:
% Find Indices of Positive and Negative Examples
pos = find(y==1); neg = find(y == 0);
% Plot Examples
plot(X(pos, 1), X(pos, 2), 'k+','LineWidth', 2, ...
'MarkerSize', 7);
plot(X(neg, 1), X(neg, 2), 'ko', 'MarkerFaceColor', 'y', ...
'MarkerSize', 7);使用了find函数。
find函数功能十分强大,简而言之就是返回所有的值为输入参数的元素的位置,形成一个向量。
这里即返回了y向量中所有1的位置,保存在pos中,而0的位置,保存在neg中。
然后plot画出即可,比我的循环好得多。
然后是sigmoid函数,就是将公式变为代码,一句话:
[x,y]=size(z);
for i=1:x
for j=1:y
g(i,j)=1/(1+exp(-z(i,j)));
end
end注意一点,尽管我们使用时,输入都是向量,但我们必须保证当输入的是矩阵的时候该函数仍然能正常工作,因此要用ij两个下标,而不能只用一个,这一点在pdf中也有说明。另外,e上面的负号不要忘了。
接下来是Cost Function函数。
输入有X,矩阵,y,向量,theta,向量。
输出有J,实数,grad,向量。
明确这些之后,就可以开始写了。
首先计算J,J即代价函数,计算出的是预测值与实际值的误差。我们回忆一下课堂中讲的,这里不能用误差的平方和,因为如果用误差的平方和,那么得到的代价函数J非常复杂,很可能是非凸的,这样,想要求出全局最优解十分困难。而J十分复杂的原因,在于预测函数用了复杂的sigmoid函数,有分数有指数,很麻烦,使用sigmoid函数的目的是它自身性质十分好,可以实现把实数范围内的所有数投影到0~1之间。这样我们就理清了计算J的逻辑链条。
计算J的公式如下:
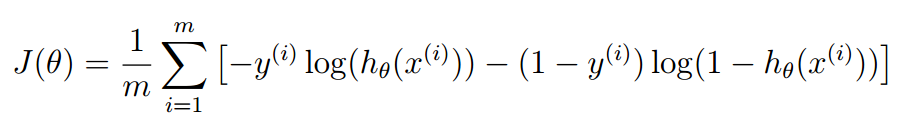
我们必须明确一点,J无论是在线性回归,还是在逻辑回归中,含义只有一个,就是误差和。
只不过在线性回归中,J是误差平方和,而在逻辑回归中,J是误差对数和。
误差即惩罚,预测值与真实值离得越远,惩罚越大,但不要将误差局限于“预测值与真实值之差”,只要符合“离得越远,值越大”,那就可以当做误差。因此这里我们选择取对数,如果真实值是0,那么我们预测值“离0越远”,则“误差越大”,因此“惩罚越大”,使用对数来实现这一点。
这样我们的代价函数就出现了。
代码如下:
J=((-(y')*log(sigmoid(X*theta)))-((1-y)'*log(1-(sigmoid(X*theta)))))/m;只有一行,我们分析公式如下:
yi是第i个例子的实际值,hxi是第i个例子的预测值,hxi是Xi与theta相乘得到的。
那么为了消去累加符号,实际上所有的矩阵化都是为了消去累加符号,也就是消去循环,从而加快计算速度;我们便可以将累加体分成两部分:第一部分计算预测值为1的,也就是前半部分;第二部分计算预测值为0的,也就是后半部分。
第一部分累加的矩阵形式如下:
(-(y')*log(sigmoid(X*theta))同理第二部分如下:
(1-y)'*log(1-(sigmoid(X*theta)))如果对矩阵化有一点晕的话,不妨写出公式,画出矩阵然后手动计算一番,自然理解。
然后计算theta的偏导数。
公式如下:
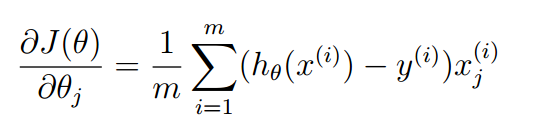
和线性回归的公式一模一样,自己推出来极麻烦,反正我是放弃了,同样矩阵化并循环赋值即可,如下:
for j=1:length(grad)
