







Leetcode–寻找递增子序列
每日一题里面先随到了股票…好家伙直接跳过,这难度好像对新手不太友好。于是第二题就是它啦!
题目描述:

看到这个题目不知道大家第一想法是啥(我看好多大佬们都是直接dfs,俺还不知道这是个啥东东,于是就直接上最笨的方法来了),反正俺第一想法就是找到所有子列,然后看其是否递增,从题目原意来理解我想还是很直接的(毕竟人家说数组长度不大于15哈哈哈哈哈,不然这暴力解法必然Timeout)。那么就一步步来做吧!
获取list中所有元素的子列(寻找集合子集)
学过小学(中学)数学的大家应该都知道,集合子集的个数为
2
n
2^n
2n,那么在程序中如何找到这么多个组合来作为集合子集呢,这里提供两种思路,这两种思路基本涵盖了所有寻找子集的方法。
- 利用数组下标做文章
这一方法主要利用数组的下标来构建子集集合,具体的思想是:子集的个数 2 n 2^n 2n可以被视为一个二进制选通开关。举个栗子,一个长度为4的list,它的子集个数为24共计16个,那么对应的就是二进制0000~1111,不知道大家有没有看出点端倪。其实根据二进制位是否为1,我们就可以构建出原数组的下标组合,将对应的下标组合生成新的sublist,组合在一起就是全部的子集啦!代码实现见下文:
可以看到,上述方法构建出了完整的集合的子集def subsets(nums: List[int]) -> List[List[int]]: answer = [] # length of list N = len(nums) # 2^N: number of subsets for i in range(2 ** N): # traverse all binary value from 0000 - 1111 subset = [] # find bits which is 1 for j in range(0, N): if (i >> j) % 2: subset.append(nums[j]) else: continue answer.append(subset) return answer >>> subset([1,2,3,4]) [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3], [4], [1, 4], [2, 4], [1, 2, 4], [3, 4], [1, 3, 4], [2, 3, 4], [1, 2, 3, 4]] - 采用动态生成的方法构建子集集合
这种方法是一种直观上最容易理解的方法,我们从头开始遍历数组,每遇到一个新的元素就将其加入到我们原来子集中的每一个元素中去,最后就可以生成一个完整的子集集合,上菜:
应该说这种方法的实现相较于上面方法更加直观一些,但是从leetcode提交的结果来看,前者的效率更高。至此,找寻List子集的两种方法介绍完毕。def subset(nums: list) -> list: answer = [[]] last_sublist = [[]] for num in nums: for ans in last_sublist: answer.append(ans + [num]) # the `copy` function here does matter, since the `=` can lead to the same # memory space for both `answer` and `last_sublist`, which is unwanted last_sublist = answer.copy() return answer
寻找所有递增子列
通过上述方法获取到子列之后,我们还需要判断每个子列是否为递增的情况,这一步就很好办了,遍历每个子列,只要后面一个元素比前一个大,就认为是递增子列,这一条件在整个子列中满足即可。值得注意的是,上面获取到的子集中存在空集以及元素个数为一的集合,因此需要剔除这些子列,对剩下的子列进行研究。具体代码实现如下:
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
answer = []
# length of list
N = len(nums)
# 2^N: number of subsets
for i in range(2 ** N):
# traverse all binary value from 0000 - 1111
subset = []
# find bits which is 1
for j in range(0, N):
if (i >> j) % 2:
subset.append(nums[j])
else:
continue
answer.append(subset)
return answer
def findSubsequences(self, nums: list) -> list:
result = []
subsets = self.subset(nums)
# remove subsets with length < 2
sublists_condition = [subset for subset in subsets if len(subset) >= 2]
# traverse all subsets, find those with increase order
for subset in sublists_condition:
for i in range(1, len(subset)):
if subset[i - 1] <= subset[i]:
continue
else:
i = 0
break
if i == len(subset) - 1 and subset not in result:
result.append(subset)
else:
continue
return result
上面方法的执行效率可以说是非常低,给大家看一个非常羞耻的图叭:
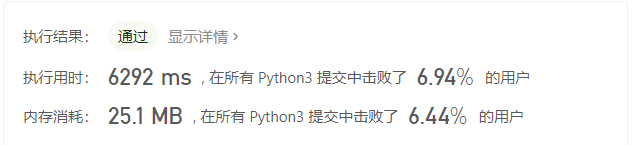
就是这么差劲。作为优秀的代码搬运工,我把leetcode上一个优质答案给搬了过来
def findSubsequences(self, nums: list) -> list:
"""
491. 递增子序列
:see https://leetcode-cn.com/problems/increasing-subsequences/
"""
# 用字典存以数字key结尾的所有递增子序列
all_list = {}
for i in nums:
# 把单个数字也当做一个递增子序列,以便后续计算
new_list = [[i]]
# 遍历字典中所有结尾数字key小于等于当前数字的情况,将其所有递增子序列加上当前数字
for j in all_list:
if j <= i:
for k in all_list[j]:
new_list.append(k + [i])
# 此时的new_list,就是遍历到i时,以数字i结尾的所有递增子序列
all_list[i] = new_list
result = []
for i in all_list:
# 从下标1开始的原因是,去掉由单个数字组成的递增子序列
for j in range(1, len(all_list[i])):
result.append(all_list[i][j])
return result
根据作者@Wu-GQ口述,该实现方法在时间上和空间上都秒杀几乎所有提交者,我愿称之为绝杀。作者的实现方法非常巧妙,充分利用了字典的动态生成特性,记录以列表中每个元素结尾的所有递增子列,这样最后遍历整个字典找出长度满足条件的递增子列即可。















 3276
3276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









