






其他的一些概念
50th 95th percentiles:https://blog.csdn.net/m0_37668842/article/details/105550199
概念:95th percentile百分点指的是所给数集中超过其95%的数。95th百分点是统计时所采用的最高值,超过的5%的数据将被舍弃。这样可以将瞬间的毛刺(尖峰)去掉,使统计平均更具真实意义。
举例:例如数据为60,45,43,21,56,89,76,32,22,10,12,14,23,35,45,43,23,23,43,23 (20 个点),将该序列降序排列,其最大值为89。由于20个点的5%为1,所以舍弃1个最大值89,剩下的最大值76就是95th百分点
CBR:constant bitrate(CBR) flow,固定码率流,本文为非弹性流
ACK-clock:ACK-clock用于实现流量控制,发送方在发送数据包后启动一个时钟,等待接收方发送ACK,如果在时钟到期前没有收到ACK,发送方将减慢或停止发送数据,从而避免在网络拥塞的情况下造成数据包的丢失。
论文部分
网络模型
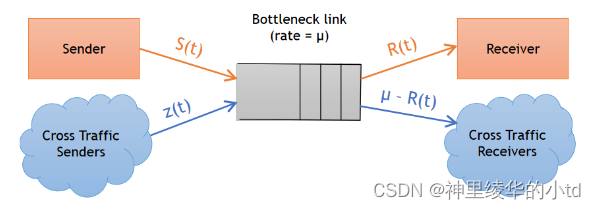
其中S(t),R(t),z(t),$$\m$$分别表示随时间变化的发送端速率、接收端速率、交叉流速率和共享瓶颈链路的恒定速率。
假设初始条件:瓶颈链路是繁忙的(即它的队列不是空的),并且路由器对所有流量的处理方式相同,那么存在等式$$\frac{S(t)}{S(t)+z(t)}=\frac{R(t)}{\mu}$$,据此估计出z(t)的值:$$\hat{z}(t)=\mu\frac{S(t)}{R(t)}-S(t)$$
通过考虑n个包来估计S(t)和R(t):
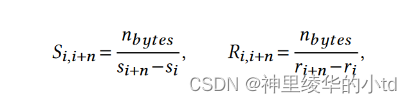
$$n_{bytes}$$:n个包中的字节数
$$s_$$:发送端发送第k个包的时间
$$r_$$:发送端收到第k个包ACK的时间
