






一、其他的一些概念
-
一些专业名词的解释
Cubic:CUBIC: A New TCP-Friendly High-Speed TCP Variant.
Compound:Compound TCP: A New TCP congestion control for high-speed and long distance networks.
BBR:BBR: congestion-based congestion control
https://www.cnblogs.com/haoee/p/16209818.html
Reno:TCP拥塞控制算法,包括慢启动,拥塞避免,快重传,快恢复
https://cloud.tencent.com/developer/article/2102708
BDP:bandwidth-delay product,带宽时延积,特定时间网络线路上的最大数据量,单位B或bit
ECN:Explicit Congestion Notification
TCP Vegas: New Techniques for Congestion Detection and Avoidance
FAST TCP: Motivation, Architecture, Algorithms, Performance
SRTT:Standard Smoothed RTT Estimate(标准平滑往返时延估计),根据历史往返时延计算得出的,通过对连续多个RTT进行指数加权平均,来平滑该值以减少抖动
SRTT = (1 - α) × SRTT + α × RTT,α为平滑因子
AIMD:Additive Increase Multiplicative Decrease,加性增长乘性减少
ACK-Compression:SACK,通过一个ACK确认包来代替多个ACK以减少网络中的流量
TCP pacing:控制TCP的发包速率,在每个 RTT 窗口内均匀发送数据,举个例子,Current window = 8 packets, RTT =500ms,那么1 packet every 62.5ms
https://www.zhihu.com/question/53661250
Markovian:马尔可夫过程通常指的是具有"马尔可夫性质"的随机过程。这个性质表明该随机过程在给定它的当前状态时,未来的发展只与当前状态有关,而与过去的状态无关。
-
排队论
排队论 (queuing theory),或称随机服务系统理论, 是通过对服务对象到来及服务时间的统计研究,得出这些数量指标(等待时间、排队长度、忙期长短等)的统计规律,然后根据这些规律来改进服务系统的结构或重新组织被服务对象,使得服务系统既能满足服务对象的需要,又能使机构的费用最经济或某些指标最优。
用 3 个字母组成的符号 X/Y/Z 表示一个排队系统。其中 X 表示顾客到达时间分布,Y 表示服务时间的分布,Z 表示服务机构中的服务台的个数。
排队模型的表示
X/Y/Z/A/B/C
X — 顾客相继到达的间隔时间的分布;
Y — 服务时间的分布(M — 指数分布、D — 确定时间、Ek — k 阶埃尔朗分布、G — 一般分布等);
Z — 服务台个数;
A — 系统容量限制(默认为 ∞);
B — 顾客源数目(默认为 ∞);
C — 服务规则 (默认为先到先服务 FCFS)。
排队系统的衡量指标
服务队长 L(s) — 正在接受服务的顾客数;
排队长 L(q) — 在队列中等待的顾客数;
总队长 L = L(s) + L(q) — 系统中的顾客总数;
服务时间 W(s) — 顾客在服务中消耗的时间;
等待时间 W(q) — 顾客在队列中等待的时间;
总时间 W = W(s) + W(q) — 顾客在系统中的总逗留时间;
忙期 — 服务机构两次空闲的时间间隔;
服务强度 ρ;
稳态 — 系统运行充分长时间后,初始状态的影响基本消失,系统状态不再随时间变化。
二、Copa论文的相关内容 NSDI-18
-
摘要
Copa是一种基于延迟的端到端的拥塞控制算法,采用三个idea组合实现:
-
通过优化一个效用函数(与吞吐量和延迟相关),求得其最优速率为$$1/(\delta d_q)$$,作为target rate
