







之前的几篇里面讲了机器学习分类问题的一些算法,下面几篇来讲一下回归问题。
回归问题和分类问题有什么区别呢?
分类问题预测的结果是一些类别值,比如说,颜色类别,电脑品牌,有无信誉等。
回归问题预测的是连续型的数值,如房价,人数,降雨量等等
生活中我们做决定的过程通常是根据两个或多个变量之间的关系,解决回归问题就是通过建立方程来模拟两个或多个变量间的关系,被预测的变量叫做因变量,被用来预测的变量叫做自变量。回归问题在中学阶段的数学课上已经有过简单涉及,这里也算是再次复习一下。
本篇所讲的简单线性回归,就是只包含一个自变量(x)和一个因变量(y),两个变量的关系用一条直线来模拟的回归问题。至于包含两个以上变量的多元线性回归,以及非线性回归在后面的篇幅中再说。
先来看理解线性回归的几个方程
简单线性回归模型:
y = β1x + β0 + E
这里的β1和β0分别是直线方程里的参数。E代表着随机因素带来的偏差,
是均值为0的正态分布。
简单线性回归方程:
E(y) = β1x + β0
这里E(y)代表y的期望,因为偏差E均值为0这里去掉。
简单线性回归估计方程:
y估计 = b1x + b0
这里的b1和b0是我们根据一组已知的x,y样本计算出的值,是线性回归方程的估计参数,也是我们想要利用简单线性回归要计算出的参数。
另外简单线性回归自变量与因变量之间的关系包括,正向线性关系,反向线性关系,无关系,分别对应方程直线斜率>0, <0, =0的情况。
线性回归分析的流程:
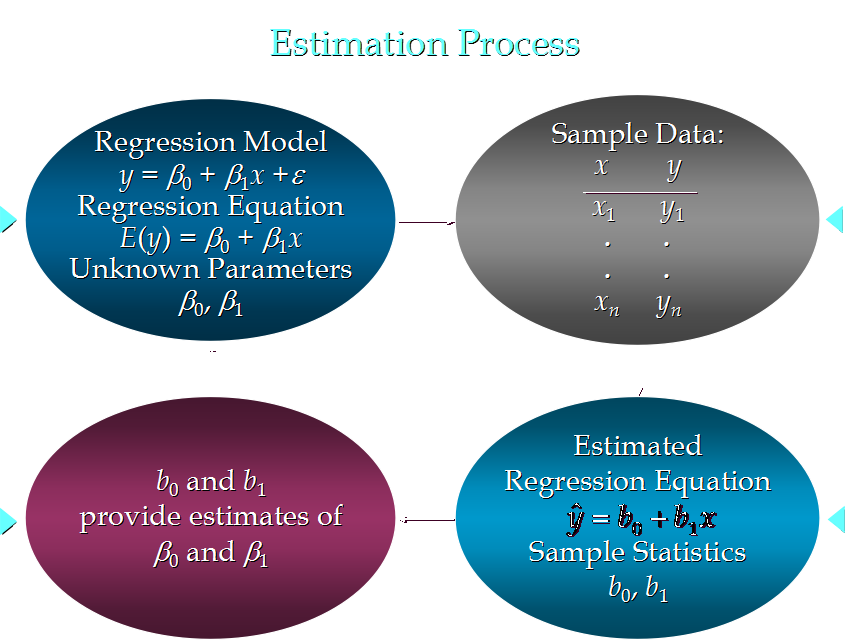
那么怎样通过一组样本列出简单线性回归的估计方程呢?下面用一个例子来说明。
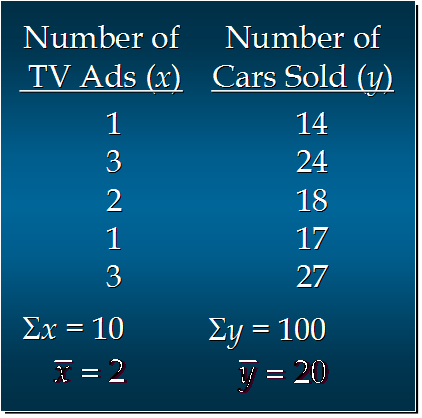
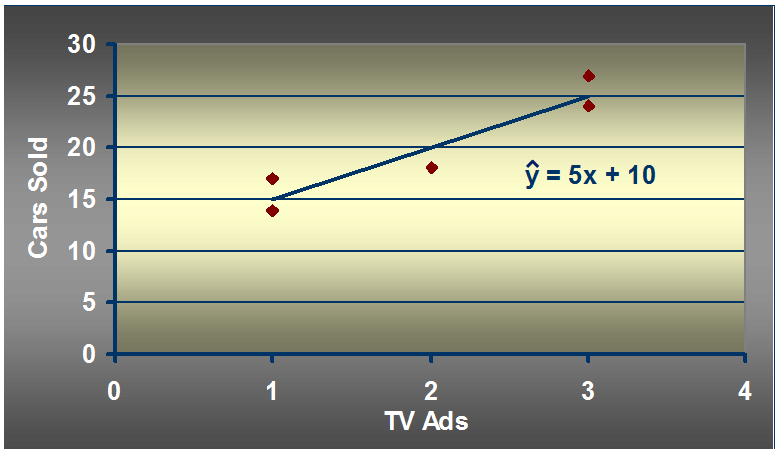
一家汽车厂商月广告的数量x与月汽车销售数量y的对应关系如上图所示。
只有一个自变量x和一个因变量y,典型的简单线性回归问题。
我们要做的就是找到一条直线,使得上表中每一个x对应的y值与方程中相应x的y值之差的平方的和最小。
也就是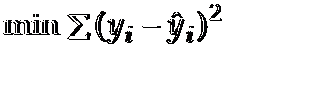
满足这种情况的直线也就是最能代表这组样本趋势的一条直线
y估计 = b1x + b0 ,要做的就是求这种情况下的b1,b0。
求解过程利用到一个极值问题,上述公式差平方的和最小,这里略去推导的过程直接给出最终的公式:
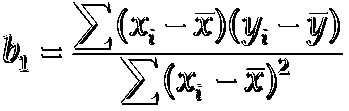
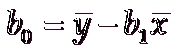
通过上述公式就能求解出b1和b0的值,这里计算一下,将上图中的数据代入公式中,解出b1 = 5, b0 = 10
也就是最终的线性回归的估计方程为
y = 5x + 10
这样假如再给出比如月广告数量x为7,那么就可以推算出月销售数量y为45。
如图:
下面是简单的Python的实现
import numpy as np
#因为要用到均值等计算所以调用numpy库
#np.mean(x)返回列表x的均值
#函数fitSLR输入样本,列表x,y 返回最终估计方程的b1, b0, 主要还是直接使用上述给出的代数公式
def fitSLR(x, y):
n = len(x)
denominator = 0
numerator = 0
for i in range(0, n):
numerator += (x[i] - np.mean(x)) * (y[i] - np.mean(y))
denominator += (x[i] - np.mean(x))**2
b1 = numerator / float(denominator)
b0 = np.mean(y) - b1*np.mean(x)
return b0, b1
#预测的函数, 给出要预测的x值,和估计方程的b0,b1,返回一个y值
def predict(x, b0, b1):
return b0 + x*b1
#下面用两组列表调用上定义的两个函数调用一下
x = [1, 3, 2, 1, 3]
y = [14, 24, 18, 17, 27]
b0, b1 = fitSLR(x, y)
print "intercept:", b0, "slope:", b1
x_test = 7
y_test = predict(7, b0, b1)
print "y_test:", y_test
#成功根据计算好的方程,预测x=7时,y预测结果为45

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