速率的单位是B/s
如何检测弹性流
strawman方法
strawman方法(即检测RTT,实验说明此方法无效):通过估计交叉流量对排队延迟的贡献来检测弹性流。例如,发送方可以估计自己对排队延迟的贡献(即"自己造成的"延迟"),如果总延迟显著高于自己造成的延迟,则认为交叉流量是弹性的。
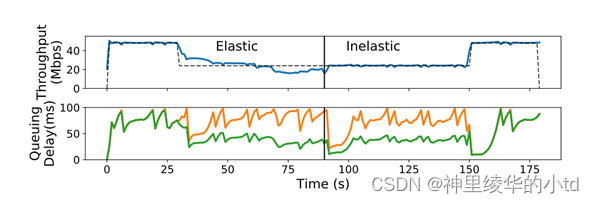
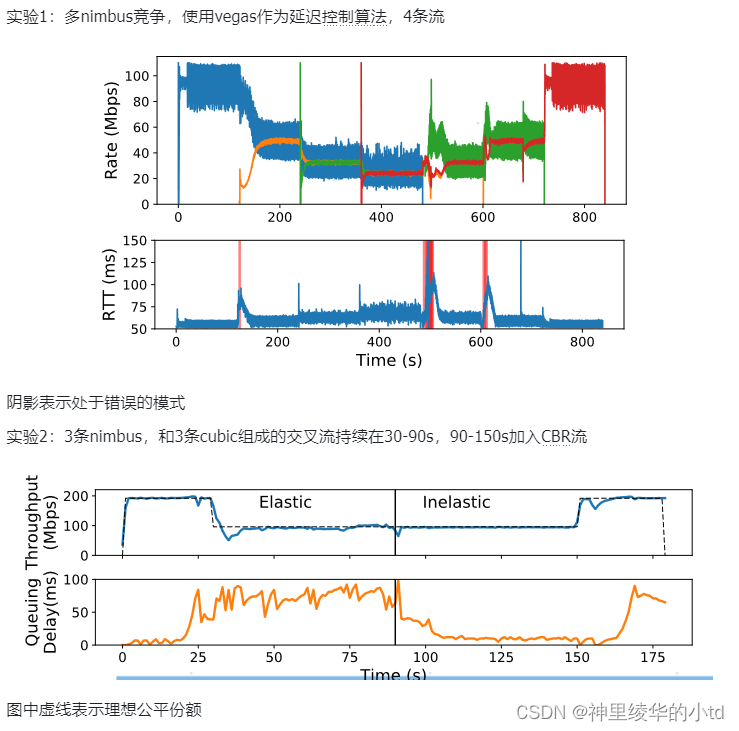
总排队延迟(橙色)和自触发延迟(绿色,cubic流),实验为Cubic流包含弹性区域( 30 ~ 90 s)和非弹性区域( 90 ~ 150 s)中的CBR交叉流。从图中来看,自触发延迟在弹性区域和非弹性区域看起来是相同的,原因在于,一个流在队列占用中的份额与其吞吐量成正比,这在两个阶段大致相同。由于Cubic流获得了瓶颈链路的50 %,其自身造成的时延大致为总排队时延的一半。这个例子表明,瞬时测量值不能用来区分弹性和非弹性的交叉流。
理论分析
从弹性流的特点入手:弹性流以可预测的方式对瓶颈处的波动做出反应。对于一个长流,cubic或newReno流,都是ACK-clocked流,ACK的延迟会导致传输过程中下一个包的延迟,包到达接收端的变化会导致在发送端有着相似的变化,而非弹性流就没有这种变化
方法:通过脉冲发送数据包,让瓶颈链路上交叉流的包间间隔变化。给定发送端的发送速率S(t),发送速率在高于和低于S(t)之间交替发送,但是确保平均速率仍为S(t)。
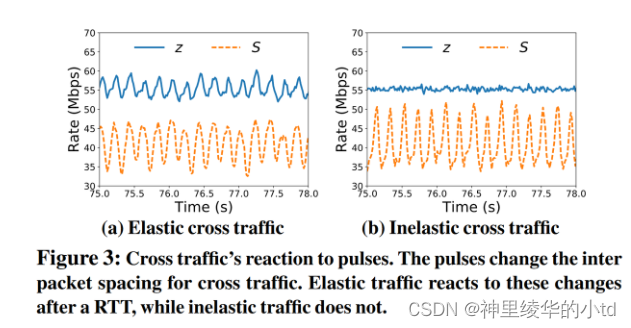
上图对比了发送端以正弦脉冲,5Hz频率传输数据包时,cubic弹性流和CBR非弹性流的变化,路径的最小RTT为50ms,一次RTT后弹性流的发送速率与发送端的脉冲成反相关,非弹性流的发送速率不受影响。
实际检测
使用上述理论思想,需要解决的三个问题:
-
发送端发送速率的脉冲必须能够引起z的变化,且这个变化是可测量的,同时还要保证以脉冲发送数据包不会阻塞瓶颈链路,概括为如何控制脉冲的发送和频率
