







文章目录
背景
DOCA: Data Center-on-a-Chip Architecture,片上数据中心架构。是NVIDIA针对DPU的软件框架。DOCA之于DPU,就相当于CUDA之于GPU。本文介绍的是DOCA SDK中的DOCA Flow模块的基本机制原理,他是DOCA中做数据包处理卸载到硬件处理的框架。本文将介绍DOCA Flow的主要原理是什么?四大规则是什么?三级策略是什么?
在Mellanox BF系列网卡中通过DOCA Flow让数据包处理从CPU上处理卸载到硬件中。它定义了一系列API来支持。并且通过Flow Pipe的方式来进行。 Flow Pipe类似OpenFlow,定义一个范式:以Flow Pipe(FP)为处理单元,每条FP包含多个条目,多条FP可以进行级联处理。
在SDN中使用OpenFlow通信协议来进行定义和管理网络转发规则,让交换机能够被几种控制和管理。在交换机中用OpenFlow table来定义如何处理接收到的数据包。通过该种方式可以提高了网络的灵活性和可管理性,而不用在每个交换机单独配置。比如流量调度、访问控制、QoS…
本文仅是对DOCA Flow原理的一个初步分析。DOCA Flow本质是让CPU处理的卸载到网卡上,网卡从硬件机制上提供了基于DOCA Flow的Flow Pipe的机制,这个机制类似SDN中的openflow,总之是让硬件帮忙做事情,也就是所谓的卸载。目的是为了加速,也是目前整个该方面的软件定义硬件加速的趋势技术。关注数据流动,忽略具体细节,把握本质。
关键点
M3F是条目的4种规则。 Match、MDF、Monitor、Forward
-
Match进行数据
报文头匹配,支持链路层MAC/VLAN/ETHtype、网络层IPv4/6、传输层TCP/UDP/ICMP,以及VXLAN和元数据meta的匹配。 -
MDF是修改报文头,比如隧道的处理
-
MON是处理报文,统计,镜像到某些地方等
-
FWD是转发策略,比如端口、下一“跳"(比如是哪个Pipe),是否丢弃等
-