grad(j)=(((X(:,j))')*(sigmoid(X*theta)-y))/m;
end一个循环即可。
最后是Predict函数,送分题。
简直是小学生的编程题,预测值大于等于0.5,则预测为录取,赋值1,否则拒录,赋值0。生成一个向量并返回即可。
简单得怀疑人生。代码如下:
p_=sigmoid(X*theta);
for i=1:length(p_)
if p_(i)>=0.5
p(i)=1;
else
p(i)=0;
end
end这样大部分分数就拿到了。
注意,我们求出了J和偏导数值,但是并没有利用梯度下降求最后的theta值,这个值是通过调用fminunc函数实现的,这个函数需要我们提供代价函数和偏导数的算法,这也是我们写Cost Function的理由,然后用fminunc就可以求出全局最优解了。
这样,第一部分也就完成了。注意一点,这里的fminunc的预测值可能与题目中的“正确预测值”有一些误差,但并没有什么惊讶的,函数还是对的,如图:

2、非线性逻辑回归与正则化
这一部分我们只需要写一个函数,即Cost Function Reg。
它与上面的Cost Function的区别在于它使用了正则化的方法。
为什么使用正则化呢?因为这里我们的逻辑回归不能用一条直线把两个种类分隔开,而是需要用一条曲线,那么问题来了,曲线需要不止两个参数,也就是theta是不止二维的向量。这里我们使用最高六次的预测函数,也就是最高六次幂。问题就是,这六次幂我们需要哪个,不需要哪个?总不能都需要吧。
正则化的目的就是自动筛选需要的幂次,它们对应的theta值较大,而不需要的幂次,它们对应的theta较小。
要实现这一点,我们要对代价函数进行修改,使得theta的值可以影响代价值,好的theta对应的代价小,不好的theta对应的代价大,公式修改如下:
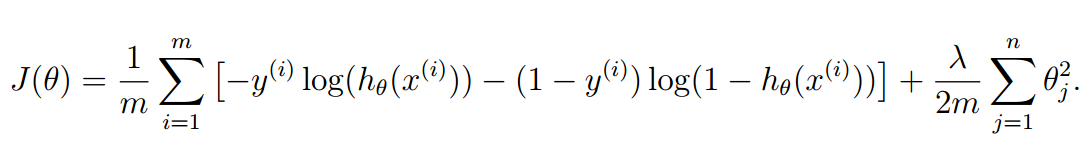
注意一点,theta0是不影响代价函数的。这一点要注意。
代码如下:
J=((-(y')*log(sigmoid(X*theta)))-((1-y)'*log(1-(sigmoid(X*theta)))))/m+((theta((2:length(theta))))'*(theta((2:length(theta)))))*lambda/(2*m);注意theta向量是从第二项开始计算的。
这样就实现了代价函数的正则化。
然后是偏导数。增加的就是后边的那一项求导,这个很容易计算,同样要把theta0排除。
grad(1)=(((X(:,1))')*(sigmoid(X*theta)-y))/m;
for j=2:length(grad)
grad(j)=(((X(:,j))')*(sigmoid(X*theta)-y))/m+theta(j)*lambda/m;
end这样就实现了偏导数的正则化。
最后,同样调用fminunc函数,找到全局最小值即可。
第二部分也完成了。
三、总结
本次作业实现了监督学习中的分类算法,即逻辑回归,分为线性回归与非线性回归。
总体思路都是先确定一个合适的预测函数,一般是多项式,通过theta向量确定,对多项式的输出进行处理,如本例中使用sigmoid函数进行映射;
其次确定代价函数,即一个符合“差的越远值越大”的函数,一般是误差函数的和,本例中的误差函数是对数;
然后找出令代价函数最小的theta值,使用fminunc函数找,而fminunc函数需要的是代价函数和代价函数的偏导数,因此我们给出对应的计算函数;
最后调用fminunc函数即可。
若无法确定多项式的类型,一般使用正则化,来确定较好的多项式。















 1830
1830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