-
由于交叉流的自然变化,z中存在噪声,导致在预测的和测量的z之间难以进行鲁棒地比较
-
由于发送端不知道交叉流的RTT,因此不知道何时在交叉流速率中寻找预测响应。
Nimbus:
发送方使用已知频率$$f_$$的正弦脉冲调制数据包传输,振幅等于四分之一瓶颈链路带宽。这些脉冲在不引起拥塞的情况下会引起链路上包间时间的显著变化,因为在脉冲的一部分中创建的队列在随后的部分中被耗尽,并且脉冲的周期很短(例如5 Hz),使用短流可以确保在一个脉冲中发送的数据的total burst是瓶颈队列大小的一小部分。
使用快速傅里叶变换FFT来判断cross-traffic是否和发送速率以相同的频率发生变化。在一个短时间间隔(5s)上对交叉流速率的估计值$$\hat{z}(t$$的时间序列进行快速傅里叶变换,以观察频率,如图所示,只有弹性流在$$f_p$$附近有波峰存在。
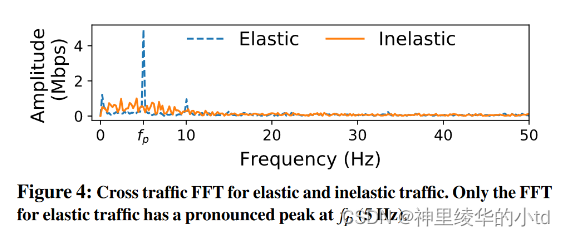
峰值的大小取决于交叉流弹性的大小,交叉流越有弹性,$$f_q$$处的峰值越尖锐。因此将峰值与预先设定的阈值进行比较并不合适,应将其与附近频率的大小进行比较。本篇文章采用了一种更为鲁棒的弹性指示器:比较$$f_$$处的波峰大小和$$(f_p,2f_p$$之间的最大波峰的大小,采用其比值作为弹性指标,定义弹性尺度$$\et$$
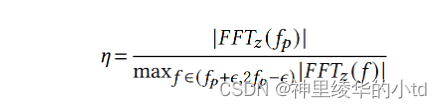
$$\epsilon=0.5,f_p=5Hz$$,如果$$\eta>n_{thresh}$$,则认为该交叉流是弹性的,否则为非弹性的。
$$n_{thresh$$值的选择:交叉流中可能同时包含弹性流和非弹性流,弹性流越多,其$$\et$$值越高,因此阈值设得高,弹性交叉流能够正确分类,但是会损害非弹性流的吞吐量,本文取阈值为2
非对称正弦脉冲
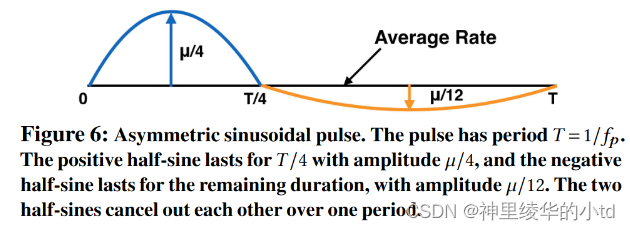