-
通过窗口更新规则(window update rule)调整拥塞窗口往target rate的方向变化
这两个idea构成了一个delay-based的CC算法,能够实现高利用率、低延时的目标。但是delay-based的CC算法有一个通病,就是与loss-based的CC算法竞争时,争抢不到带宽。
-
通过delay的变化,探测是否存在buffer-fillers算法,以加性增/乘性减的方式调整 $$\delta$$参数。
-
背景
CC算法是数据传输协议的核心,由于需求增加,其性能需要改进。CC算法分为几个方向:
-
从Reno开始,扩展到Cubic、Compound算法,以丢包、ECN作为拥塞信号,缺点:这些算法都倾向于填满buffer,即以delay的代价来实现高吞吐量
-
基于delay的CC算法,例如Vegas、FAST。这些算法可以带来低延迟;缺点:由于ACK压缩(ACK compression)、网络抖动(jitter),导致高估延迟,而这些算法又以delay作为拥塞信号,因此链路带宽无法完全利用;另一个缺点:无法与loss-based的CC算法竞争。
-
研究多关注特定环境和工作负载下的CC算法,使CC算法变得特异性,而不是普遍性。这些算法在特定场景的效果优于先前具有普遍性的算法。
-
Copa算法
-
目标函数
对于每一个sender,Copa定义了一个目标函数使其最大化,max U =

λ是平均吞吐量,d是包间延迟,δ是一个参数,表示愿意牺牲低时延到什么程度以保障高带宽,其值越高,对d的影响越大,表示不愿意牺牲延迟
-
目标速率
目标速率计算方式为

dq为平均每包排队时延(以秒为单位)
dq =RTTstanding−RTTmin
其中RTTstanding是最近一个时间窗口 $$\tau$$内观测到的最小的RTT,取最小的RTT是为了保障面对 ACK compresion 和 network jitter 时的鲁棒性。对于RTTstanding的测量,虽然最近一个时间窗口 $$\tau$$内观测到的最小的RTT,但是实际上是RTT+$$\ta$$到RTT之间的一个RTT最小值,因为其测量需要一个RTT延迟
-
这些问题会增加 RTT ,而发送端误以为数据传输路径上存在排队导致更长的 RTT;
-
ACK compresion 可由反向路径上的排队和无线链路引起。
$$\tau=srtt/2$$,srtt是是标准平滑RTT估计值,RTTmin是长时间观测到的最小RTT,本文使用10秒和自流开始的时间为这段时间
-
速度控制机制
默认模式:动态调整拥塞窗口以调节速度,$$\delta=0.5$$
流启动时,使用慢启动机制,每过一个RTT,cwnd倍增,直到$$\lambda >\lambda_t$$
每个ACK到达时执行的步骤
-
更新dq,srtt
-
更新目标速率$$\lambda_t$$
-
更新cwnd,当前速率估计公式为 $$\lambda_c =cwnd/RTTstanding$$,如果$$\lambda_c <= \lambda_t$$,cwnd = cwnd + v/(δ · cwnd),如果 $$\lambda_c > \lambda_t$$,cwnd = cwnd - v/(δ · cwnd),并采用pacing限制发送速率为2·cwnd/RTTstanding避免packet bursts,这个pacing导致了一个现象:包的到达呈现泊松分布
-
对于速度参数v(其值初始化为1),发送方将当前cwnd与在当前窗口的开始处的cwnd值进行比较,如果当前cwnd较大,设置方向为up;如果较小,设置方向为down。如果连续两次方向相同,v=2*v,否则,v重置为1,但是如果v=1且连续两次方向相同时,还需要满足一个额外的条件:同一方向保持时间>=3*RTT
个人理解:v的作用是,加速cwnd的变化速度,当连续两次cwnd增加或减少时,说明网络中的拥塞情况发生了较大的变化,那么使用v这一参数来加速cwnd的变化速度来快速适应当前的网络情况
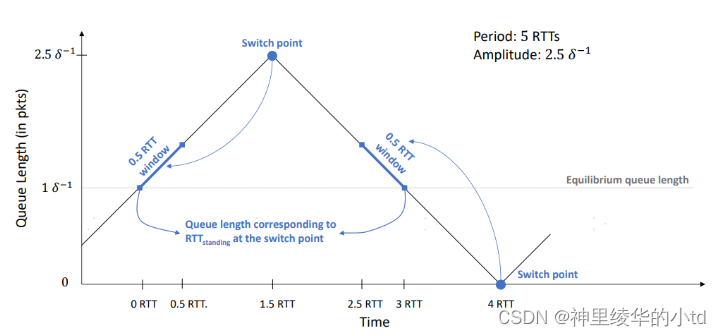