DOCA Flow是推测是用硬件单元实现FP的创建,并且在硬件verlog设计的时候定义创建FP,并且FP之间进行级联处理,以及FP中可以定义M3F,从而数据包来了之后直接硬件全流程根据配置处理掉。这里涉及到硬件的cache缓存这些“流表”(管道)。
-
Flow Pipe可以根据API动态创建和销毁。数据报文到了之后首先到硬件处理,硬件根据FP的条目进行匹配处理,如果没有则给CPU软件处理。
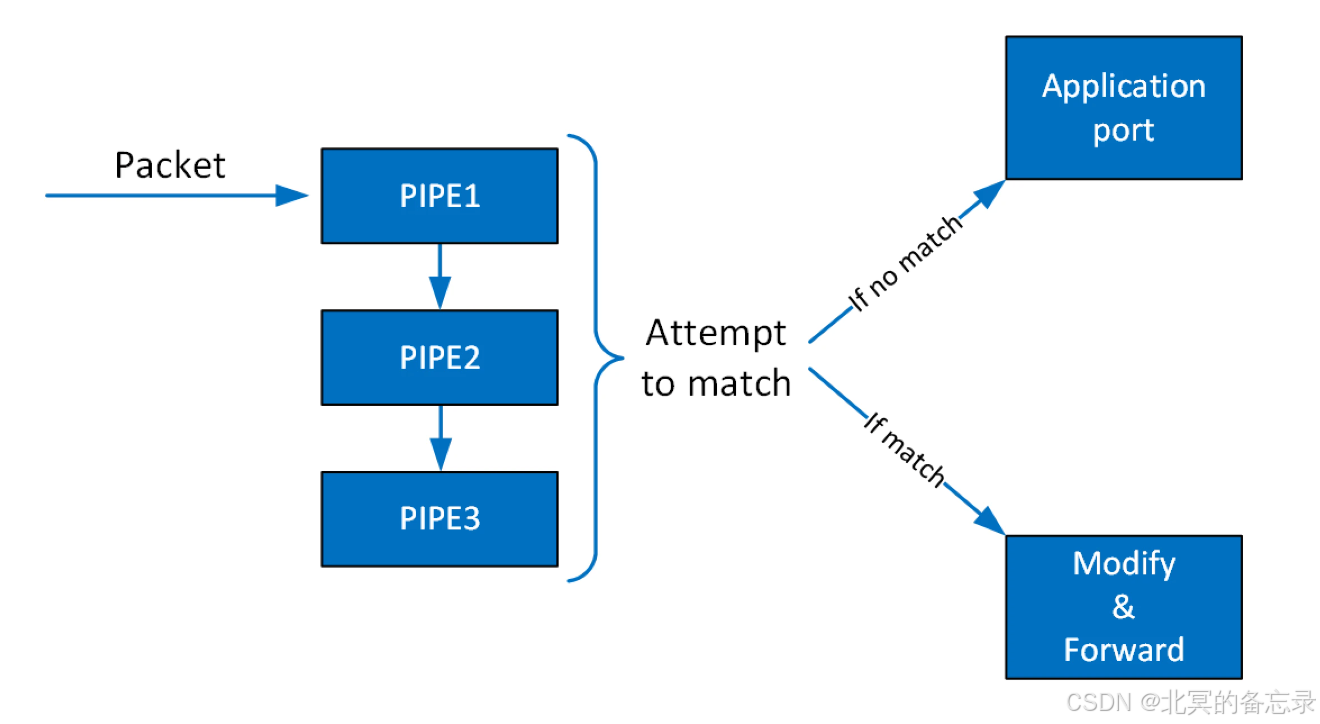
-
另外DOCA Flow依赖DOCA的软件栈,DOCA软件栈主要基于用户态驱动,并且DOCA Flow依赖DPDK,依赖大页所以需要进行大页配置。
-
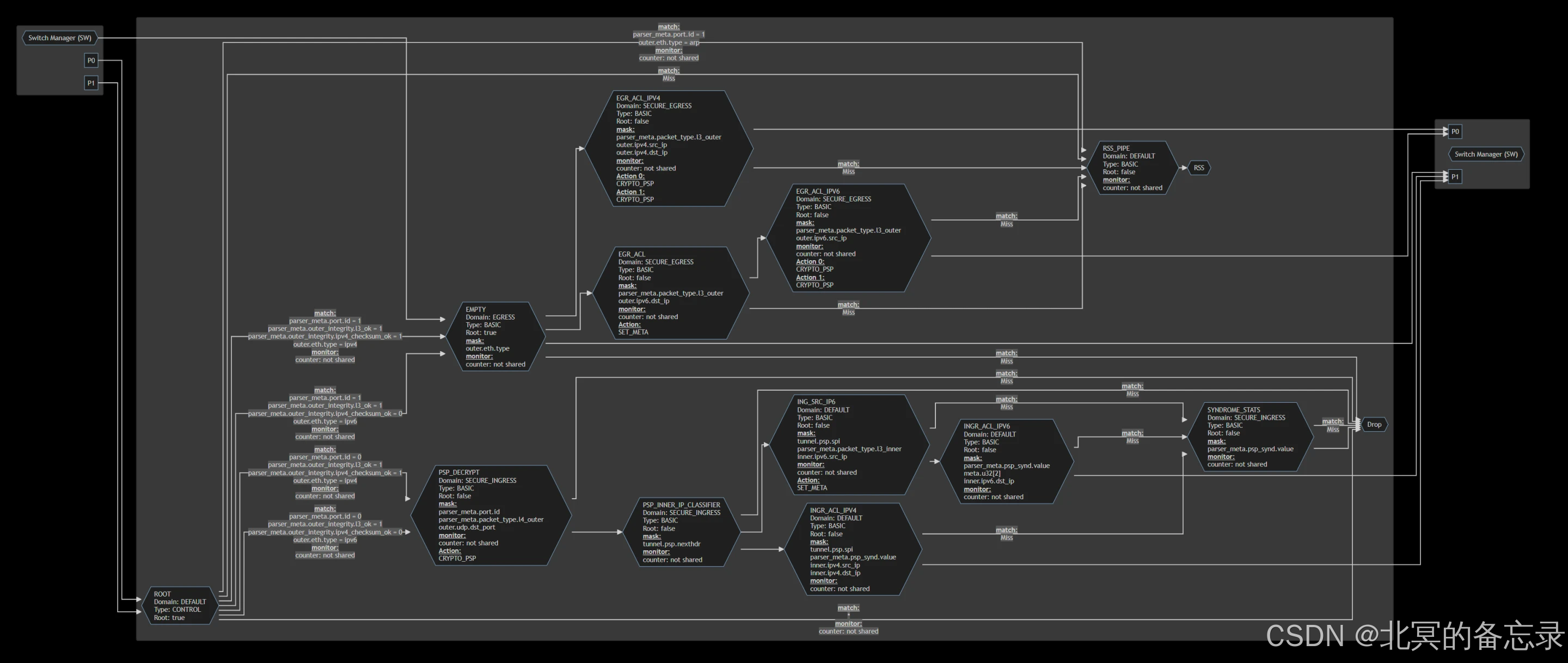
官方架构图
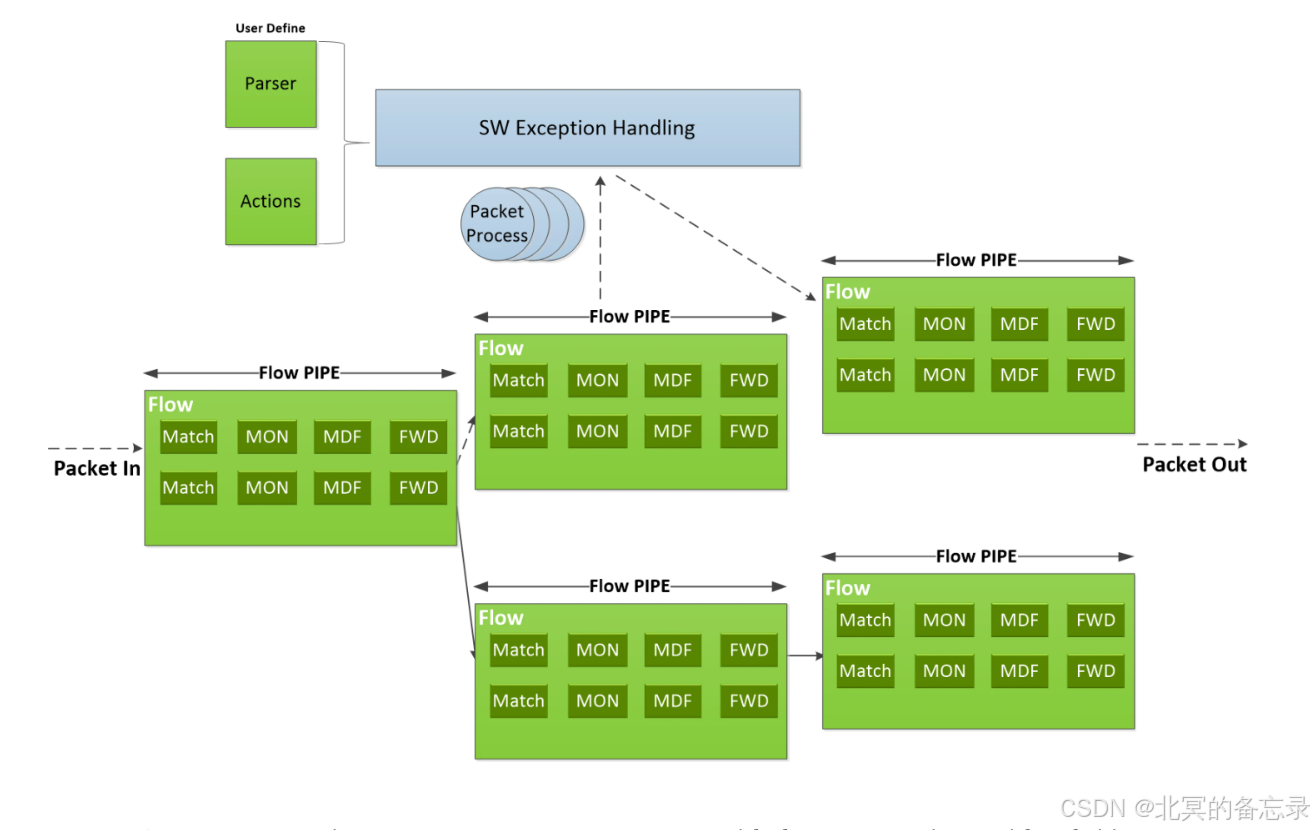
-
不同规则的一些例子图
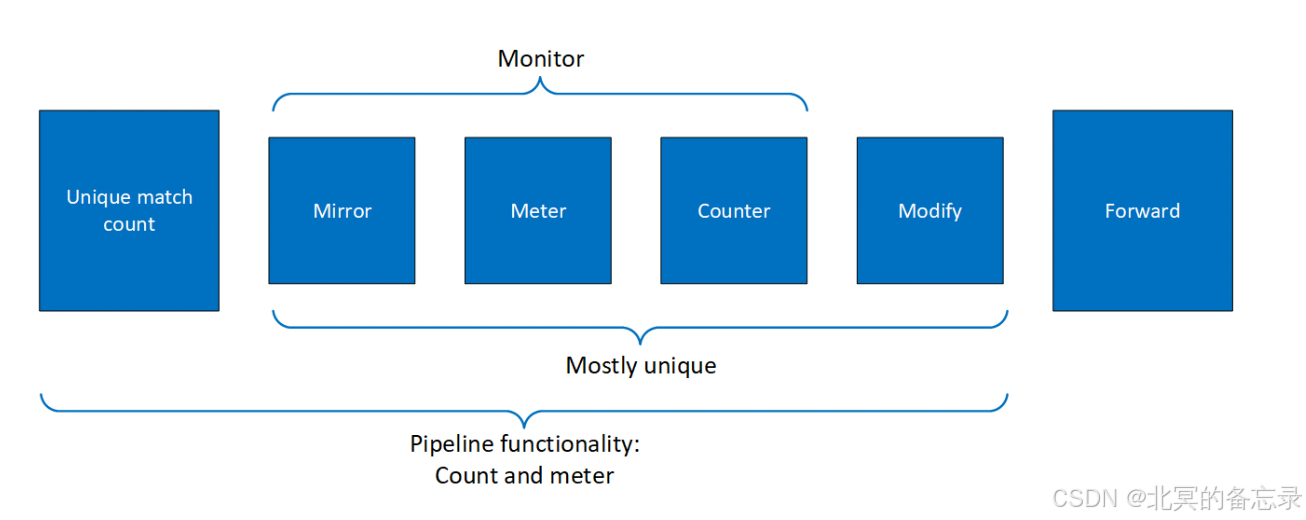
