







0.前言
什么是神经网络?
神经网络是上个世纪出现的产物,其思想就是模拟人体神经网络的方式来实现机器的自主学习。他在许多领域都会有使用,例如:语音识别、图像识别、语言翻译等。
神经网络的思想如下图所示:
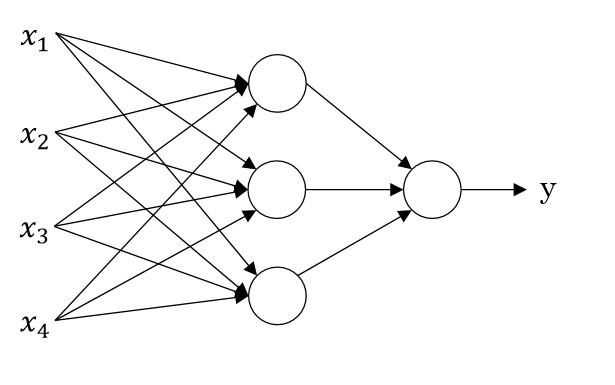
假设 x1 表示房价; x2 表示房子大小; x3 买房者所拥有的资金; x4 表示房子所在地区的空气质量等等,当然实际生活中还可能会考虑许多东西,这里就不举例了。而 y 表示对于房子的是否想买的态度,即想买或不想买。那么神经网络的工作就是将一个房子的上面四个变量放入进去,而神经网络给你预测出你是否想买。
那么他是怎么预测的呢?我们知道房价和房子大小往往是存在正相关性的,即房子越大房价越高,在这里我们将它们统称为“房子的状况”;“买房者所拥有的资金”以及一些其他的买房者的信息统称为“买房者的状况”;“房子周边的空气质量”有决定这“房子周边环境”。因此第二层的三个圆圈,可以看做:“房子的状况”、“买房者的状况”、“房子周边环境”。而第三层的一个圆圈可以看做“对房子的评分”。然后如果评分大于一个值,那么表示买,如果小于表示不买。
神经网络就是做了那么一个事情,我们经过一定的计算可以根据前面的节点,来获取下一个节点表示的特征,来达到预测的目的。那么问题来了,在上面图中第二层的三个圆各代表哪一个情况呢?答案是无法预知,有可能上面三种情况,有可能是上面情况中的两种,有可能是一些其他的有相关性的情况,甚至可能是一些我们经验无法解释的组合。正因为这样,所以神经网络被诟病为“黑盒”,里面的东西往往无法预测也无法解释。
我们先从一个节点来解释,神经网络的工作方式。
附:在本文中,激活函数使用sigmoid函数,数据集使用鸢尾花数据集前100行,可以在R中直接输”iris”出现,在python中
from sklearn import datasets
iris = datasets.load_iris()并将前50行数据的Species设置为0,后50行的设置为1
1. 神经元
神经网络是由一个个神经元构成的,例如在上面的例子中,第一层有三个神经元,第二层有一个神经元。这里我们先讲一讲什么是神经元,神经元如下图所示
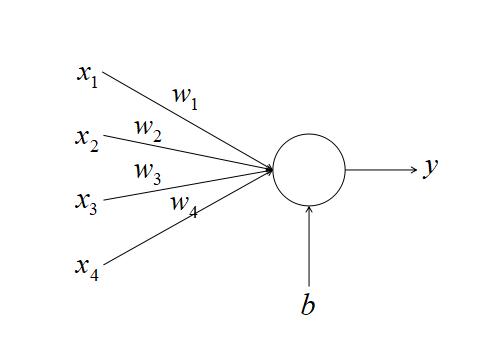
在神经元中,会对
举个例子,假设
- 今天气温为20度,风力2级,湿度15%,空气质量51;
- 明天气温为25度,风力1级,湿度10%,空气质量152;
- 后天气温为22度,风力5级,湿度12%,空气质量51。
对于是否适合运动来说
- 气温的权重为10;
- 风力权重为-50;
- 湿度权重为-5;
- 空气质量权重为-3;
- 截距200。
那么加权求和的结果为:今天指数为72,明天指数为-156,后天指数为-33.我们再使用sigmoid函数
上面的公式为
其中
f
称为激活函数(activation function)。在本例子中采用sigmoid(
上面的式子可能只会出现一次,在后面的使用中我们矩阵来代替多个样本,因此对于存在变量
(x1,x2,x3,...,xn)
,存在样本
(x(1),x(2),x(3),...,x(m))
对应的矩阵为:
现在有两个问题:
1. 激活函数是什么,如何选择?
2.
在下面我们会解决这个问题。
1.1 激活函数(activation function)?