本文采用了一种不对称正弦脉冲的方法,脉冲的前1/4,发送方加上µ/4的半正弦到S(t),在剩下的3/4周期,减去半正弦与三分之一的振幅。理由:在发送方能产生引起交叉流速率变化的脉冲的前提下,减少链路阻塞的可能性。https://zhuanlan.zhihu.com/p/592023074
参数选择:
脉冲周期T的选择:有两个影响因素,S和R的测量间隔(计算$$\hat{z$$的间隔),和能够发送的超过了平均速率而不会造成拥塞数据量。如果较小,会导致对z没有影响,如果较大会导致拥塞,本文设置T为观测到的较大的RTT值,例如200ms
FFT相关参数:FFT duration=5s,$$\epsilon=0.5H$$
拥塞控制系统NimbusCC
NimbusCC有两种模式,TCP竞争模式和延迟控制模式,TCP竞争模式使用TCP竞争拥塞控制机制,支持cubic,newReno,延迟控制模式使用延迟控制算法,支持copa的默认模式和Vegas。NimbusCC转换开关使用弹性检测器Nimbus
NimbucCC由当时运行的CC算法来决定传输速率,它用不对称的正弦脉冲调制速率,比较弹性尺度与阈值的大小来决定模式
本文还实现了一个简单的基于延迟控制的算法BasicDelay,每收到一个ACK,BasicDelay设置当前速率为
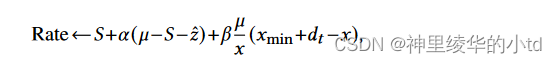
其中,S,$$\hat{z$$为发送速率和评估的交叉流速率,x为当前RTT,$$x_{min$$为观察到的最小RTT,$$\alpha,\bet$$为小于1的常数,$$d_$$为目标队列延迟,$$\mu-S-\hat{z$$表示发送方估计的空闲容量,通过增加系数使该算法接近理想速率,第二项是为了维持特定的队列延迟
Pulser-watcher extension
在多nimbus流共享同一瓶颈时,初始使用TCP竞争模式,它们都将在该频率的FFT中检测到一个峰值,并停留在TCP竞争模式,但是这样不会维持低延迟。
