






作为一个程序员,可能或多或少经历过一些技术面试,有些是编程语言本身的问题,有些是跟工程相关的问题。
笔者自己被面试过或者面试过别人,今天我们来总结关于Python程序员面试的时候经常被问到的9个问题,供大家参考。
1、列表、元组、字典的区别?
这个问题应该经常被问到,我们在这里详细做个解释。
列表(List)
Python的列表实际上是一个动态数组,存储在一个连续的内存区块中,随机存取的复杂度是O(1),插入和删除元素时会造成内存块的移动,时间复杂度是O(n)。
同时它是一个可变对象,当我们对列表进行赋值时获取到的只是它的内存地址,如果需要将列表里的内容全部复制给另一个变量,需要用到copy(浅拷贝)和deepcopy(深度拷贝)。
元组(Tuple)
Python的元组是一个不可变的数据结构,它本质上也是一个数组。因为是不可变对象,所以Tuple的长度在创建时就是恒定的,所以我们也无法对它进行添加和删除元素的操作。不过在Tuple内所包含的对象是可变的。
当我们把包含元组的变量赋值给另一个变量时,实际上是在内存中重新申请了一块内存空间用于新建了一个元组。
字典(Dict)
Python的字典是一个哈希表,根据键值对(Key,Value)直接访问的数据结构。关于哈希函数在这里不多做解析,大家可以自行了解。
如果字典在产生哈希冲突时,也就是Key遇到重复的时候。Python会通过开放定址法来计算下一个候选位置,反复测试最终保证生成的哈希值不会产生冲突。
字典跟列表一样,也是可变对象,复制内容同样需要用到copy(浅拷贝)和deepcopy(深度拷贝)。
2、如何将一个字符串或者数字倒序输出
字符串倒序,我们可以利用Python的切片对字符串进行倒序,参考如下代码:
str1 = "长风几万里,吹度玉门关"
print(str1[::-1])
切片的参数格式: [start_index: stop_index: step]
如果我们不填写切片起止位置参数,那么默认是取字符串全部内容,当step参数(步长)为负数时,字符串会自动从右往左取值,-1就是依次取值,那么就自然是倒序了。
我们同样可以通过切片的原理对数字进行倒序输出。
# 正整数的情况
number = 10002
new_number = int(str(number)[::-1])
# 负整数的情况
number = -10002
new_number = int('-{0}'.format(str(abs(number))[::-1]))
3、谈一下Python的内存管理机制
Python内建了垃圾回收处理机制,引用计数是这个机制的一部分。
在Pyhton源码中,实际上是用 Py_INCREF(op) 和 Py_DECREF(op) 这两个宏来增加和减少引用计数。
当一个对象被创建、被赋值、被参数传递,函数返回之前的时候,它的引用计数值(ob_refcnt)都可能会被加1(INC),一直进行累加。
当对象变量失去作用域的时候,引用计数的值会减1(DEC)。
当一个对象的引用计数减少到0之后(ob_refcnt为0),Py_DECREF(op)会调用该对象 “析构函数”(del) 将其从内存中释放。
4、什么是Session、Cookie、Token?
Session是一个概念,信息存储在服务端。
Cookie是对Session的一种实现,并信息存储在客户端(浏览器)。
因为HTTP协议无状态的特性,以至于我们需要在浏览器和服务端之间建立一个用于识别用户身份和详细信息的凭证,这个凭证可以是Cookie、Token任意一种。
当用户登陆成功时,我们可以将其的身份凭证在服务端生成一个Session信息,保存在文件,数据库或者内存里,通常Session会有一个Session id。
因为访问服务端Session 信息需要用到Session id,所以通常情况下,我们将Session id存在Cookie里。
Cookie其实信息在用户登陆产生Session信息之后再将Session id或者别的附加信息返回给客户端,由客户端存储在本地文件里。
当浏览器向服务端发起请求时会带着Cookie里的Session id访问服务端,服务端根据Session id找到存储好的Session信息,如果信息能找到并且内容无误,即视为访问有效。
Cookie除了存储Session id外也可以存储其他非敏感的信息(例如用户昵称,头像等),提供给浏览器直接使用,而不用每次都从服务端去拿。
关于Token,实际上用在基于RESTAPI相关的服务里比较多。
它的认证机制是当用户登陆后服务端算出一个Token信息存储在服务端并返回给客户端,内容通常包含 用户id,当前时间戳,签名和其他信息。
Token在客户端一般存放于localStorage、cookie、或sessionStorage中。在服务器一般存于数据库中。
当客户端再次请求服务端时,会从本地拿到Token信息,并放在headers中,服务端收到请求,会自动去headers里拿到Token进行解析以用于识别用户身份。
5、GET和POST的区别和作用?