激活函数的作用是什么,可以参考:神经网络激励函数的作用是什么?有没有形象的解释? - lee philip的回答 - 知乎
现常用的激活函数有:
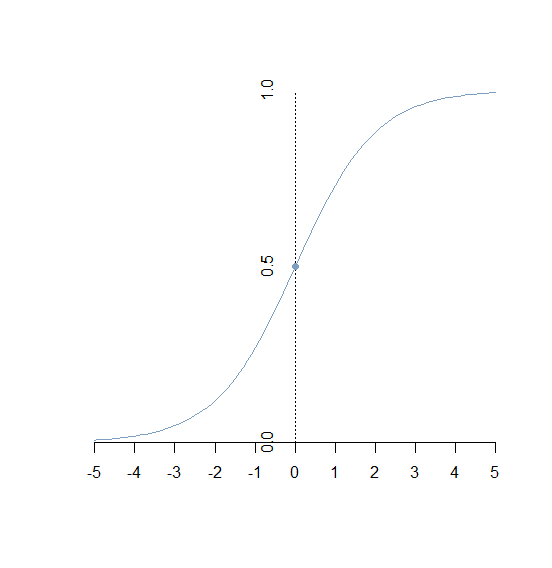
- sigmoid函数:公式为 图像为:
y=11+e−x
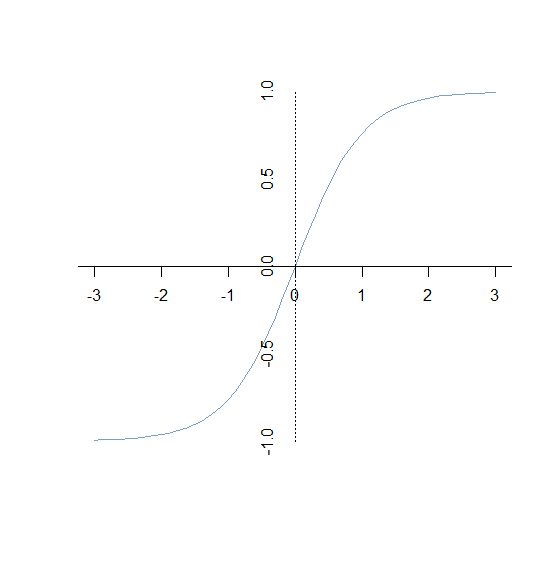
- tanh函数:公式为
y=sinh(x)cosh(x)=ex−e−xex+e−x图像为
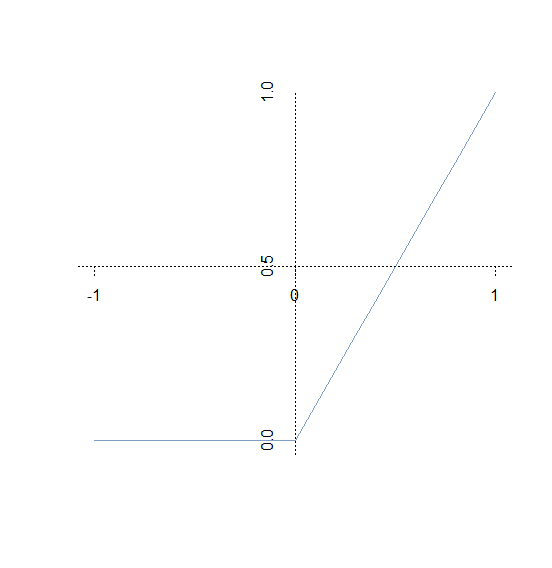
ReLU函数:公式为y=max(0,x)即:if(x<0):y=0if(x>=0):y=x图像为:
激活函数是要求定义域为 R ,且在定义域内处处可导的。对于上面的ReLu函数,在0的方,可以设置其导数为0或1。激活函数主要用来做线性变换,除非极特殊情况(例如:将输入加权求和后直接输出)是不会使用线性回归的。
在本文中,主要使用sigmoid函数,sigmoid函数又称为logistic函数,其函数形式为:
y=11+e−x
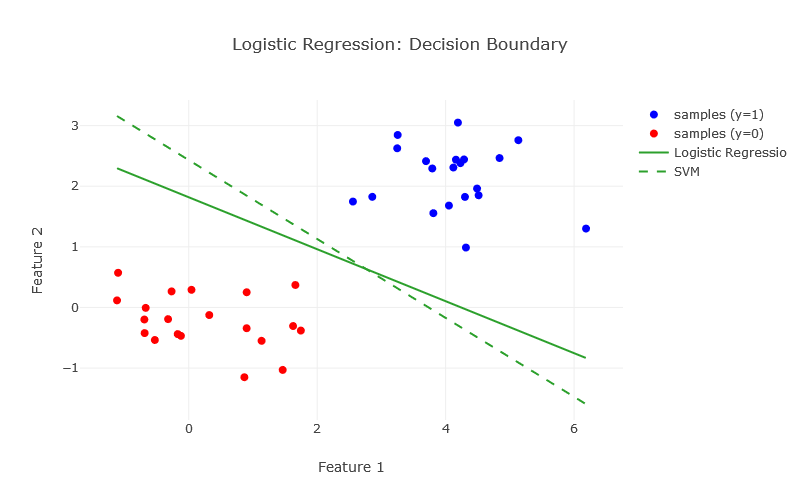
它主要用于二分分类,而二分分类就是将数据分为两类,例如:根据空气温度、湿度、云高等信息将天气分为晴天或非晴天。而他能够作为二分分类的一个非常重要的原因就是他的值域为 (0,1) ,正是由于这个特点,他可以将输入的参数能够很好的向概率映射。
另外当 x 远远大于0的时候,y 会无限趋近于1;当 x 远远小于0的时候,y 又无限趋近于0。使用sigmoid进行二元分类的效果:
(图片来源:Logistic Regression – Geometric Intuition1.2 梯度下降法
在说完了激活函数之后,我们还剩下一个问题如何确定 w 和
b 呢?因为我们之前并不知道 w 和b ,因此需要使用样本来训练出 w 和b 。我们使用梯度下降法来得到 w 和b 。关于梯度下降法,可以参考一下文章:- 机器学习中的数学(1)-回归(regression)、梯度下降(gradient descent)·LeftNotEasy
- 梯度下降法步长的取值范围·袁文彬
- [Machine Learning]梯度下降法的三种形式BGD、SGD以及MBGD·POLL
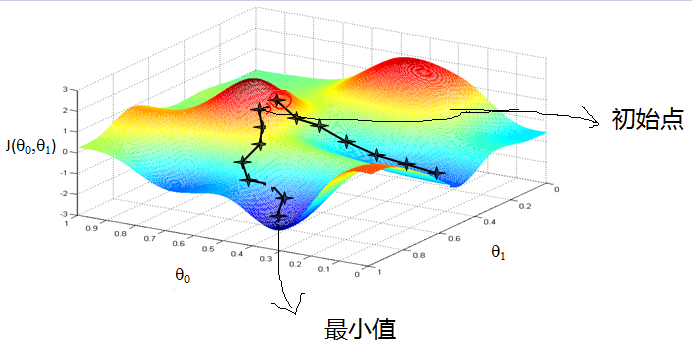
梯度下降法的基本思路就是:先随机初始化一个 w 和
b 。然后根据该 w 和b 求出相应的预测值 y^ ,在根据误差反向修正 w 和b 。不断迭代使误差最小,来达到求出一个 w 和b 使误差最小的目的。如下图所示:
(图片来源:博客园)
在上图中,我们先初始化一个随机的 w 和b ,当然此时的误差可能非常大。然后求 w 和b 对误差的偏导,并向梯度下降的方向修正,随着不断的修正,误差会不断减小,当达到误差最小值时的 w 和b 就是我们模型使用的参数。1.2.1 初始化 w 和
b 在神经网络使用前需要先初始化 w 和
b 。(1) w 的初始化
初始w 一般采用随机初始化的方法,初始化的个数和前面传入参数的个数相同,例如,假设有三个传入参数 x1,x2,x3 那么初始化三个 w 则为:import numpy w = (numpy.random.random(3)*0.01).reshape(3,1)[[ 0.00380803] [ 0.00945647] [ 0.00059899]]一般在
w 初始化的过程中都会乘上0.01,使他小于0.01。这样做的目的是为了使 w 和x 加权求和的结果较小,如果加权求和的结果很大,那么例如在sigmoid函数中,他的梯度会十分小,下降十分慢。(2)b的初始化
而 b 的初始化就简单了,直接等于0就可以了,当然也可以随机初始化1.2.2 正向传递
正向传递就是从前向后计算,其计算的过程为:
(图片来源:吴恩达神经网络课件)
计算过程也是相当简单,公式为:
z=wTx+ba=σ(z)=11+e−z 其中第一个公式是相加求和的过程,第二个公式是使用激活函数做线性变换的过程,在神经元中的计算就是这两步。
使用python编程如下:
from sklearn import datasets import numpy as np # 获取计算数据 iris = datasets.load_iris() x = iris['data'][:100].T y = iris['target'][:100].T # 初始化w和b np.random.seed(1) w = (np.random.random(x.shape[0])*0.01).reshape(x.shape[0],1) b = 0 # 正向传递 z = np.dot(w.T,x)+b a = 1/(1+np.exp(-z))输出a为:
array([[ 0.51176926, 0.5106609, 0.51081246, 0.51052831, 0.51184505, 0.51295288, 0.51114382, 0.51148511, 0.50995984, 0.51076538, 0.51244182, 0.51127673, 0.51048115, 0.50996, 0.51339837, 0.5141651, 0.51295277, 0.5118448, 0.51300994, 0.51238476, 0.51190196, 0.51228032, 0.51142814, 0.51163601, 0.51127682, 0.51076517, 0.51163622, 0.51187349, 0.51169348, 0.51081254, 0.51073675, 0.51205298, 0.51287778, 0.51344578, 0.51076538, 0.51112504, 0.51218602, 0.51076538, 0.51013982, 0.51158931, 0.51174058, 0.50905949, 0.51049983, 0.51196728, 0.51246041, 0.51063224, 0.51230925, 0.51070828, 0.51233763, 0.51130509, 0.51411624, 0.51356665, 0.5139077 , 0.51085794, 0.51295104, 0.51196642, 0.513718 , 0.51018583, 0.51308412, 0.51134081, 0.50957006, 0.51268573, 0.51097233, 0.51263875, 0.51204194, 0.51362368, 0.51237325, 0.5116639 , 0.5115586 , 0.51117101, 0.51327242, 0.51238305, 0.51220285, 0.51230771, 0.51287567, 0.51333955, 0.51318812, 0.51367049, 0.51261004, 0.51137954, 0.51088678, 0.5108112 , 0.51181492, 0.51232581, 0.51216486, 0.51358536, 0.51369929, 0.51169167, 0.51222206, 0.51121792, 0.51132248, 0.51281869, 0.51163497, 0.51011004, 0.51168215, 0.51225074, 0.51214631, 0.51266729, 0.51064972, 0.5119663 ]])1.2.3 损失函数(Loss Function )与成本函数(Cost Function )
损失函数又叫做误差函数(error function)用来计算单个样本预测结果与实际结果的误差,存在数据 {(x(1),y(1)),(x(2),y(2)),⋯,(x(n),y(n))} ,我们希望 y^=y ( y^ 表示预测值,即前面的 a ),误差在许多时候是无法消除的,而为了使预测值更接近于实际值,即
y^≈y ,而损失函数就是衡量预测值与真实值差别的函数一般来说损失函数公式为:
L(y^,y)=12(y^−y)2损失函数是衡量单个训练样本的表现,而成本函数是整个训练样本的表现。成本函数公式为:
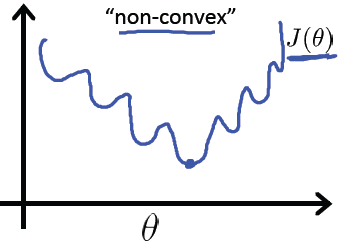
