









背景
GB200 NVL72就目前来看可谓是超级巨无霸级别的存在,72个B200的GPU+36个Grace的CPU放在一个服务器里面,GPU显存13500GB(4090标配的才16G,接近800倍),内存17T,显内存总的达到了30TB(17T+13.5T)。光是功耗问题就必须用液冷,据说早期功耗问题都都一度成为可能流产的原因。本文简单记录NVL72的一些关键信息,仅根据官网介绍分析,存在纰漏仅供参考。
GB200 NVL72实物图:一个rack(机柜)。相当于“一张机柜这么大的显卡”

要点
- GB200 NVL72是一个服务器,需要机柜级别才能放下的服务器
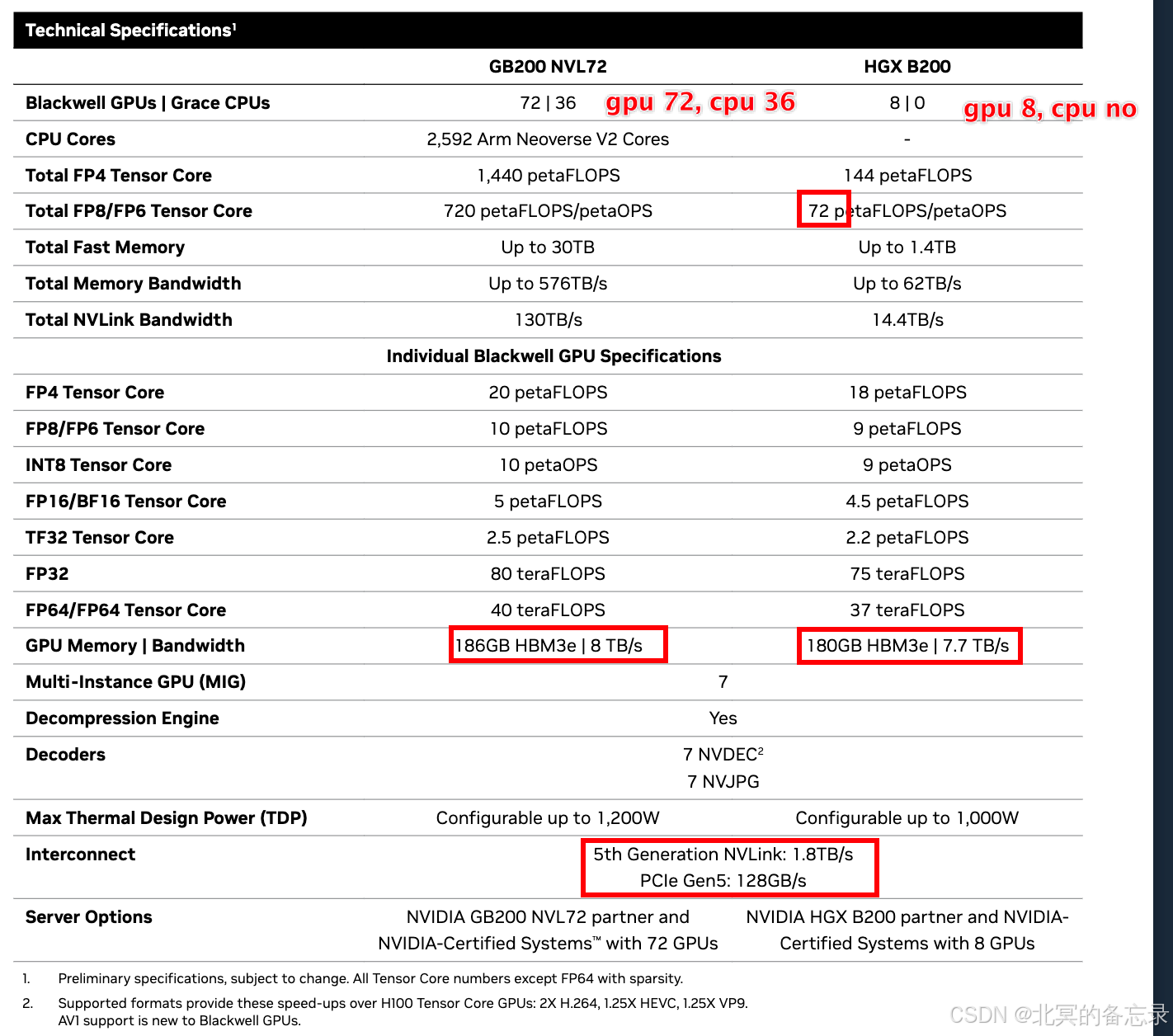
- GB是G和B的合称,G代表的是CPU,表示Grace CPU ;B代表的是GPU的型号,Blackwell GPU。类似HGX B200就只有GPU(8个B200的)
- NVL72中NVL是NVLink,72表示72个GPU,表示有72个GPU通过NVLink进行机内通信。类似的还有NVL2表示2个GPU的服务器。
- GB200 NVL72是由36 个 Grace CPU 和 72 个 Blackwell GPU。
- GB200 NVL72 是一款液冷机架级解决方案
- GB200 NVL72 使用的核心组件芯片不是多个B200和多个Grace CPU独立组成,而是一个叫做GB200 Grace Blackwell 的超级芯片,也叫Blackwell Superchip。 该超级芯片应该是使用类似chiplet技术,做了2+1+2, 把2颗B200 + 1颗Grace CPU + 2颗Blackwell Tensor Core GPU组合到一起,使用的是 NVLink-C2C的互联技术。说白了就是GPU之间通过NVLink高速高带宽低延迟总线互联到一起。(?可能是fullmesh的结构)(可能有误,仅供参考)。 主要是1 Grace CPU + 2 B200 GPU
- 另外每个计算托盘上放了两颗超级芯片,也就是2 CPU + 4 GPU。包含4颗ConnectX-8SuperNIC芯片与1颗BlueField-3DPU芯片。 每个GPU和网卡是1:1的配置。另外BF3大概率是作为机头配合CPU做一些卸载动作,比如snap。
- 使用第二代 Transformer 引擎,支持FP4,主要支持FP8