GET和POST在本质上没有区别,HTTP协议并没有规定GET和POST传输数据长度的限制。
唯一的限制可能存在于服务端的服务程序和浏览器。
通常在 Nginx或者各种WebServer服务程序里会有定义GET和POST传输最大长度的限制。
而GET提交的数据长度限制通常取决于浏览器,每种浏览器的限制不一样。
在HTTP协议中,使用什么样的Method和数据如何传输其实没有相互的关系,在绝大多数的WebServer里。GET和POST提交的数据其实都在BODY区域内,我们既可以通过GET来传输文件,也可以通过POST来传输文件。
之所以通常定义GET用来获取数据,POST用来提交数据是因为GET请求是幂等的,POST请求不是。
幂等性是指一次和多次请求某一个资源应该具有同样的副作用。简单来说意味着对同一URL的多个请求应该返回同样的结果。
基于幂等的原则,我们用GET进行数据的添加修改删除时会有副作用,因为在网络情况不好的时候GET会自动尝试重试,增加了重复操作数据的风险。而用它获取数据就不会存在这样的风险,因为我们哪怕对一个资源请求100万次,它还是不会改变。
这个问题看面试官的技术水准,如果面试官愿意跟你聊得比较深入,那你可以这么回答。如果面试官自己心里也是一些标准答案的话,那建议只回答GET用于获取数据,POST用于提交数据。
另外DELETE方法其实也是幂等的,哪怕你删除100万次,数据其实也只会被删除一次。
6、什么是Python的装饰器
Python的装饰器本质上也是一个函数,它的用处是可以让其他函数不做太多代码变动的情况下增加装饰器函数相关的功能。
先来看看装饰器的实现和应用。

以上我们实现了一个极简的Python装饰器,在fun1函数运行开始和结束的时候打印日志,通过这个例子我们可以发现,实际上Python的装饰器帮我们简化了调用代码,如果不用装饰器,那以上代码可以这样写。
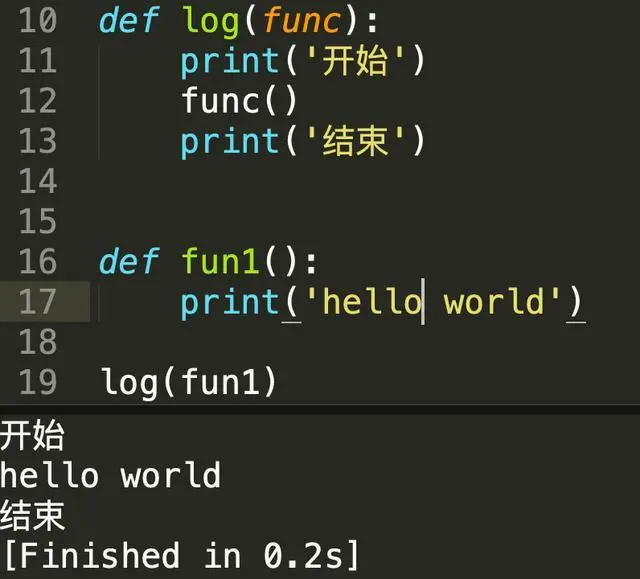
以上代码会显式的通过log函数去调用func1函数,不便于理解,也破坏了代码调用的顺序,不够优雅。如果我需要给fun1前面加上10多个装饰器的话,那得把这个调用关系写上十多次,在阅读理解上来看基本就是灾难。
Python的装饰器通常用于但不限于以下场合。
- 日志打印
- 性能测试
- 数据库事务处理
- 权限校验
- 缓存处理
总结起来Pyhton装饰器的用处是为了让我们更好的复用代码,在实现相同功能代码的情况下,采用更符合人类理解的代码结构。
其实Python的装饰器就是JAVA语言中的AOP编程(面向切片)。
7、Python的全局锁、进程、线程、协程的概念
Python的全局锁是为了保证线程安全而做的妥协,简单的说就是不管是几个核的CPU也只能在同时间运行一个线程。IO密集型运算,多线程还勉强能用,如果是CPU密集型的,那Python的多线程几乎没什么卵用。
如果要利用CPU多核的优势可以用到进程,在Pyhton中的multiprocessing模块来处理这个问题,每个计算任务都会单独起一个Python进程,让任务运行在独立的解释器环境中,提高运算效率。
而协程的概念是在于线程和进程在CPU用户态和内核态之间进行切换时会产生大量的性能开销。
在这种情况下,协程或者叫微线程的概念应运而生。
在Python3.5中之后用async/await关键字来处理协程。
它的优点是:
没有线程之间切换切换的开销。
没有线程锁的机制,因为只有一个线程,不存在共享变量加锁的情况,进一步提升了效率。
8、列表推导和字典推导
# 列表推导
list1 = [i for i in range(5)]
# 字典推导
dict1 = {k:v for k,v in dict.items()}
# 集合推导
set1 = {x*2 for x in [1,2]}
列表推导、字典推导、集合推导都是Python的特性,字典推导在Python2.7之后才有。
这三种推导方式的作用都是可以通过已有的数据序列构建另一个新的数据序列的结构体,从代码可读性和收敛的角度来讲是很有必要的,避免了繁复琐碎的代码写法。
9、生成器
# 构造生成器
x = (i for i in range(10))
# 输出x
<generator object <genexpr> at 0x10e9d40c0>
我们可以通过以上代码看到生成器的格式和列表推导格式很像,唯一区别是把方括号换成了圆括号,通过生成器生成出来的对象不再是一个列表,而是一个生成器对象。
生成器generator的作用是当我们要产生一个很长的序列,不一定马上用到它,那么我们就没必要再生成它的时候就开辟很大一块内存空间,而是先声明一个对象,告诉它我需要一块很大的内存空间,但是等到我用的时候再挨个去产生就行了,这个在其他语言里面有个词叫做“惰性求值”,大家望文思意即可。
我们可以直接用 for循环去遍历生成器对象,依次取出值。
关于这9个面试的问题就先讲到这,篇幅所限我们其实讲得不够深入,因为如果要深入的讲,这里的每一个知识点都可以花上一整章来详细的说,不过我觉得大家可以根据这些知识点自行去了解和实践更多的细节。
程序员面试对于面试官来说其实不是你能答对多少问题,而是你回答的问题质量是否说中了他所认同的那一部分,我们对于每一个知识点掌握得越详细,说中对方认同的部分就越多,成功率就越高。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1601
1601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