J(w,b)=1m∑i=1mL(y^(i),y(i))而我们的目的是选择出一个 w 和b 来使成本函数 J(w,b) 最小。但是对于sigmoid函数来说则不能使用这个损失函数函数,因为他对于sigmoid函数来说是一个非凸函数(虽然我试了半天也没有证明出来),存在许多极小值,有可能会陷入局部拟合状态,在网上经常会看到这样一张图:
我们的目的是使其全局最优,但是非凸函数往往会陷入到局部最优。因为在神经网络的中使用的是梯度下降法(顺着梯度下降),因为对非凸函数做梯度下降时容易陷入局部拟合的特点,使用梯度下降法一般会避免非凸函数。因此对于sigmoid函数来说它将使用一个不同的损失函数,起到衡量误差的作用。其损失函数为:
L(y^,y)=−(ylogy^+(1−y)log(1−y^))此时成本函数公式为:
J(w,b)=1m∑i=1nL(y^(i),y(i))=−1m∑i=1m[y(i)log(y^(i))+(1−y(i))log(1−y^(i))]1.2.4 误差反向传播
在上面提到,我们的目的是找到一个 w 和
b 的值来使成本函数 J(w,b) 的值最小,因此计算 J(w,b) 对 w 的偏导数为:因为:
z=w1x1+w2x2+by^=σ(z)=11+e−zL(y^,y)=−(ylogy^+(1−y)log(1−y^))J(w,b)=1m∑i=1nL(y^(i),y(i)) 所以变量在损失函数上的偏导数为
∂L(y^,y)∂w当w为w1时=∂(−(ylogy^+(1−y)log(1−y^)))∂w=(−yy^+1−y1−y^)×∂y^∂w=(−yy^+1−y1−y^)×∂(11+e−z)∂w=(−yy^+1−y1−y^)×y^(1−y^)×∂z∂w=(−yy^+1−y1−y^)×y^(1−y^)×∂(w1x1+w2x2+b)∂w=(−yy^+1−y1−y^)×y^(1−y^)×x1=(y^−y)×x1
相应的 wi 时 ∂L(y^,y)∂wi=(y^−y)×xi
b (可以看做其对应的x=1 )时 ∂L(y^,y)∂b=y^−y变量在成本函数上的偏导数为:
∂J(wi,b)∂wi=∂(1m∑i=1nL(y^(i),y(i)))∂wi=1m∑i=1n∂(L(y^(i),y(i)))∂wi=∑i=1n(y^−y)×xim因此
∂J(wi,b)∂wi=∑i=1n(y^−y)×xim∂J(wi,b)∂b=∑i=1n(y^−y)m上面求出了成本函数在 w 上的偏导数,下面就可以对
w 和 b 进行修正,修正方式为原来的值减去一个学习率乘以偏导数的积,即使用下面的公式修正:
w : w=w−α∂J(w,b)∂w
b :b=b−αJ(w,b)
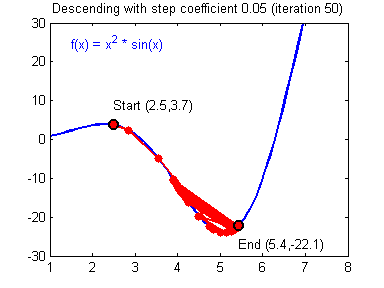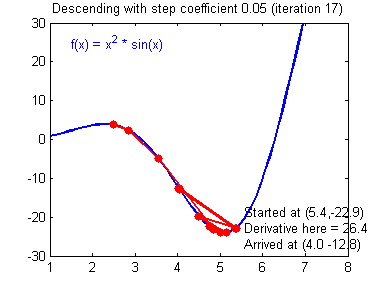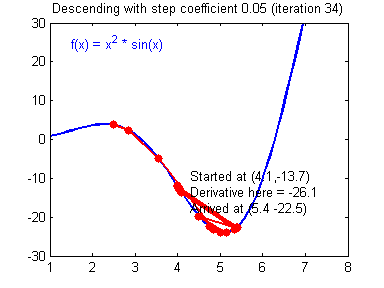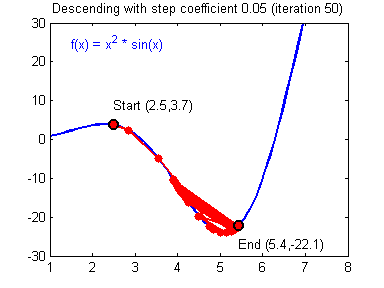
由于偏导数本身自带方向,因此在这里不需要考虑方向的问题。对于学习率的选择一般在0-1之间,例如: 0.1,0.005,0.001,0.0005 等等。较大的学习率可以使梯度下降速度较快,能使模型更快的达到较好结果的位置,但是在最低点的时候会不断抖动,不易落到最低点,如下图所示:
(图片来源:吴恩达神经网络作业)
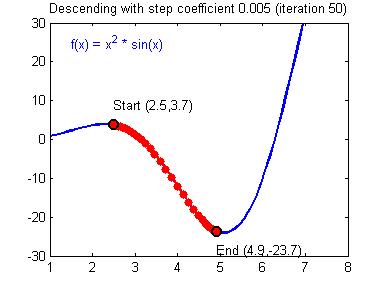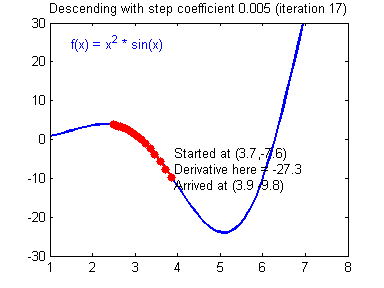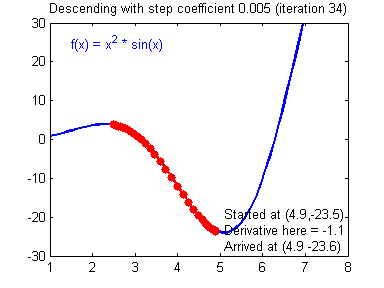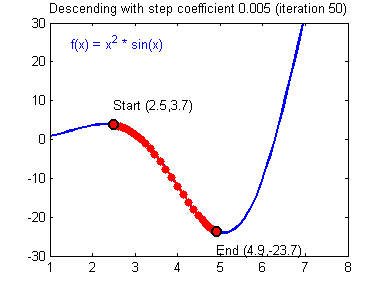
而较小的学习率梯度下降速度慢,但是在最低点附近时候,能够较好的落到最低点附近,如下图所示:
(图片来源:吴恩达神经网络作业)现在也有许多方法来避免这个问题例如:学习率动态变化、基于惯性的梯度下降法等等。
1.3 公式总结
综上所述,在神经元训练的过程中会有三个过程:
(1)正向传递
总前向后计算,所用到的公式:
z=wTx+by^=σ(z)=11+e−z
(2)计算误差
所用到的公式:
J(w,b)=−1m∑i=1m[y(i)log(y^(i))+(1−y(i))log(1−y^(i))]
(3)反向传播