此图描述copa处于稳态时,转变点A、B:当由 ACK 携带的RTT信息计算出的RTTstanding估计得到的队列长度越过$$\delta^{-1}$$的阈值时,Copa 速率变化方向改变
关于此图,个人觉得纵坐标为inflight+queue的数据量,个人理解:
-
平衡时队列长度为$$\delta^{-1}$$个数据包:$$\lambda_t=\lambda_c,1/(\delta*d_q)=cwnd/RTTstanding,d_q=RTTstanding-RTTmin$$,于是$$cwnd*\frac{RTTstanding-RTTmin}{RTTstanding}=\frac{1}{\delta$$,数据分为在链路中(inflight)的数据和在队列(queue)中的数据
-
速度参数$$v=$$保持不变:copa算法在设计时考虑到了稳态这一状态,在速度参数v的设计时就希望在稳态时v能够保持不变,因此加了限定条件(如果v=1且连续两次方向相同时,还需要满足一个额外的条件:同一方向保持时间>=3*RTT)
-
每个RTT时间的cwnd的变化为$$1/\delt$$:cwnd的变化公式为$$cwnd=cwnd±v/(\delta*cwnd$$,$$v=1$$,每个ACK都会进行一次操作,使用SACK,公式加减cwnd次,因此变化为$$1/\delta$$(pkts/RTT)
-
图的斜率为$$\delta/RTT$$:此图为sender根据RTTstanding估计的queue length,其变化应与cwnd的变化保持一致
在1.5RTT时,发送端评估当前速率,此时所得的RTTstanding为0~0.5RTT内的RTT最小值,此时对应的速率大于目标速率,因此减少cwnd,降低发送速率,4RTT时同理
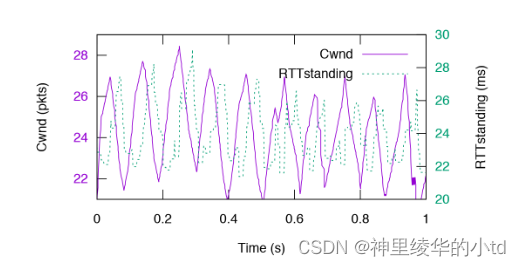
单copa流实验结果:
-
单Copa流在一条12Mbit/s模拟链路上运行,周期约为5RTT,振幅约为5pkt
-
由于cwnd计算仅根据RTTstanding和阈值的比较, Copa 对定时估计RTT的机制带来的不规律测量有免疫
多流情况
N 个发送端(不同的δ)共享同一个瓶颈时,它们会因为一个共同的时延信号同步。因此当它们有相同的传播时延时,它们的目标速率会同时越过目标速率,而与$$\delt$$无关。
由于所有发送端一同增减拥塞窗口,可以认为它们的行为可以看作一个发送端,$$\delta = \hat{\delta} = (\sum_{i=1}^n 1/\delta_i)^{-1}$$
竞争模式:动态调整$$\delta$$以与缓冲挤占型算法竞争,$$\delta<=0.5$$
从目标函数U来看,$$\delt$$越小,表示copa愿意牺牲delay与其他算法竞争以保证更高的吞吐量
利用Copa 的一个特性:当多条有相近 RTT 的 Copa 流共享一个瓶颈(bottleneck)时,队列每5个RTT会清空一次,而与buffer-filling scheme共存时,队列不会依规律清空
侦测方案:检测 5RTT 内的队列是否清空
判断标准:(第五个RTT)是否存在排队时延低于(前四个RTT)速率振荡值的10%,公式为$$d_q<0.1*(RTTmax-RTTmin$$,RTTmax是在过去的四个RTT中的最大值
采取方案:如果上述不等式成立,继续保持默认模式,否则切换竞争模式
$$\delt$$调整方式:根据数据包的成功或丢失对$$\delta^{-1}$$进行AIMD
-
copa的动态
振荡存在条件
-
目标速率必须高于或低于发送端至少1.5RTT
-
v=1
模拟实验的验证
哑铃型拓扑,100Mbit/s 瓶颈带宽,20ms 传播时延, 5BDP 缓存,100条流,ns-2。
大多数实验的大多数时候v=1,只在流离平衡速率过远时才变化,即使实验中加入网络扰动。
在某些时候,时延的同步性会减弱,发送端会错误切换到竞争模式:
-
传播时延远小于排队时延
-
不同发送端传播时延差别较大
为何渐进变化达到平衡?
如果采取直接将当前速率设为目标速率的方案,实验证明系统仅在几个条件下收敛,否则将产生摇摆导致对网络的严重不充分利用。
为何要振荡而非相对平静?