思路:让其中一个NimbusCC流承担pulser的角色,而其他NimbusCC流则是watcher。pulser在不同的模式中使用两种频率,(这个频率值是设定好的,本实验中竞争模式5Hz,基于延迟模式6Hz)。watcher根据接收速率推断pulser是否在这两种频率下,然后选择更大的峰值来匹配pulser的模式
pulser和watcher的选择:一个发送端决定自己作为pulser的概率为
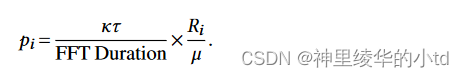
每个流周期性地进行决策,例如每$$\tau=10m$$,$$\kapp$$是一个常数,这个规则确保了成为pulser的期望数最多为$$\kapp$$,本文实验取值为1
仿真可视化
Link emulator:Mahimahi,瓶颈链路:96Mb/s,最小RTT50ms, 2BDP buffering,对比了不同方案的表现
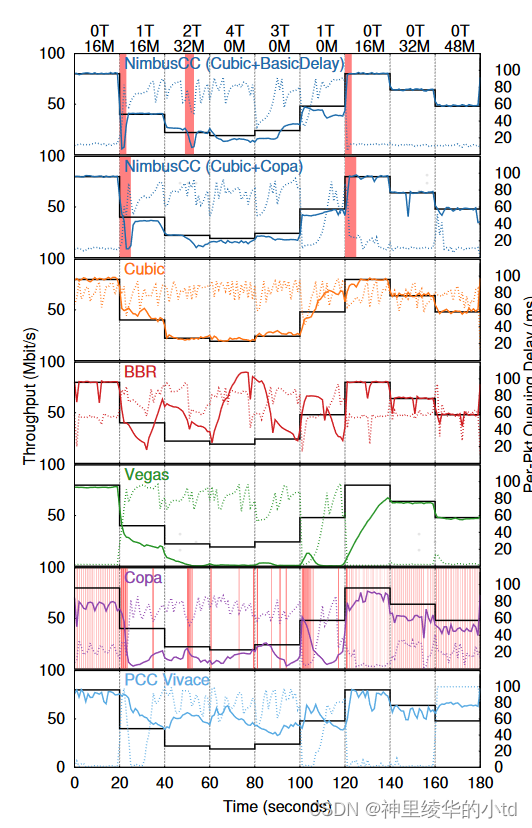
黑色实现表示在给定交叉流情况下,该协议应达到的正确公平的吞吐量,彩色实现表示实际的吞吐量,虚线表示队列延迟,在0-20s和120s之后,只有对应算法的发送端发送数据,20-120s之间有使用iperf加入的cubic弹性流,图上端T表示加入了多少个长时间运行的cubic流,x M表示对应x Mb/s的非弹性交叉流,红色阴影表示nimbus和Copa在错误的模式下。
评估
主要从5个方面评估NimbusCC:性能表现、鲁棒性、特定场景下的性能表现、pulser-watcher扩展的有效性、真实因特网路径中的性能表现
性能表现
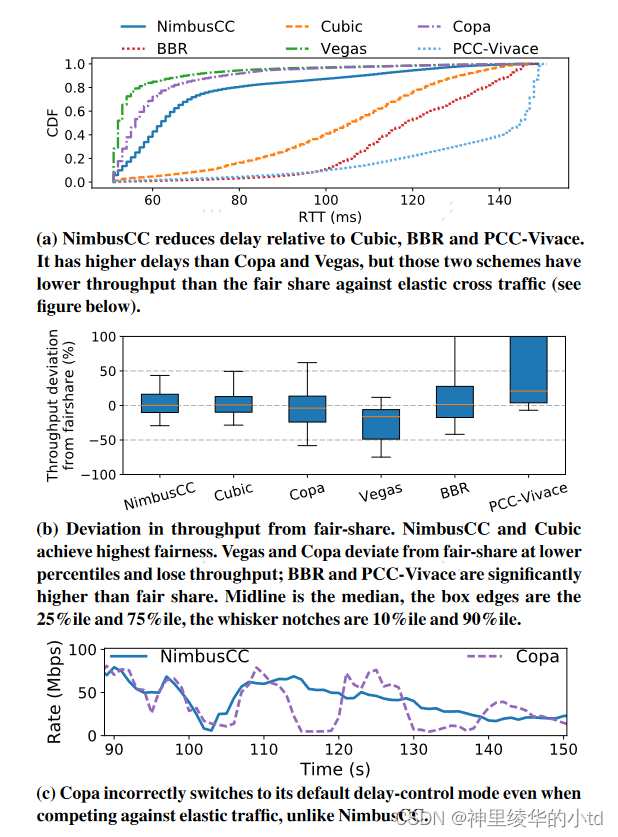
交叉流来源:CAIDA,根据此数据生成cubic交叉流,流到达时间服从泊松分布,以平均负载的50%(48Mb/s)填充链路,实验时长360s,包含10万条交叉流,本实验nimbus为cubic+basicdelay
a图:RTT比cubic、BBR、PCC更低