根据梯度下降法,从后向前反向修正 w 和b dw=∂J(w,b)∂w=x⋅(y^−y)mda=∂J(wi,b)∂b=y^−ymw=w−α×dwb=b−α×db使用python代码如下(采用鸢尾花数数据集):
from sklearn import datasets import numpy as np # 获取计算数据 iris = datasets.load_iris() x = iris['data'][:100].T y = iris['target'][:100].T m = x.shape[1] alpat = 0.005 iterations_number = 20000 # 初始化w和b np.random.seed(1) w = (np.random.random(x.shape[0])*0.01).reshape(x.shape[0],1) b = 0 for i in range(iterations_number): # 正向传递 z = np.dot(w.T,x)+b a = 1/(1+np.exp(-z)) # 计算误差 J = - np.sum(y * np.log(a)+(1-y)*np.log(1-a))/m if(i%10000 == 0): print("当前迭代次数"+str(i)+"\t误差:"+str(J)) # 反向传递 dw = np.dot(x,(a-y).T)/m db = np.sum(a-y)/m w = w - alpat*dw b = b - alpat*db # 预测数据 z = np.dot(w.T,x)+b a = 1/(1+np.exp(-z)) y_predict = (a > 0.5 )+ 0 print("预测结果:"+str(y_predict)+"\n实际结果:"+str(y)+"\n预测准确率:"+str((1-np.sum(np.abs(y_predict-y))/m)*100)+"%")输出结果:
当前迭代次数0 误差:0.69281000899 当前迭代次数10000 误差:0.0149878476054 预测结果:[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]] 实际结果:[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1] 预测准确率:100.0%2. 多层神经网络
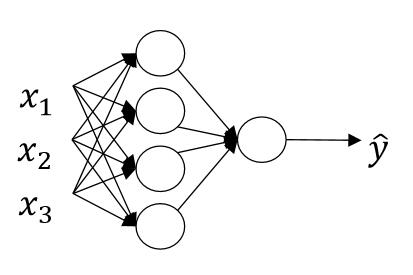
有了上面神经元的概念,那么接下来的多层神经网络就比较好理解了,多层神经网络就是多个神经元所组成的网络。
(图片来源:吴恩达神经网络课件
其实神经网络也很容易明白,即上一层节点的输出,等于下一层节点的输入。这里介绍几个概念“输入层”、“隐藏层”、“输出层”
在上图中, x1,x2,x3 是输入层,一般情况下输入层会被省略,在上图中也没有画出输入层节点;在中间的三个是“隐藏层”;最后面的一个圆是“输出层”。上图中没有画出输入层,只画出了一个输出层和一个隐藏层。一个神经网络中必有一个输入层和一个输出层,有0个或多个隐藏层。输出层一般只有一个神经元,但是有时也会有多个输出因此有多个神经元。
我们现在做如下定义:上标“ [i] ”表示当前为第 i 层的节点,隐藏层为第0层忽略掉。上标“
(j) ”表示该层的第 j 个节点。因此上图中,- 隐藏层节点的输入可以表示为
x[1]1,x[1]2,x[1]3 ;- 隐藏层第一个节点的输入可以表示为 x[1](1)1,x[1](1)2,x[1](1)3 ;
- 隐藏层的第四个节点的输入可以表示为 x[1](4)1,x[1](4)2,x[1](4)3 ;
- 输出层的输入可以表示为 x[2]1,x[2]2,x[2]3,x[2]4 (由于只有一个输出层节点,因此有无上标是一样的)。
2.1 梯度下降法
2.1.1 正向传递
由上面定义得对于隐藏层第二个节点来说:输入为 x[1](2) ,权重 w[1](2) ,截距 b[1](2) ,输出 a[1](2) 。
他的正向传递计算公式为:
z[1](2)=w[1](2)Tx[1](2)+b[1](2)a[1](2)=σ(z[1](2))=11+e−z[1](2)
我们再抽象掉节点个数,即隐藏层公式来说:输入为 x[1] ,权重 w[1] ,截距 b[1] ,输出 a[1] 。
