







 BART是一种基于Transformer的序列到序列模型,用于自然语言生成、理解和翻译。它通过破坏文本结构并训练模型重构来预训练,结合了BERT的双向编码和GPT的自回归解码。在文本生成任务中表现出色,同时也适用于分类和机器翻译。预训练过程使用了如随机打乱句子顺序、文本填充等多种破坏方法。微调时,BART能适应不同的任务需求,如分类、token级别分类和生成任务。
BART是一种基于Transformer的序列到序列模型,用于自然语言生成、理解和翻译。它通过破坏文本结构并训练模型重构来预训练,结合了BERT的双向编码和GPT的自回归解码。在文本生成任务中表现出色,同时也适用于分类和机器翻译。预训练过程使用了如随机打乱句子顺序、文本填充等多种破坏方法。微调时,BART能适应不同的任务需求,如分类、token级别分类和生成任务。
目录
3.1 Sequence Classification Tasks(分类任务)
3.2 Token Classification Tasks(Token级别的分类任务)
3.3 Sequence Generation Tasks(文本生成任务)
4. Comparing Pre-training Objectives
5. Large-scale Pre-training Experiments
BART是一种非常适用与生成式任务的模型,当然它也能完成判别式任务,而且效果也很好。它主要结合了BERT和GPT两种模型思路,使得它不仅具有双向编码的优势,也具有单向自回归编码的优势。本篇主要探讨一下BART的原始论文,如果仅仅想作为了解,看完本篇介绍就够了,但是我还是强烈建议读者读一读原始论文。论文中的每一部分,我这里仅做要点解读。
Abstract

- BART沿用了标准的Transformer结构,也就是Encoder-Decoder的Transformer。
- BART的预训练主要依据以下两步走的思路:
1)通过随机噪声函数(说白了就是能够制造破坏文档结构的任何方法)来破坏文章结构;
2)逼迫模型能够学会将结构已经被破坏了的文章进行重构,使文章变回原来的样子;
至于如何破坏文章结构呢?作者说了,他们通过评估不同方法后发现采用下列方法效果最好,一个是随机打乱原文句子的顺序,一个是随机将文中的连续小片段(连续几个字或词)用一个[MASK]代替,和Bert不同,Bert是一个词用一个[MASK]替换,BART是连续多个词用一个[MASK]替换。

论文中,作者还仿照其它的预训练模型的方式,对BART进行了消融实验,也就是说,把BERT、XLNet等预训练方法移植到BART中,以此更好的验证哪一些模型的哪一些因素对最终任务的性能影响最大。
1. Introduction

这个和摘要中介绍的差不多,总之就是告诉我们BART的训练分两步走:通过随机噪声破坏文章结构,再训练一个序列到序列的模型来重构被破坏的文本。

对于片段式MASK,片段的长度是随机选取的,但实际上也不是随机的,后文有提到,用了泊松分布的方法采样不同长度的片段(包括长度为0)。

这里提到了,BART不仅在生成任务上(NLG)特别有效,同时在自然语言理解任务上(NLU)表现的也很出色。
下面看一些论文提供的BART示意图:
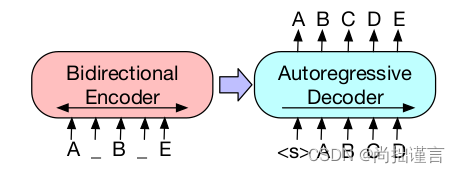

在BART中,它的输入输出并不需要严格的保持长度一致,即Encoder的输入与Decoder的输出不需要对齐。从上述结构图中可以看出,左边部分Encoder接收的结构破坏后的文章,它经过Encoder双向编码,类似于Bert,右边部分接收来自Encoder的输出后,经过自回归解码输出预测结果,类似于GPT(注意GPT是不需要Encoder的)。自回归解码依据的是最大似然概率,这一点和N-Gram词袋模型或者NNLM模型是相似的。作者在上图中还提到了,对于微调,BART的Encoder和Decoder接收同样的输入,且此时的输入文章是没有被破坏了的,这样一来,Decoder最后一维的输出被拿来作为文章的向量表示,类似于Bert,只不过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











