







BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
文本理解:预训练语言模型+下游任务fine-tune
文本生成:预训练阶段和下游任务存在差异
主要贡献
BART提出了一个结合双向和自回归的预训练模型。BART模型首先使用任意噪声来破坏原文本,然后学习模型重构原文本。这样使得,BART不仅很好的处理文本生成任务,同时理解任务上的表现也不错。
BART的预训练思路
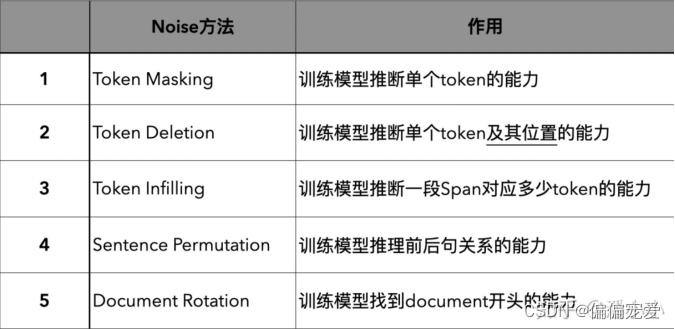
1)通过随机噪声函数(能够制造破坏文档结构的任何方法)来破坏文章结构;
2)逼迫模型能够学会将结构已经被破坏了的文章进行重构,使文章变回原来的样子
模型架构:BERT+GPT
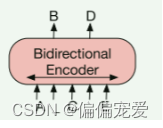
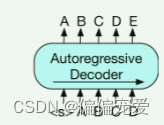
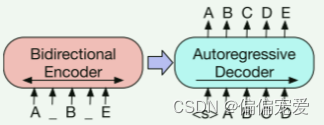
Pre-training BART
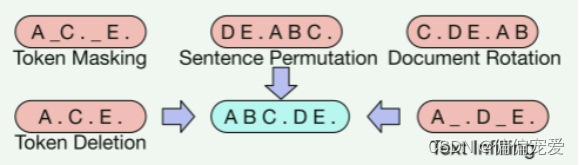
几种noise:意图是破坏掉这些有关序列结构的信息
Fine-tuning BART
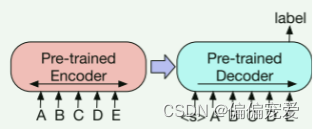
1)Sequence Classification Tasks
将该序列同时输入给encoder端和decoder端,然后取decoder最后一个token对应的final hidden state作为label,输入给一个线性多分类器。
2)Token Classification Tasks
将该序列同时输入给encoder端和decoder端,使用decoder的final hidden states作为每个token的向量表达,该表达被作为分类问题的输入,输入到分类系统中去。属于这类的经典问题有SQuAD(answer endpoint classification)。
3)Sequence Generation Tasks
天然比较适合做序列生成的任务,比如概括性的问答,文本摘要,机器翻译。
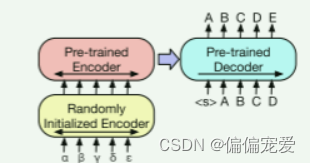
4)Machine Translation
将BART的encoder端的embedding层替换成randomly initialized encoder,新的encoder也可以用不同的vocabulary。
Comparing Pre-training Objectives
- Language Model Similarly to GPT we train a left-to-right Transformer language model. This model is equivalent to the BART decoder,without cross-attention.
- Permuted Language Model we sample 1/6 of the tokens, and generate them in a random order autoregressively
- Masked Language Model Following BERT , we replace 15% of tokens with [MASK]symbols, and train the model to independently predict the original tokens.
- Multitask Masked Language Model we train a Masked Language Model with additional self-attention masks. Self attention masks are chosen randomly with the follow proportions: 1/6 left-to-right, 1/6 right-to-left, 1/3 un-masked, and 1/3 with the first 50% of tokens unmasked and a left-to-right mask for the remainder.