他的计算公式为:
z[1]=w[1]Tx[1]+b[1]a[1]=σ(z[1])=11+e−z[1]
因为上一层节点的输出等于下一层节点的输入,因此存在: x[2]=a[1] ,因此上图中的输出层的计算可以表示为:
z[2]=w[2]Tx[2]+b[2]=w[2]Ta[1]+b[2]a[2]=σ(z[2])=11+e−z[2]因此,对于
x[1]=⎡⎣⎢⎢⎢⎢⎢⎢x(1)1x(1)2⋮x(1)nx(2)1x(2)2⋮x(2)n⋯⋯⋯x(m)1x(m)2⋮x(m)n⎤⎦⎥⎥⎥⎥⎥⎥(上标"(i)"表示第i个样本)
w[1]=⎡⎣⎢⎢⎢⎢⎢⎢w[1](1)1w[1](1)2⋮w[1](1)nw[1](2)1w[1](2)2⋮w[1](2)n⋯⋯⋯w[1](p)1w[1](p)2⋮w[1](p)n⎤⎦⎥⎥⎥⎥⎥⎥
b[1]=[b[1](1)b[1](2)⋯b[1](p)]
可以求出
a[1]=⎡⎣⎢⎢⎢⎢⎢⎢a[1](1)1a[1](1)2⋮a[1](1)pa[1](2)1a[1](2)2⋮a[1](2)p⋯⋯⋯a[1](m)1a[1](m)2⋮a[1](m)p⎤⎦⎥⎥⎥⎥⎥⎥
而此层的 a 又是下一层的x ,因此就可以向下计算。所以上图中最后的公式为:
z[1]=w[1]Tx[1]+b[1]a[1]=σ(z[1])=11+e−z[1]x[2]=a[1]z[2]=w[2]Tx[2]+b[2]a[2]=σ(z[2])=11+e−z[2]y^=a[2]
对于更多的隐藏层来说,例如,隐藏层个数变为2,那么只需要不断地进行循环即可,即:foriin1:L
z[i]=w[i]Tx[i]+b[i]
a[i]=σ(z[i])=11+e−z[i]
x[i+1]=a[i]
y^=a[i]2.1.2 损失函数(Loss Function )与成本函数(Cost Function )
和神经元没什么区别…略
2.1.3 误差反向传播
误差反向就是反向推导回去,如果明白了上面的内容也并不难。
我们从后向前推导:
(1). 计算预测结果对误差的偏导数;
因为:
L(y^,y)=−(ylogy^+(1−y)log(1−y^))J(w,b)=1m∑i=1nL(y^(i),y(i))
所以:
∂J(wi,b)∂y^=∂(1m∑i=1nL(y^(i),y(i)))∂y^=1m∑i=1n∂(L(y^(i),y(i)))∂y^=1m(−yy^+1−y1−y^)
(2). 计算输出层权值对误差的偏导数;
因为:
∂J(wi,b)∂y^=1m(−yy^+1−y1−y^)y^=a[2]a[2]=σ(z[2])=11+e−z[2]z[2]=w[2]Tx[2]+b[2]
所以:
∂J(wi,b)∂w[2]=∂y^∂w[2]×∂J(wi,b)∂y^=(a[2]−y)T⋅x[2]m
同理:
∂J(wi,b)∂b[2]=(a[2]−y)Tm(3). 修正输出层节点间的 w 和
b
w[2]:w[2]=w[2]−α∂J(w,b)∂w[2]b[2]:b[2]=b[2]−αJ(w,b)(4). 计算隐藏层的输出对误差的偏导数
因为:
∂J(wi,b)∂y^=1m(−yy^+1−y1−y^)y^=a[2]a[2]=σ(z[2])=11+e−z[2]z[2]=w[2]Tx[2]+b[2]x[2]=a[1]
所以:
∂J(wi,b)∂a[1]=∂y^∂a[1]×∂J(wi,b)∂y^=w[2]T⋅(a[2]−y)m(5). 计算隐藏层的权值对误差的偏导数
因为:
∂J(w,b)∂a[1]=w[2]T×(a[2]−y)mz[1]=w[1]Tx[1]+b[1]a[1]=σ(z[1])=11+e−z[1]
所以:
∂J(wi,b)∂w[1]=∂a[1]∂w[1]×∂J(w,b)∂a[1]=a[1]T(1−a[1]T)⋅x[1]×∂J(w,b)∂a[1]T
(算不过来了...)
同理:
∂J(wi,b)∂b[1]=a[1]T(1−a[1]T)×∂J(w,b)∂a[1]T(晕晕晕......快晕了......)
2.2 公式总结
好吧,我已经晕了,总结一下公式,上标“ [i] ”表示当前层的信息, L 表示隐藏层和输出层的共计个数。
(1)正向传递
总前向后计算,所用到的公式foriin1:L
z[i]=w[i]Tx[i]+b[i]
a[i]=f(z[i])=σ(z[i])=11+e−z[i]
