







目录
一 人工智能、机器学习和深度学习的区别
从1956年夏季首次提出“人工智能”这一术语开始,科学家们尝试了各种方法来实现它。这些方法包括SVM、决策树、K近邻、K-Means、回归算法、专家系统、归纳逻辑、聚类等等,但这些都是假智能。直到人工神经网络技术的出现,才让机器拥有了“真智能”。训练深度神经网络的过程就叫做深度学习。
机器学习,实现人工智能的方法之一;深度学习,实现机器学习的技术之一。尤其是2015年以来,人工智能开始大爆发。人工智能的学习能力分为两大部分,知识的学习和思维逻辑的学习重组。前者起点甚低,适应性训练都可以看作是学习;后者起点甚高,至今只可遥望和意味。
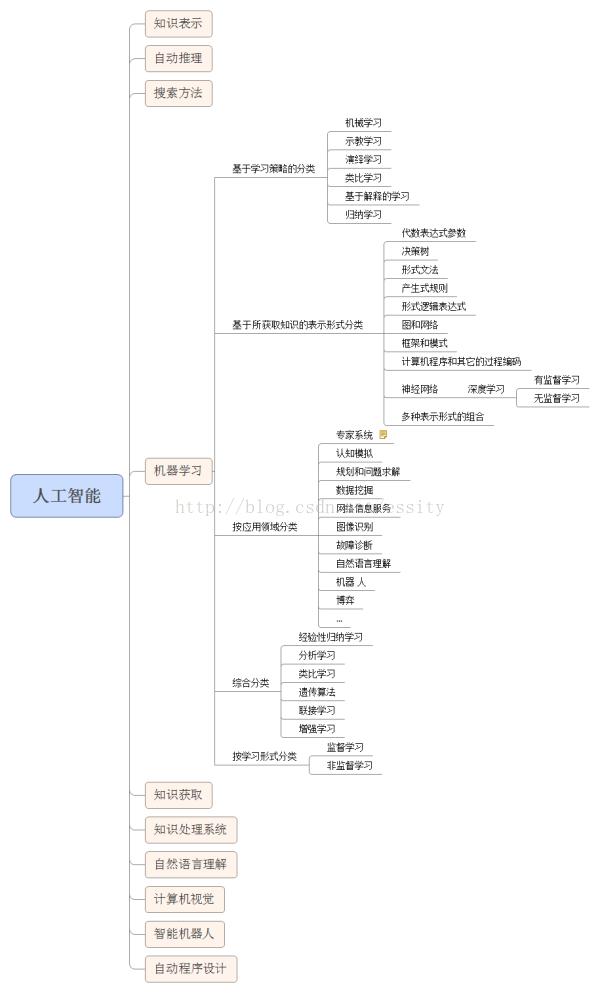
二 机器学习
机器学习是一种概念:不需要写任何与问题有关的特定代码,泛型算法(Generic Algorithms)就能告诉你一些关于你数据的有趣结论。不用编码,你将数据输入泛型算法当中,它就会在数据的基础上建立出它自己的逻辑。机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。
What is Machine Learning?
Two definitions of Machine Learning are offered. Arthur Samuel described it as: “the field of study that gives computers the ability to learn without being explicitly programmed.” This is an older, informal definition.
Tom Mitchell provides a more modern definition: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
Example: playing checkers.
E = the experience of playing many games of checkers
T = the task of playing checkers.
P = the probability that the program will win the next game.
In general, any machine learning problem can be assigned to one of two broad classifications:
Supervised learning and Unsupervised learning.
-----吴恩达《Machine Learning》
三 深度学习
“深度学习”已成为用于描述使用多层神经网络的过程的标准术语, 多层神经网络是一类极为灵活的可利用种类繁多的数学方法以及不同数学方法组合的模型。深度学习的强大之处在于当决定如何最有效地利用数据时, 它能够赋予模型更大的灵活性。 人们无需盲目猜测应当选择何种输入。 一个调校好的深度学习模型可以接收所有的参数, 并自动确定输入值的有用高阶组合。
四 准备
- 目前用计算机处理得较多的数学计算主要分为以下两类:
第一类是数值计算,它以数值数组作为运算对象,给出数值解;计算过程中可能会产生误差累积问题,影响了计算结果的精确性;计算速度快,占用资源少。
第二类是符号计算,它以符号对象和符号表达式作为运算对象,给出解析解;运算不受计算误差累积问题的影响;计算指令简单;占用资源多,计算耗时长。
- 数值计算方法成为了科学计算的重要手段, 它研究怎样利用计算丁.具来求出数学问题的数值解。 数值计算方法的计算对象是微积分 、 线性代数 、 插值与逼近及最小二乘拟合 、 数值积分与数值微分、 矩阵的特征值与特征向量求解 、 线性方程组与非线性方程求根, 以及微分方程数值解法等数学问题, 这些是模式识别 、 数据分析及自动制造等机器学习领域需要应用的数学。
- 符号计算是专家系统等机器学习领域需要应用的数学, 在符号计算中, 计算机处理的数据和得到的结果都是符号。 符号既可以是字母和公式, 也可以是数值, 其运算以推理解析的方式进行, 不受计算误差积累问题闲扰, 汁算结果为完全正确的封闭解或任意精度的数值解, 这意味着符号计算给出的结果能避免因舍人误差而引起的问题。
- 现代科学研究的方法主要有三种:理论论证、科学实验、科学计算。计算机进行科学计算,都必须建立相应的数学模型,并研究其适合于计算机编程的计算方法。科学计算平台已经成为科学研究必要的基础条件平台,有力地推动了科学研究的发展和工程技术的进步。
五 卷积
六 傅里叶变换
七 模型推理部署——基础概念篇
本节内容来自这里。
1 训练(training)vs推理(inference)
训练是通过从已有的数据中学习到某种能力,而推理是简化并使用该能力,使其能快速、高效地对未知的数据进行操作,以获得预期的结果。