收敛到一个常数速率和非零排队时延的状态对基于实验的拥塞控制器来说并非理想状态。如果队列从不清空,则后发流将高估最低RTT,进而高估排队时延,并最终导致显著不公平性。因此需要渐进达到平衡,并在平衡附近轻微振荡以经常清空队列。
为何cwnd的变化采用 AIAD 机制而非 AIMD?
-
Copa 的目标函数希望保持较小队列。
-
稍高于平衡时 MD 会导致网络严重不充分利用。
-
稍低于平衡时 MI 会导致巨大的队列长度。
-
有速度参数v加持的 AIAD 机制也快速收敛。
-
关于copa的理论说明
此部分是理论说明,主要涉及两个方面,排队论和纳什均衡
目标速率与纳什均衡
$$U_i=log\lambda_i-\delta_ilogd_s$$是发送端结合吞吐量和时延的目标函数,其中$$d_s=d_q+1/\mu=d_{total}-d_{prop}$$是交换时延,忽略节点处理时延,该时延几乎等于排队时延,每个发送端都试图将目标函数最大化,在该模型下系统将达到纳什平衡,此时没一个发送端能够通过单方面改变速率增加目标函数。
为什么假设马尔可夫包到达模型?
论文作者假设马尔可夫分布式到达&服务模型来研究速率更新规则。选择确定性服务模型也能得到相似结果,只是系数乘上2而偏移。大体上,发送端发送速率不是在一个确定的平均速率上,而是在一种马尔可夫的形式下。但是实际上,并非如此:
-
发送端的传输总会有自然的抖动;
-
只有少量发送端的情况下,故意的抖动会增加不必要的时延;
-
Copa 的行为对这个假设不敏感。
其他模型说明
-
采用该模型并不是因为其精确,而是因为它是现实情况的简单且易处理的估计。
-
论文作者的目的是推导出一个原理性强的目标速率,并将它作为整个模型的稳定基础以引导速率更新规则。
说明了MM1和MD1模型的情况
-
实验结果
-
copa的动态调整能力强
吞吐量分配接近ideal allocation
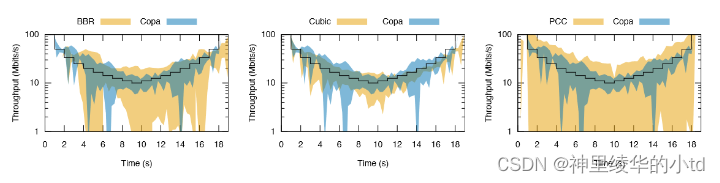
黑线表示理想分配,设置了100Mb/s的链路,20ms RTT,1 BDP缓存,前十秒每秒有一个流到达,后十秒每秒有一个流离开。流在每个时隙获得的带宽的平均值±标准差如图所示。
公平指数