x[i+1]=a[i]
y^=a[i](2)计算误差
所用到的公式:
J(w,b)=−y⋅log(y^)+(1−y)log(1−y^)m(3)反向传播
根据梯度下降法,从后向前反向修正 w 和b
dy^=∂J(wi,b)∂y^=1m(−yy^+1−y1−y^)
da[L]=∂J(wi,b)∂a[L]=dy^
foriinL:1
dz[i]=∂a[i]∂z[i]×da[i]=f′(a[i])×da[i]=σ′(a[i])×da[i]=a[i](1−a[i])×da[i]
dw[i]=∂z[i]∂w[i]⋅dz[i]T=x[i]⋅dz[i]T
db[i]=∂z[i]∂b[i]⋅dz[i]=dz[i]
dx[i]=∂z[i]∂x[i]⋅dz[i]=w[i]⋅dz[i]
w[i]=w[i]−α×dw[i]
b[i]=b[i]−α×db[i]
da[i−1]=dx[i]使用python代码如下(采用鸢尾花数数据集,在这里隐藏层使用tanh函数):
from sklearn import datasets import math import numpy as np def sigmoid(x): return 1/(1+np.exp(-x)) def tanh(x): return (np.exp(x)-np.exp(-x))/(np.exp(x)+np.exp(-x)) def sigmoid_T(yhat): return (1-yhat)*yhat def tanh_T(yhat): return 1-yhat**2 def get_wb(last_node_number,this_node_number,n = 0.01): w = np.random.random(last_node_number*this_node_number)*n w = np.reshape(w,(last_node_number,this_node_number)) b = np.random.random(this_node_number)*n b = np.reshape(b,(1,this_node_number)) return w,b def dj2dz(y,yhat): return (1-y)/(1-yhat)-y/yhat iris = datasets.load_iris()['data'][0:100] y = datasets.load_iris()['target'][0:100] x = iris.T y = np.reshape(y,(1,-1)) alpat = 0.05 m = x.shape[1] iterations_number=25000 # 隐藏层每个层中节点个数 lay_node_number = [3] # 隐藏层和输出层的激活函数和激活函数的反函数 func = [tanh,sigmoid] funct = [tanh_T,sigmoid_T] # # 隐藏层每个层中节点个数 # lay_node_number = [10,3] # # 隐藏层和输出层的激活函数和激活函数的反函数 # func = [tanh,tanh,sigmoid] # funct = [tanh_T,tanh,sigmoid_T] # 加入输入层和输出层的节点个数 lay_node_number.insert(0,x.shape[0]) lay_node_number.append(1) lay_number = len(lay_node_number) # 初始化w和b w = [] b = [] np.random.seed(1) for i in range(lay_number-1): tmp_w,tmp_b = get_wb(lay_node_number[i],lay_node_number[i+1]) w.append(tmp_w) b.append(tmp_b) for j in range(iterations_number): # 正向计算 x_cache = [x] for i in range(lay_number-1): z = np.dot(w[i].T,x_cache[i])+b[i].T a = func[i](z) x_cache.append(a) y_hat=x_cache[len(x_cache)-1] # 