训练是计算密集型操作,模型一般都需要使用大量的数据来进行训练,通过反向传播来不断的优化模型的参数,以使得模型获取某种能力。在训练的过程中,我们常常是将模型在数据集上面的拟合情况放在首要位置的。而推理过程在很多场景下,除了模型的精度外,还更加关注模型的大小和速度等指标。这就需要对训练的模型进行一些压缩、剪枝或者是操作上面的计算优化。
我们做算法的最终目的都是希望自己的方法可以真正的应用起来,那么在对模型部署上面,每一个算法工程师都应该有一些基本的sense。下面本文会简单介绍一些推理时比较关注的指标。
2 重要指标
2.1 Throughput 吞吐量
单位时间内所处理的数据量 一般用 推理/秒 或者 样本/秒 衡量。每台服务器的吞吐量对于数据中心能否合算的扩展至关重要。
# 包含并行情况
def calc_ips(batch_size, time):
# 全局进程个数
world_size = (
torch.distributed.get_world_size() if torch.distributed.is_initialized() else 1
)
tbs = world_size * batch_size
return tbs / time
2.2 Latency 延迟
执行一次推理所花的时间,单位一般为ms。低延迟对于实时且快速增长地推理服务至关重要。一般在压测时,我们都是通过增加并发数,来观察 Latency 平均线、90线、 95线和99线
# time_list 为每个请求从发送到返回的时间列表
avg = np.mean(time_list)
cf_90 = max(time_list[:int(len(time_list) * 0.90)])
cf_95 = max(time_list[:int(len(time_list) * 0.95)])
cf_99 = max(time_list[:int(len(time_list) * 0.99)])
或者直接使用numpy提供的方法来求
# 根据不同的线来改变q
np.quantile(time_list, q, interpolation=“nearest”)
2.3 Accuracy 准确率
训练后的模型能够提供正确结果的能力。一般推理时,我们会评估模型在模型压缩或者优化后能够和训练时达到一样或者可接受的相似效果。模型是否正确部署,结果具有幂等性。同时根据应用场景的情况,我们可以针对自己在意的指标进行衡量(和训练时相同)。例如:一般针对图像分类而言,我们会参考top-1 or top-5的准确率。
2.4 Memory usage 内存使用情况
在众多场景下,在推理过程中很关注内存的使用情况。尤其是在多个网络模型并且内存资源有限的系统中尤为重要。另外,有时也需要在意内存的利用率情况,这对于评估资源是否浪费以及模型外工程方面的优化方向至关重要。在GPU设备上,我们可以使用下面命令来监控内存的使用情况。
nvidia-smi
watch -n 1 nvidia-smi #每个1s更新显示
2.5 Efficiency 效率
单位功率的吞吐量, 一般单位为 performance/watt。Efficiency是数据中心扩展合算分析的另一个关键因素。因为服务器、服务器机架和整个数据中心必须在固定的功率预算内运行。
3 FLOPs
是floating point operations的缩写(s表复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
4 FLOPS
是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
5 硬件相关
在大数据的时代,对于各种卡的选择我们也是需要有一点点了解的,很多优化操作都是针对不同的卡进行的。我现在用到比较多的就是 V100和T4,两者相关信息对比:

更多详见:List of Nvidia graphics processing units
6 参考文献
https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units
https://blogs.nvidia.com/blog/2016/08/22/difference-deep-learning-training-inference-ai/
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#overview
动态图和静态图
目前神经网络框架分为静态图框架和动态图框架,PyTorch和TensorFlow、Caffe等框架最大的区别就是他们拥有不同的计算图表现形式。TensorFlow1.*使用静态图(在TensorFlow2.*中使用的是动态图),这意味着我们先定义计算图,然后不断使用它,而在PyTorch中,每次都会重新构建一个新的计算图。
静态图和动态图有各自的优点。动态图比较方便DEBUG,使用者能够使用任何他们喜欢的方式进行debug,同时非常直观,而静态图是通过先定义后运行的方式,之后再次运行的时候就不再需要重新构建计算图,所以速度会比动态图更快。
import torch
from torch.autograd import Variable
x=Variable(torch.randn(1,10))
prev_h=Variable(torch.randn(1,20))
W_h=Variable(torch.randn(20,20))
W_x=Variable(torch.randn(20,10))
i2h=torch.mm(W_x,x.t())
h2h=torch.mm(W_h,prev_h.t())

比较while循环语句在TensorFlow和PyTorch中的定义。
TensorFlow
import tensorflow as tf
first_counter=tf.constant(0)
second_counter=tf.constant(10)
def cond(first_counter,second_counter,*args):
return first_counter<second_counter
def body(first_counter,second_counter):
first_counter=tf.add(first_counter,2)
second_counter=tf.add(second_counter,1)
return first_counter,second_counter
c1,c2=tf.while_loop(cond,body,[first_counter,second_counter])
with tf.Session() as sess:
counter_1_res,counter_2_res=sess.run([c1,c2])
print(counter_1_res)
print(counter_2_res)
可以看到TensorFlow需要将整个图构成静态的,每次运行的时候图都是一样的,是不能够改变的,所以不能直接使用Python的while循环语句,需要使用辅助函数tf.while_loop写成TensorFlow内部形式。
PyTorch
import torch
first_counter=torch.Tensor([0])
second_counter=torch.Tensor([10])
while(first_counter<second_counter):
first_counter+=2
second_counter+=1
print(first_counter)
print(second_counter)
tensor([20.])
tensor([20.])
可以看到PyTorch的写法和Python的写法是完全一致的,没有任何额外的学习成本。动态图的方式更加简单且直观。














 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









