






老操作打开谷歌自带的抓包工具,在搜狗引擎内输入词条进行搜索。
这里用阿米娅来进行搜索。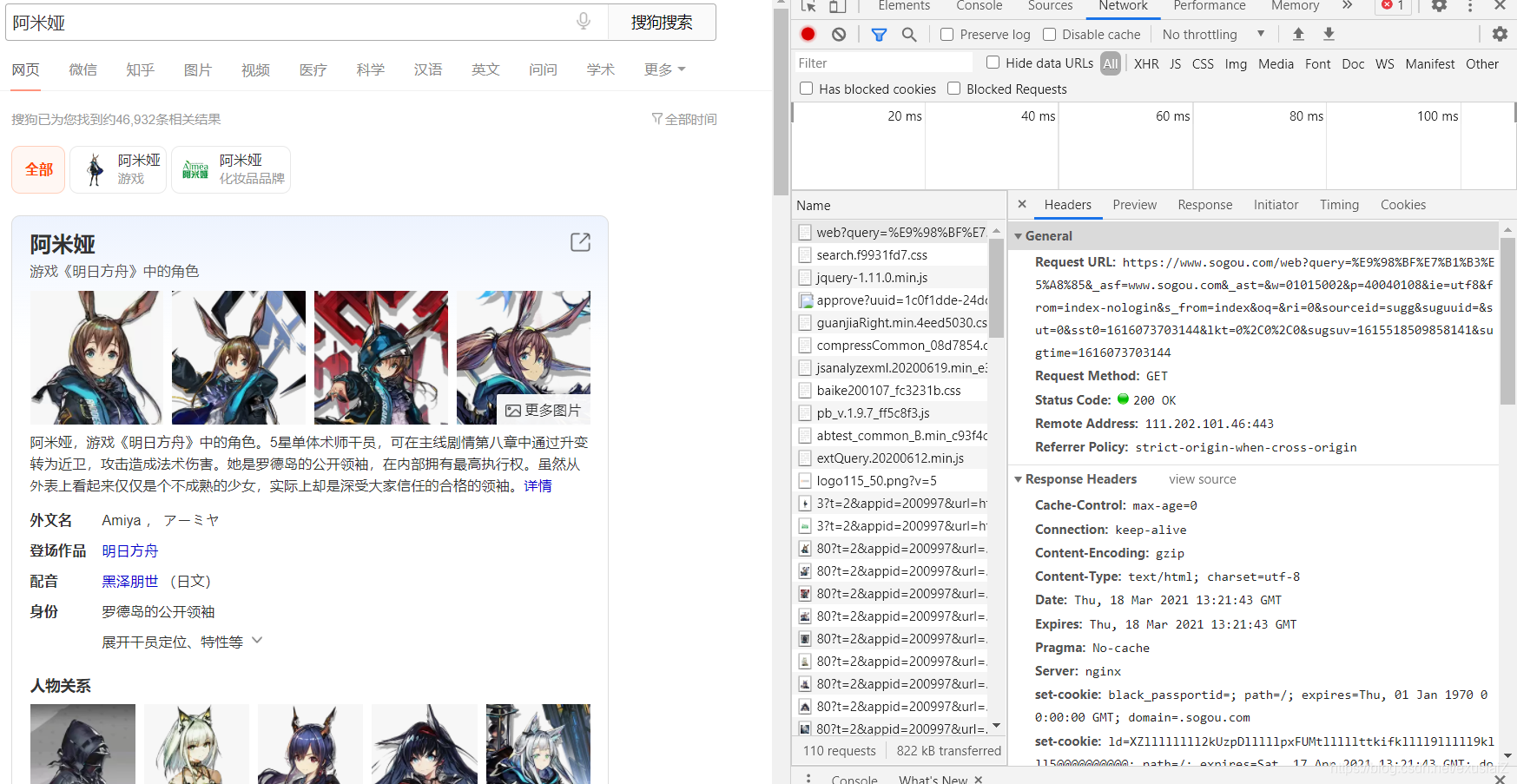
依旧在右侧的all中寻找我们要的数据:

获取到了URL以及Request Method为GET方式。
以及type为text。

发现了query名为阿米娅,证明了这个数据是词条关键字。
那么开始怼代码。
导包:
import requests
if __name__ == '__main__':
进行UA伪装:
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
第一步
指定url以及处理对应的参数,进行封装。
url = 'https://www.sogou.com/web'
kw = input('enter the word:')
zidian = {
'query':kw
}
第二步
发起请求
response = requests.get(url=url,params=zidian,headers=headers)
第三步
获取响应数据
text = response.text
第四步
持久化存储,在本地生成对应文件
filename = kw+'.html'
with open(filename,'w',encoding='utf-8')as fp:
fp.write(text)
print(filename,'保存成功')
源代码:
import requests
if __name__ == '__main__':
#UA伪装:将对应的User-Agent封装到一个字典中
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
}
# step1:指定url
url = 'https://www.sogou.com/web'
#处理url携带的参数:封装到字典中\
kw = input('enter the word:')
zidian = {
'query':kw
}
# step2:发起请求
#对指定url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response = requests.get(url=url,params=zidian,headers=headers)
# step3:获取响应数据
text = response.text
# step4:持久化存储
filename = kw+'.html'
with open(filename,'w',encoding='utf-8')as fp:
fp.write(text)
print(filename,'保存成功')
开始运行:

在下方输入词条,回车。

显示保存成功,这时同目录下生成对应文件,点击在浏览器打开。

ok。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