- Masked Seq-to-Se ,we mask a span containing 50% of tokens,and train a sequence to sequence model to predict the masked tokens.
Results
-
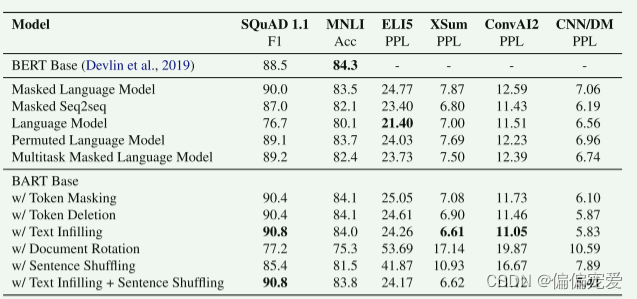
Performance of pre-training methods varies significantly across tasks
预训练的效果是和预训练的任务相关的,说白了也就是和任务数据相关。 -
Token masking is crucial
前文说的文档转换(Document Rotation)或句序打乱(Sentence Permutation)的方式在单独使用时表现不佳。而使用删除(Token Deletion)或掩码(Token MASK)效果比较好,这是个关键点。其中,在生成任务上,删除的方式大体上要优于掩码的方式。 -
Left-to-right pre-training improves generation
对于生成任务,基于掩码机制和乱序机制的模型表现不如基于其它机制的模型,而前者是不包括left-to-right自回归机制的模型,由此得出,自回归机制对于生成任务来说能有效提升性能。 -
Bidirectional encoders are crucial for SQuAD
双向编码的机制在SQuAD预训练任务上是非常关键的,比如BERT模型。不过,BART模型在该任务上也表现的很好。 -
The pre-training objective is not the only important factor
预训练的方式或许不仅仅是影响性能的唯一因素,模型本身结构上的改进也是很关键的,比如相对位置编码或者分级重复(我没想到是啥)结构。 -
Pure language models perform best on ELI5
在ELT5任务上,BART是唯一一个表现不如其它模型的,作者认为这是因为该任务的数据集相比于其它任务具有更高的困惑性,作者得出了一个结论:当输出仅受到输入的松散约束时,换句话说,输出不需要严格的参照输入的信息,BART的效果较差。 -
BART achieves the most consistently strong performance.
除了ELI5任务外,在有Text-filling方式参与的情况下,BART的表现都很好。侧面反映了Text-filling的有效性。
Large-scale Pre-training Experiments
- Discriminative Tasks
BART并没有因为单向的decoder而影响在文本理解类任务上的效果
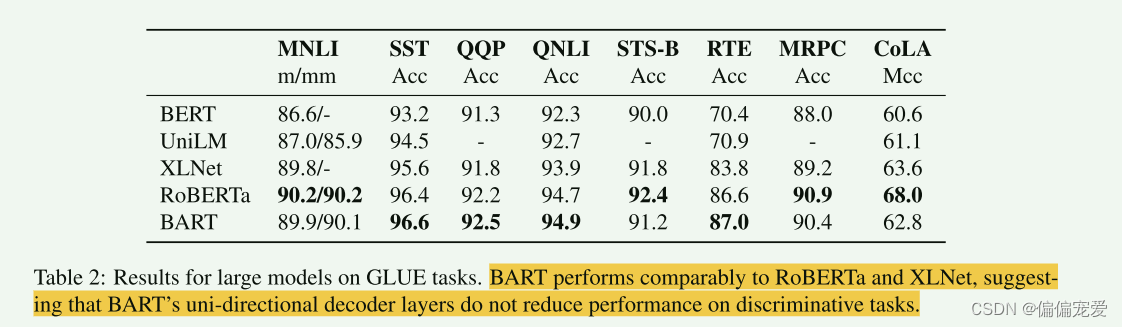
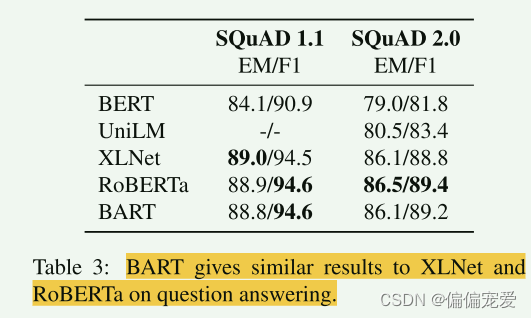
- Generation Tasks
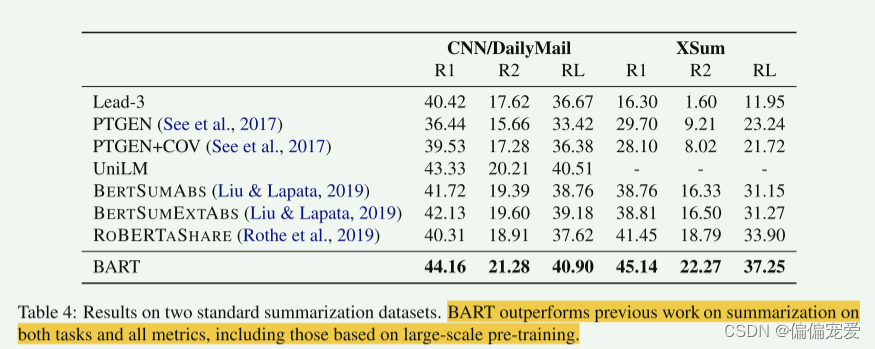
BART得益于单向的decoder,在生成任务上效果拔
摘要

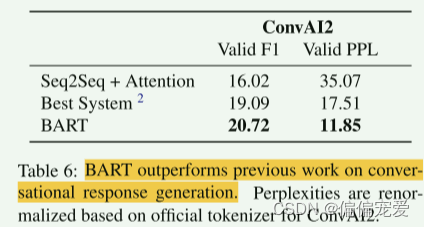
对话
抽象问答
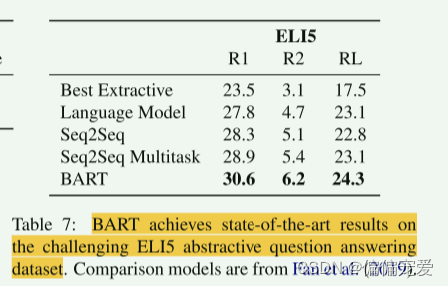
- 翻译

参考:
https://zhuanlan.zhihu.com/p/173858031
https://blog.csdn.net/qq_36583400/article/details/131394337














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