b图:吞吐量公平偏差,条状越小表示偏差越小,越接近0表示平均值越公平,nimbuc和cubic最公平
c图:copa算法在与弹性流量竞争时会错误地切换到default模式
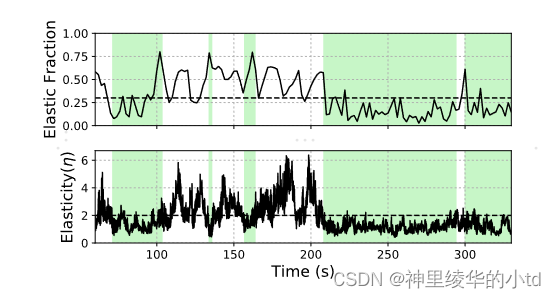
$$\eta=$$检测较为准确:图中绿色阴影部分表示非弹性周期,可以看到其$$\et$$的值基本都大于2
鲁棒性
使用三种不同成分的交叉流
-
泊松分布到达的非弹性流
-
全弹性流(使用newReno)
-
弹性和非弹性流等量混合
实验持续120s
实验1:将交叉流的RTT从10-200ms变化,对于纯非弹性和纯弹性流,nimbus发送端的识别准确率均超过98%,而对于混合流,准确率均超过85%。
实验2:每一个交叉流包含5个流,其对应的RTT分别为20,40,60,80,100ms,对于纯弹性和非弹性流,Nimbus识别准确率为98 %,而对于混合流,所有情况下的平均准确率都大于90 %。
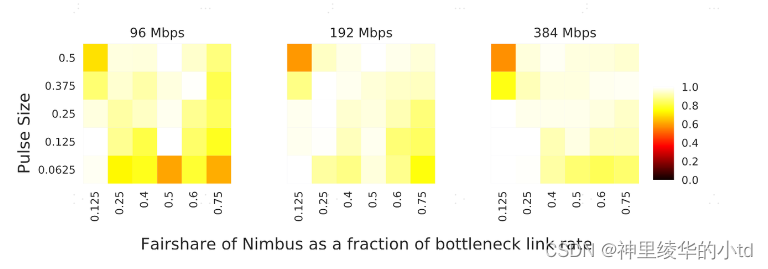
实验3:脉冲大小从1/16到1/2变化,瓶颈链路速率的公平份额从12.5 % - 75 % 变化,瓶颈链路设置为96,192,384Mb/s,图展示了不同情况下的弹性流识别准确率
与copa的对比:
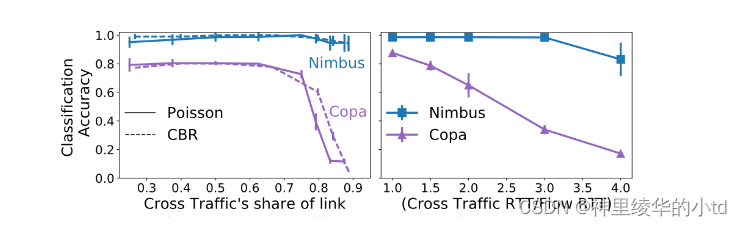
左图:在交叉流占据大部分链路时,copa识别准确率大幅下降
右图:与newReno竞争,将newReno的RTT和nimbus/copa的RTT比值从1增加到4,copa的识别准确率大幅度下降
特定场景下的性能表现
使用两种不同的流进行实验:
-
泊松分布的非弹性流量
-
全弹性流量
实验1:向nimbus提供一个错误的链路速率$$\m$$估计,对真实链路速率进行-50%到+50%进行实验,左图显示吞吐量基本不会改变,右图显示当错误较大时,所有的流都被分类为弹性流,工作在TCP竞争模式
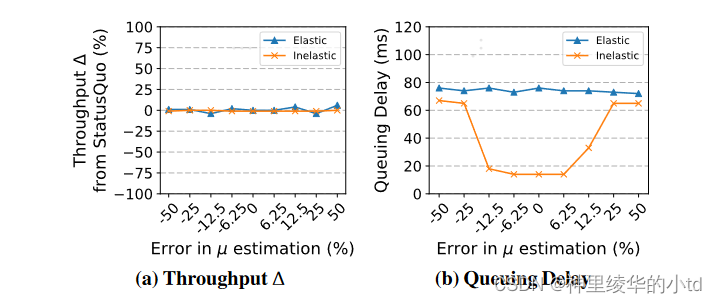