计算误差 J = - np.sum(y * np.log(y_hat)+(1-y)*np.log(1-y_hat))/m if(j%1000 == 0): print("当前迭代次数:"+str(j)+"\t\t误差:"+str(J)) # 反向传播 da = dj2dz(y,y_hat) for i in range(len(w)-1,-1,-1): dz = da * funct[i](x_cache[i+1]) dx = np.dot(w[i],dz)/m dw = np.dot(x_cache[i],dz.T)/m db = np.sum(dz.T,axis=0,keepdims=True)/m w[i] = w[i] - alpat*dw b[i] = b[i] - alpat*db da = dx # 预测结果 a = x for i in range(lay_number-1): z = np.dot(w[i].T,a)+b[i].T a = func[i](z) y_predict = (a > 0.5 )+ 0 print("预测结果:"+str(y_predict)+"\n实际结果:"+str(y)+"\n预测准确率:"+str((1-np.sum(np.abs(y_predict-y))/m)*100)+"%")输出结果:
当前迭代次数:0 误差:0.693080329612 当前迭代次数:1000 误差:0.494298198202 当前迭代次数:2000 误差:0.0533060416615 当前迭代次数:3000 误差:0.0198922213283 当前迭代次数:4000 误差:0.011537471035 当前迭代次数:5000 误差:0.0079584332934 当前迭代次数:6000 误差:0.00601276052925 当前迭代次数:7000 误差:0.00480316927673 当前迭代次数:8000 误差:0.00398362148443 当前迭代次数:9000 误差:0.00339409719053 当前迭代次数:10000 误差:0.00295095246304 当前迭代次数:11000 误差:0.00260641671979 当前迭代次数:12000 误差:0.00233131261355 当前迭代次数:13000 误差:0.00210685474327 当前迭代次数:14000 误差:0.00192042332913 当前迭代次数:15000 误差:0.00176323853379 当前迭代次数:16000 误差:0.00162901015476 当前迭代次数:17000 误差:0.00151311778557 当前迭代次数:18000 误差:0.00141209385204 当前迭代次数:19000 误差:0.00132328687338 当前迭代次数:20000 误差:0.00124463585068 当前迭代次数:21000 误差:0.00117451533242 当前迭代次数:22000 误差:0.00111162667063 当前迭代次数:23000 误差:0.00105492020129 当前迭代次数:24000 误差:0.00100353857836 预测结果:[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]] 实际结果:[[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]] 预测准确率:100.0%2.3 关于随机初始化参数
为什么要随机初始化 w 而不能直接都为0呢?假设在同一层有两个节点,他们的初始化的
w 都为0,那么他们的正向传递的结果会相同,反向传递的结果也相同,那么最终这两个节点的 w 会完全相同。那么这两个节点的作用实际上和一个节点没有什么区别,因此
w 是需要随机初始化的。
- tanh函数:公式为
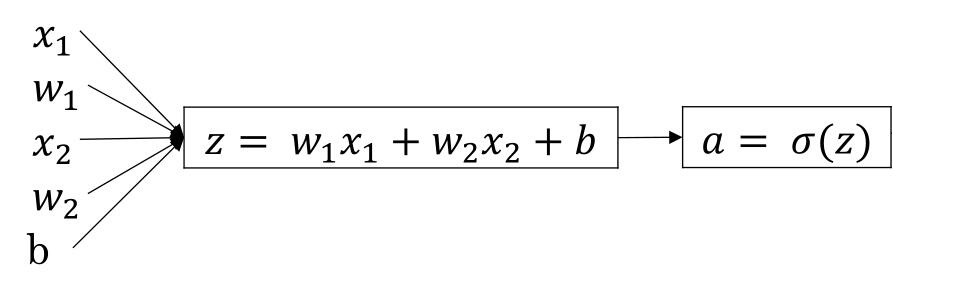















 1876
1876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