-
创建管道方式:
doca_flow_create_pipe -
在硬件处理上用不同的core(core是硬件的专用处理核)进行处理。不同的queue绑定到core。同一core始终使用相同的 queue_id。DOCA Flow 设计的目标是更有效的方式支持并发。预估并发量是每秒数百万个新条目。每个core都有一个唯一的队列 ID ,目的是为了使 DOCA 引擎不必锁定数据结构。(?该部分具体细节待确认)
-
图中有多个queue,并且在不同的core上执行
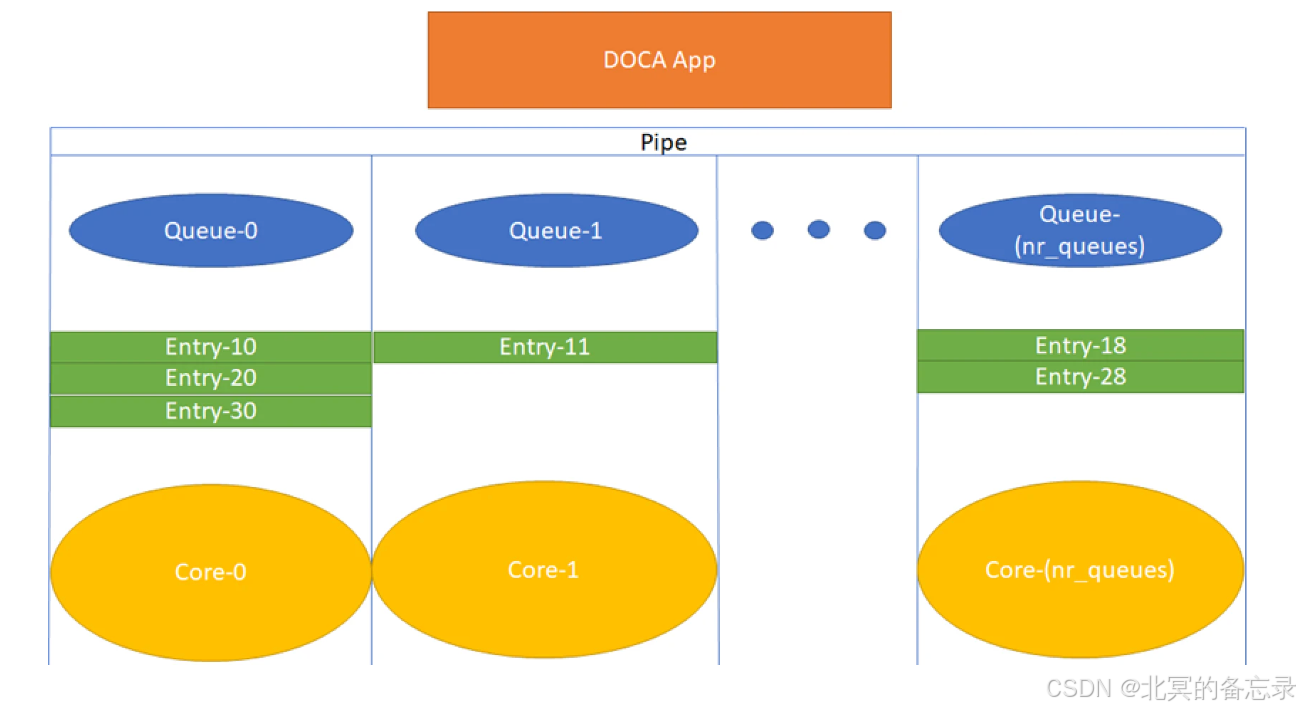
其他
DOCA Flow大页创建方式
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
sudo mkdir /mnt/huge
sudo mount -t hugetlbfs nodev /mnt/huge
- 一个数据流处理例子
综述
本文仅是对DOCA Flow原理的一个初步分析。DOCA Flow本质是让CPU处理的卸载到网卡上,网卡从硬件机制上提供了基于DOCA Flow的Flow Pipe的机制,这个机制类似SDN中的openflow ,总之是让硬件帮忙做事情,也就是所谓的卸载。目的是为了加速,也是目前整个该方面的软件定义硬件加速的趋势技术。关注数据流动,忽略具体细节,把握本质。
参考文档:
https://docs.nvidia.com/doca/sdk/doca+flow+connection+tracking/index.html
https://docs.nvidia.com/doca/archive/doca-v1.3/flow-programming-guide/index.html#introduction
https://docs.nvidia.com/doca/sdk/index.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