实验2:瓶颈链路$$\mu$$在±20%范围内随机变化,误差较大时,交叉流量估计器失效,nimbusCC运行在TCP竞争模式下,不会损失吞吐量

实验3:具有帧聚合功能的链路性能
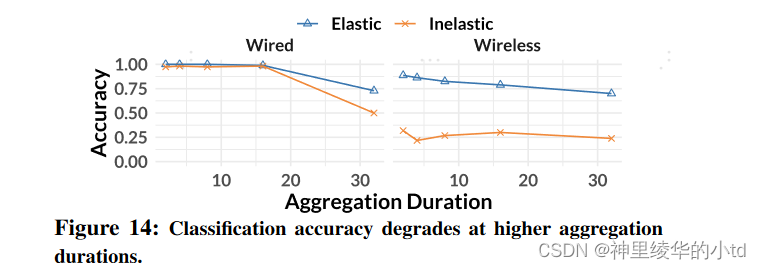
聚合时间越长,性能下降,吞吐量下降
多nimbus流
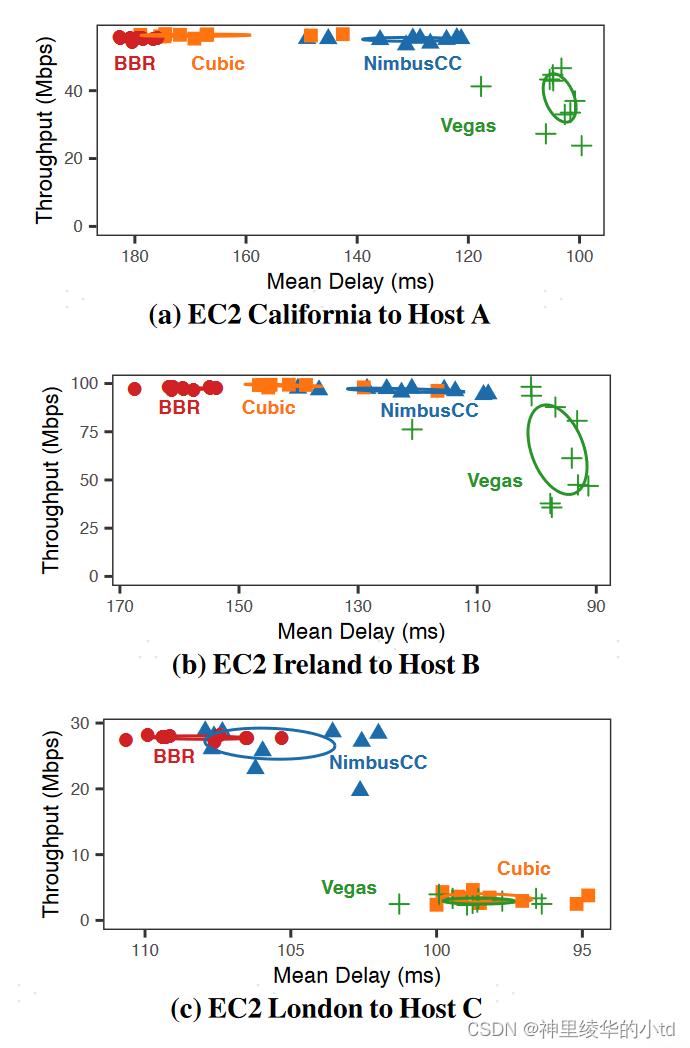
因特网路径中的表现
5个senders,位于加利福尼亚、伦敦、法兰克福、爱尔兰、巴黎,接入链路10Gb/s
5个receivers,为居民用户,通过1Gb/s接入因特网
25paths
下图是三个例子nimbus获得较高的吞吐量和较低的延迟,vegas拥有最低的延迟但是吞吐量维持在较低水平
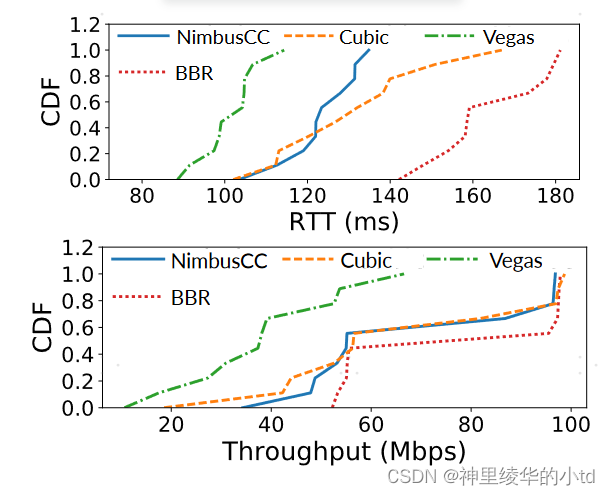
下图总结了几种算法的RTT和吞吐量,NimbusCC降低了RTT (约50ms ),且吞吐量与其他算法相当
总结
一个新的定义:弹性,定义弹性尺度公式
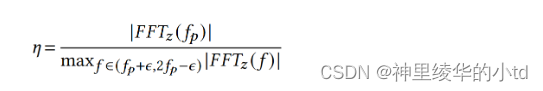
检测交叉流是否为弹性的方法叫Nimbus
Nimbus方法:将发送速率调制为非对称正弦脉冲,诱发交叉流发生变化,通过变化的幅度代入弹性公式,来判定是否为弹性流
NimbusCC:以Nimbus作为模式转换器的拥塞控制算法,分为两个模式:TCP竞争模式和延迟控制模式,具体模式中可以使用已存在的各种算法。当Nimbus检测到弹性流时使用TCP竞争模式,否则使用延迟控制模式。
本文定义了交叉流的属性,弹性,在此发现的基础上建立了相关的系统。其设计通过调整发送速率,只需在端点处修改,而无需对路由器修改,但是所有实验均以仿真的形式进行。















 759
759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









