







最邻近规则分类算法(K-Nearest Neighbor),Cover和Hart在1968年提出了最初的邻近算法,也被称为基于实例的学习或懒惰学习,与决策树算法相比,处理训练集的时候并不建立任何模型,进行分类时才将测试样例和所有已知实例进行比较进而分类。
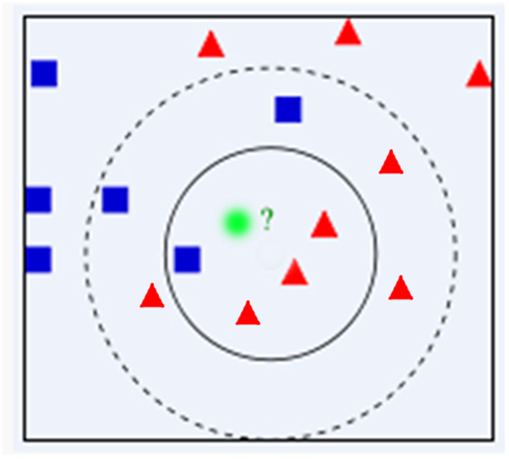
如上图,主要有两种色块,蓝色方块和红色三角,对绿色未知圆点进行判断分类,其属于红色还是蓝色?
KNN算法一般可以分为两步,为了判断未知实例的类别,会以所有已知实例作为参照,计算未知实例与所有已知实例的距离。所以第一步先分别计算出圆点和所有色块的距离。
第二步,选择一个参数K,判断离未知实例最近的K个实例是什么类型,以少数服从多数的原则进行归类。
上图中,假如我们选择K的值是1,则离未知实例最近的一个色块是蓝色,未知实例被归类为蓝色。假如我们选择K的值为4,则很明显,离未知实例最近的4个色块3个是红色,1个是蓝色,未知实例被归类为红色。
所以K的选择对结果的影响很大,一般为了得出结果K选择奇数,通过增大K也可以增强对噪音数据的健壮性。
对于距离的衡量方式有很多种,最常用的是Euclidean distance:
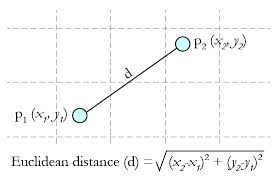
二维的下距离计算公式如上图简单的数学公式,扩展到n维下x,y两点的距离公式:
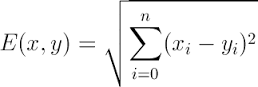
KNN算法优点是简单易于理解和实现,缺点是需要大量的空间存储所有实例,因为未知实例要和所有实例进行计算算法复杂度高,而且当一类样本过大,则不管未知实例属于哪一类都很容易归为数量过大的这一类。
如图:
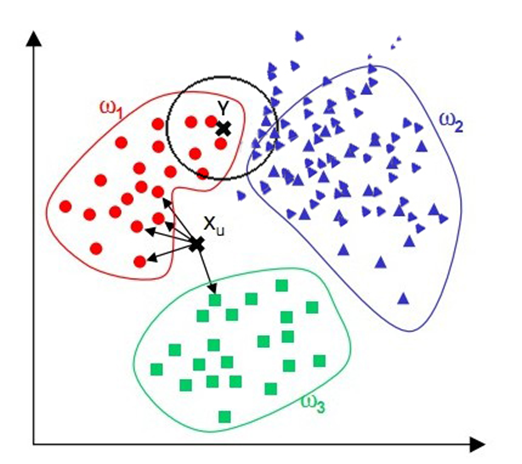
Y点肉眼去看因为在红色区域内很容易判断出多半属于红色一类,但因为蓝色过多,若K值选取稍大则很容易将其归为蓝色一类。为了改进这一点,可以为每个点的距离增加一个权重,这样里的近的点可以得到更大的权重,比如距离d,权重1/d。
再计算一个例子:
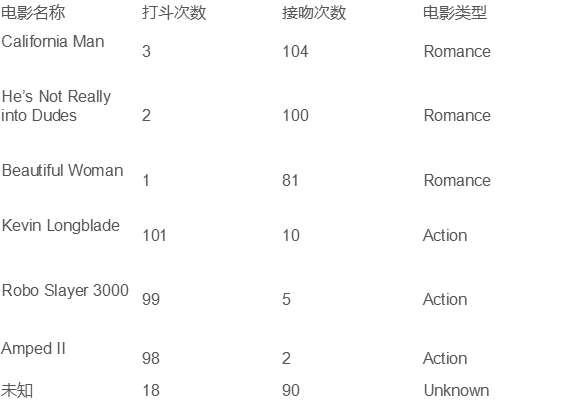
根据电影的打斗次数和接吻次数,将电影分类为Romance和Action,已经有6个已知样例,怎么样根据未知样例的打斗次数和接吻次数判断其电影类型?
将打斗次数和接吻次数作为二维坐标,判断每个已知样例电影与未知电影的距离,可以得出最近的3个电影都是Romance电影,则未知电影判断为Romance电影,这就是KNN算法。
下一篇是Python对KNN算法的实践。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