- 使用第五代 NVLink
- 使用新一代 Tensor core,支持微缩放格式。 (具体哪一代?)
- 72-GPU机架
- GPU到GPU互连通过NVlink可以达到1.8T/s
- GB200 NVL72使用的网卡是BlueField-3 DPU 提供400GB/s的性能
- FP8的Tensor,可以达到720 PFLOPS。72个GPU,所以单个GPU的FP8是10P,也就是10个1000T的
- GPU内存使用的是HBM3e,带宽:13.5 TB 容量。576 TB/s的内存带宽。对比来看一张4090的卡GPU内存容量有12G,16G,24G。 这个13500GB容量。1.35万GB对比12GB。
- CPU内存使用的是LPDDR5X。 17 TB的容量。内存带宽 18.4 TB/s。 相当于1.7万BG的内容,VS笔记本16GB的容量。支持error-correction code (ECC)校验。GPU+CPU总内存达到30.5T,也就是30万GB的内存。
- 形态:一个机柜大小(rack)
- 功耗120Kw。普通台式机ATX电源850W。普通该服务器2U的一半1.2Kw。相当于100个2U服务器(也合理 72个GPU+36个CPU)。现在的机房一般单机柜10Kw?记不清了。
- PCIe Gen5的,Gen5的单lane可以32GT/s, 如果是32 lanes,32*32/8=128GB/s的速率。不过对比NVLink 也是5代,直接干到1.8TB/s注意还是大B。1.8T/128G=14个 x32的PCIe Gen5。 差不多28个x16的 PCIe Gen5。如果用4090这种x16的显卡来看。就是NVLink的速率金手指要32张4090的金手指排在一起这么长。(速记:14倍于PCIe Gen5的x32)
其他照片


参考:
https://www.nvidia.com/en-us/data-center/gb200-nvl72/?ncid=no-ncid
https://nvdam.widen.net/s/wwnsxrhm2w/blackwell-datasheet-3384703
https://xueqiu.com/2671458018/292311609

















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