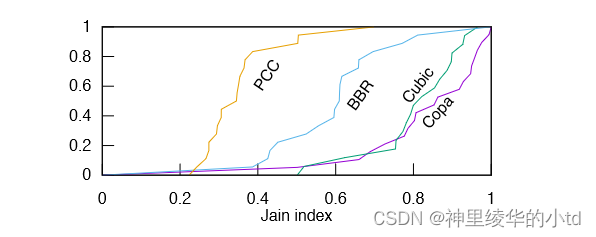
纵坐标为CDF(累积分布函数),Jain index接近于1的意味着每个成员都拥有相同的贡献程度,当Jain index接近于0时,说明群体中的参与度非常不平等。这张图表示,当网络环境发生变化时不同CC算法对网络带宽分配的公平性。
本实验为了说明copa在变化的网络环境中仍然能保持稳定。
-
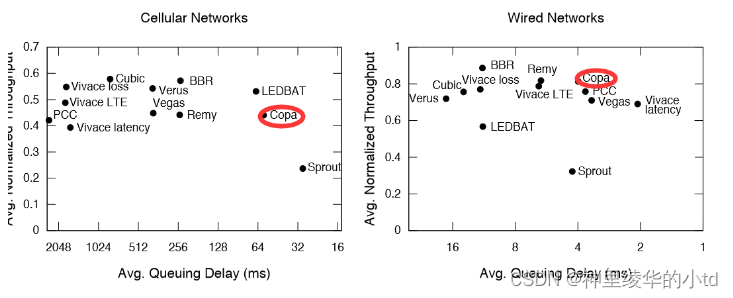
Real-World Evaluation:在pantheon path性能测试
进行了多次实验,将吞吐量取平均值并进行0-1标准化,延迟为使用NTP-同步时钟所得的单向延迟
-
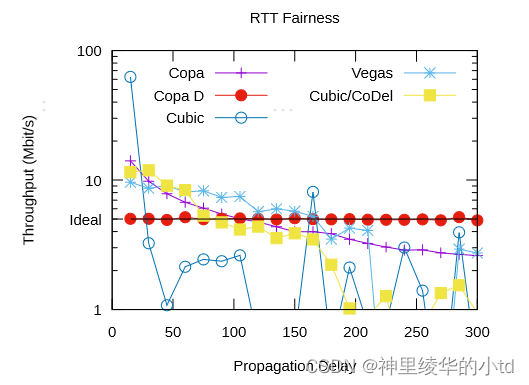
RTT公平性:不同的RTT享有相等的吞吐量
不同的流获得的吞吐量,每一个点代表一个流,理想状态下(关闭模式切换),每个流获取相同的吞吐量,在此实验中,copa的每5个RTT队列几乎为空的性质被破坏,所以copa处于竞争模式,继承了AIMD的RTT不友好性,由于AIMD在1 / δ上,而delay-based算法鲁棒地竞争或放弃带宽,使分配与1 / δ(数据包数量)成正比,Copa的RTT不友好性比其他方案要温和得多。
Cubic AIMD 直接对cwnd进行,copa AIMD对1 / δ,cwnd = cwnd±v / (δ·cwnd)
-
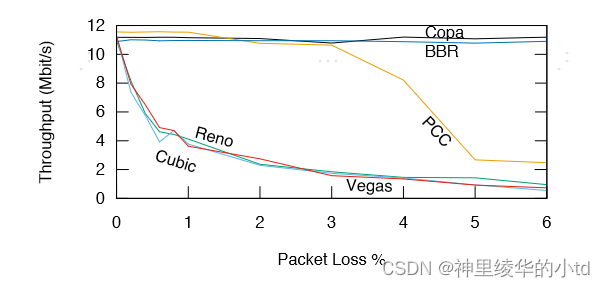
对丢包的鲁棒性
copa的基于延迟的,不使用丢包作为拥塞信号,在丢包的情况发生后,传统的TCP竞争算法会退避,copa转为默认模式,仍能保持较高的吞吐量
-
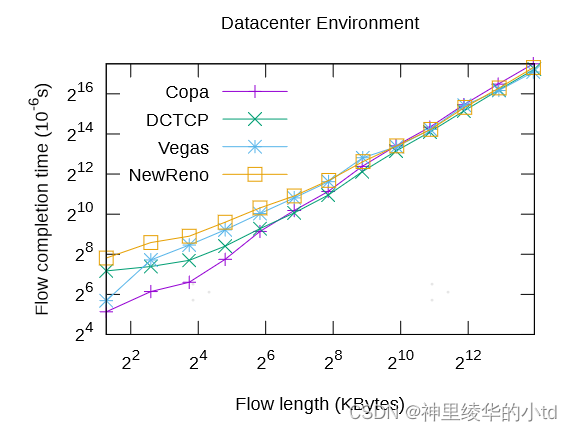
模拟数据中心网络环境
调参:忽略传播延迟,取消模式切换$$\delta=0.5$$,RTTstanding=最新的RTT,对于v,只有当> 2 / 3的ACK引起该方向的运动时,才认为拥塞窗口在给定方向上变化
实验结果:在多短流的实验条件下,与TCP算法相比性能较优
-
Satellite link
结果:实现了低延迟、高吞吐量
