






RDMA WRITE,请求端主动向响应端写入数据
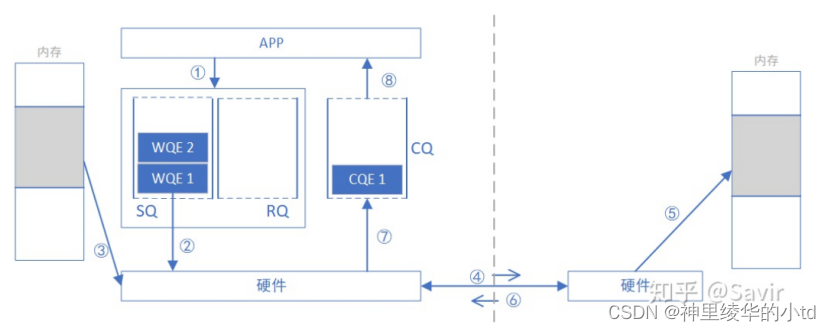
1.请求端APP下发WQE到SQ
2.请求端网卡从SQ中取出WQE,WQE提供本地数据的虚拟地址VA
3.请求端网卡根据VA,转换得到物理地址PA,组装数据包
4.请求端网卡将数据包发送给响应端网卡
5.响应端网卡将VA转换成PA放到指定位置
6.响应端网卡回复ACK
7.请求端网卡收到ACK后生成CQE放入CQ
8.APP取得完成信息
READ:主动读取远端内存数据,远端数据在网卡回复时携带
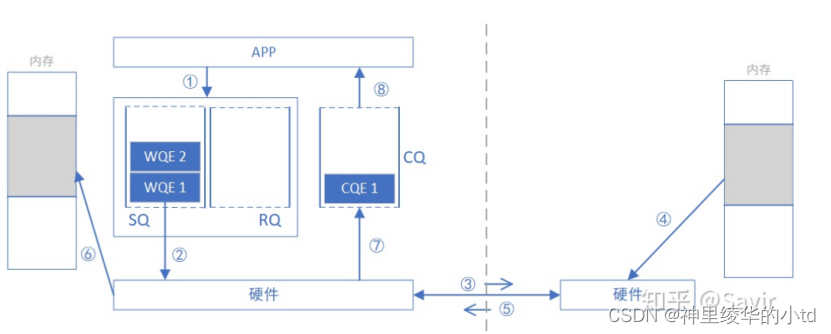
1.请求端APP下发WQE
2.网卡从SQ中取出WQE,获取相关信息
3.请求端网卡将READ请求发送给响应端网卡
4响应端网卡收到请求后将VA转换为PA,从内存中读取数据
5.响应端网卡回复请求并携带请求端的数据
6.请求端硬件收到数据后将数据放到指定内存区
7.生成CQE放入CQ
8.APP获取完成信息
在RDMA READ 和 WRITE的过程中,全程不需要CPU的参与,但是在READ或WRITE操作之前需要通过其他方式获取权限,例如socket
MR,Memory Region
RDMA软件层在内存中规划一片区域,用于存放和收发数据,这个区域将主机内存和RDMA关联,确保RDMA在进行数据传输时能够正确高效地访问内存区域,这个内存区域就是MR,注册MR 可以使用verbs提供的接口ibv_reg_mr(),在注册这一过程中,内存会创建一个VA和PA之间的映射表,当RDMA网卡需要获取PA时通过查表即可获取PA
在注册MR时会产生两把钥匙L_KEY和R_KEY,分别对应本地和远端,用于保障对内存区域的访问权
注册MR后,为了防止换页导致映射关系发生改变,MR所在的内存会被锁住,直到通信完成主动注销MR
PD,Protection Domain
IB协议中规定:每个节点都至少要有一个PD,每个QP都必须属于一个PD,每个MR也必须属于一个PD
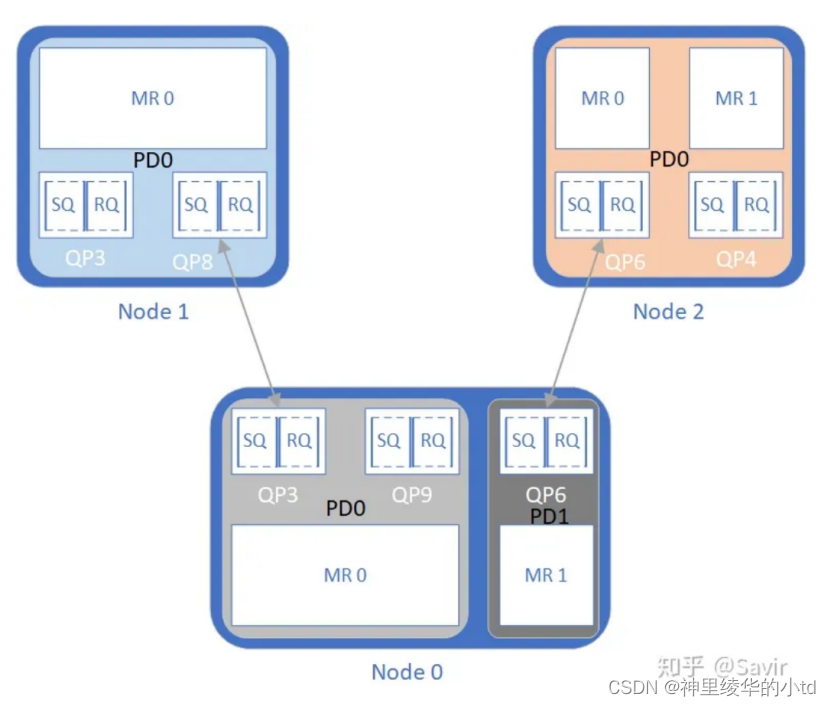
各个PD所容纳的资源彼此隔离,Node 0上两个PD之间QP和MR不能相互访问,Node1的QP不能访问Node0的MR1,
ibv_alloc_pd用于分配一个PD对象,返回PD句柄
代码部分
注册PD:调用ibv_alloc_pd函数分配一个PD对象,该函数会返回一个struct ibv_pd* 类型的指针,指向分配的 PD 对象
struct ibv_pd *ibv_alloc_pd(struct ibv_context *context);注销PD:ibv_dealloc_pd()函数接受一个struct ibv_pd* 类型的指针作为参数,并释放该 PD 对象
int ibv_dealloc_pd(struct ibv_pd *pd);注册MR:返回一个指向ibv_mr的指针
struct ibv_mr *ibv_reg_mr(struct ibv_pd *pd, void *addr,
size_t length, int access);pd:指针,指向与此内存区域相关联的保护域
addr:指针指向要注册的内存区域
length:要注册的MR的大小,单位B
access:描述访问权限
注销MR:
int ibv_dereg_mr(struct ibv_mr *mr);在rdma-example中寻找相关的实例代码
git clone https://github.com/animeshtrivedi/rdma-example
cd rdma-example/src
vi rdma_server.c在第50行有关于保护域申请的代码,传入客户端连接所在的 RDMA 设备分配一个保护域,如果失败返回相关错误信息
pd = ibv_alloc_pd(cm_client_id->verbs
/* verbs defines a verb's provider,
* i.e an RDMA device where the incoming
* client connection came */);
if (!pd) {
rdma_error("Failed to allocate a protection domain errno: %d\n",
-errno);
return -errno;
}当需要进行数据传输时需要注册MR,rdma-example只是简单的通信功能,没有使用这一接口















 1125
1125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