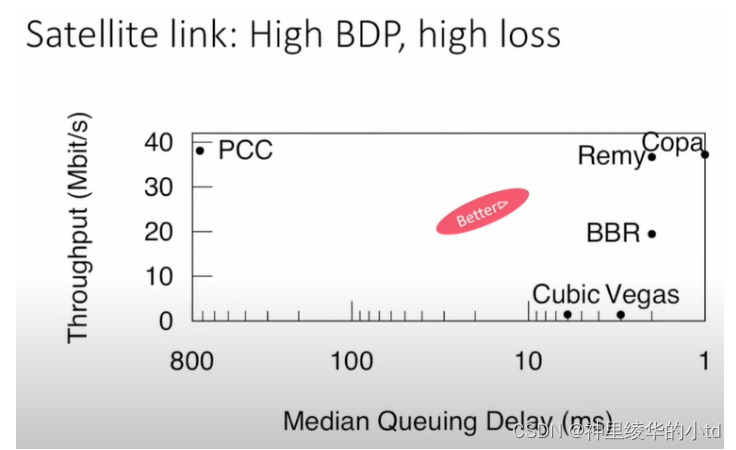
-
与cubic共存时:保持高带宽且不损害cubic的带宽
cubic和其他方案共存时的带宽,和vegas reno共存时,cubic吞吐量变高,与copa共存保持不变,而copa还能保持高带宽,与PCC BBR共存时,cubic带宽受到损害
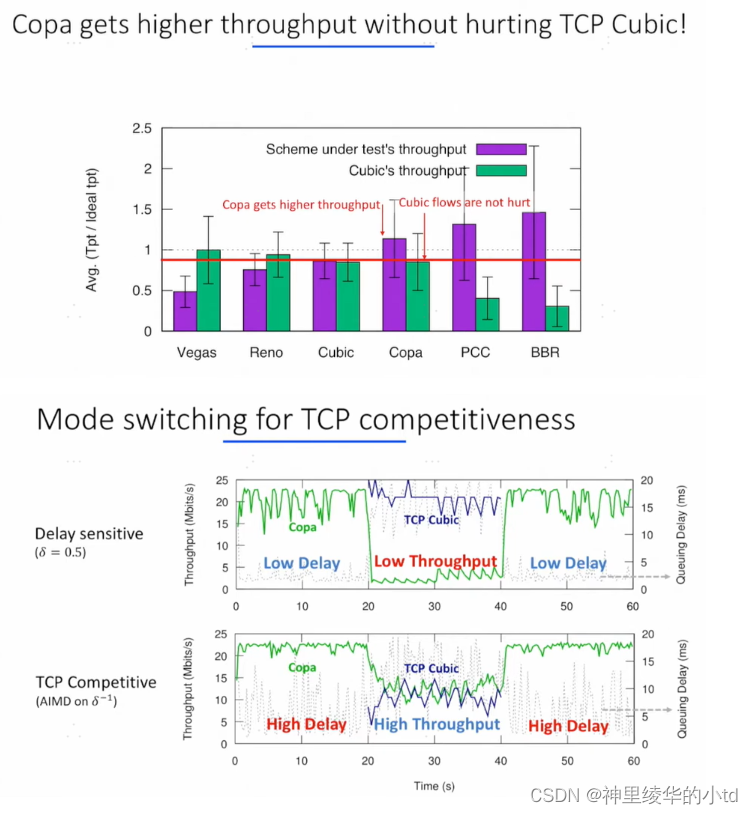
三、总结
-
效用函数:只从算法本身来看,效用函数U只是起了一个引导的作用,说明了每一个发送端的目标是尽量增大吞吐量和降低延迟,对于多个发送端共存时的情况,该效用函数的作用是使整体达到纳什均衡。
-
对于每一个发送端,基于RTT计算当前速率和目标速率,如果当前速率大于或小于目标速率,分别进行不同的调整
-
copa有默认模式和竞争模式,如果检测到有loss-based型算法则切换竞争模式,否则使用默认模式
-
本论文的理论证明部分涉及了纳什均衡和排队论,纳什均衡用于表示在一个系统中达到了有利于每一个发送端的效用,任何一个发送端的单方面改变都会降低该发送端的效用函数值;排队论用于说明该论文模型的合理性,分为M/M/1和M/D/1两种情况进行说明,本次论文的阅读并没有深入研究这两方面的知识
四、其他链接
原始仓库:https://github.com/venkatarun95/genericCC
复现仓库:https://github.com/nadinelyab/Copa_Reproduction
会议视频:https://www.youtube.com/watch?v=FDAzVFmuVUY
copaMIT官网:https://web.mit.edu/copa/#impl
笔记1:https://blog.csdn.net/weixin_45662974/article/details/124070835
笔记2:https://blog.csdn.net/mist_csdn/article/details/128424581

















 777
777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









