







前言
本来是打算用一篇博客把完整的一次数据处理全部记录下来,但是无奈断(lan)电(ai)。同时也是为了写的更详(tuo)细(ta)一些,防止以后看不懂,所以我决定把三个大部分分开来写,同时,后面的内容我也打算这样处理希望各位大佬海涵。
———-我是逗逼的分割线———-
数据补充
上回书说到,船帆了,人挂了,大家各安天命了。(摔)。我们简单的对我们当前得到的数据进行了简单的分析,以此来找出我们最后训练时能够用到的特征值。我们用图或表进行了相关内容的可视化处理。一眼就能看出的赶脚,大概找出了几个可能有用的特征值:年龄(age),性别(sex),乘客等级(Pclass),以及有可能有用的堂兄弟个数(SibSp), 亲子个数(Parch)。
当然以上的内容都是我们结合图表大概分析得来,最终是否对训练有用当前我们是一概不知的。接下来可能有童鞋想说,我们是不是可以开始训练了?.当然不是。因为,我们在前文中说到过一个问题,那就是我们得到的数据是残缺的!(划重点)。残缺的啊有木有啊同志们。所以我们首先的当务之急是先要把我们所要使用的age选项来补齐。
那么问题又来了,我们该如何来补上这部分残缺的值呢?根据情况有这么两种方法
通常遇到缺值的情况,我们会有几种常见的处理方式
- 如果缺值的样本适中,而该属性非连续值特征属性(比如说类目属性),那就把NaN作为一个新类别,加到类别特征中。 如果缺值的样本适中,而该属性为连续值特征属性,有时候我们会考虑给定一个step(比如这里的age,我们可以考虑每隔2/3岁为一个步长),然后把它离散化,之后把NaN作为一个type加到属性类目中。
- 如果缺值的样本占总数比例极高,我们可能就直接舍弃了,作为特征加入的话,可能反倒带入noise,影响最后的结果了
有些情况下,缺失的值个数并不是特别多,那我们也可以试着根据已有的值,拟合一下数据,补充上。
这里我们采用大佬推荐的一种scikit-learn中的RandomForest来拟合一下缺失的年龄数据
from sklearn.ensemble import RandomForestRegressor
def set_missing_ages(df):
# 把已有的数值型特征取出来丢进Random Forest Regressor中
age_df = df[['Age','Fare', 'Parch', 'SibSp', 'Pclass']
# 乘客分成已知年龄和未知年龄两部分
known_age = age_df[age_df.Age.notnull()].as_matrix()
unknown_age = age_df[age_df.Age.isnull()].as_matrix()
# y即目标年龄
y = known_age[:, 0]
# X即特征属性值
X = known_age[:, 1:]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs=-1)
rfr.fit(X, y)
# 用得到的模型进行未知年龄结果预测
predictedAges = rfr.predict(unknown_age[:, 1::])
# 用得到的预测结果填补原缺失数据
df.loc[ (df.Age.isnull()), 'Age' ] = predictedAges
return df, rfr
def set_Cabin_type(df):
df.loc[ (df.Cabin.notnull()), 'Cabin' ] = "Yes"
df.loc[ (df.Cabin.isnull()), 'Cabin' ] = "No"
return df
data_train, rfr = set_missing_ages(data_train)
data_train = set_Cabin_type(data_train) OK,这里我们就把我们的数据补充完整,我们可以用describe来看一下我们的结果。
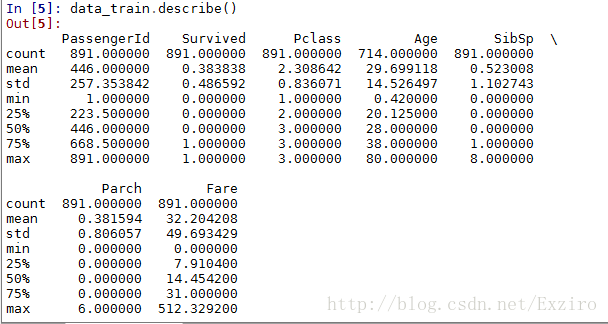
这是没有补全前的
这是补完后的
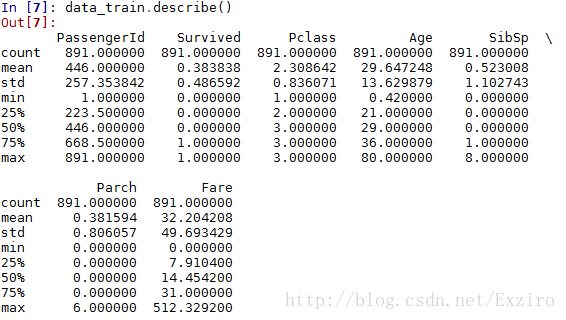
这里我们能够很明显地看出我们的Age选项是已经完整了的。是891个。同时我们可以看到,因为我们是拟合出的数据,所以我们补充数据前后的年龄的平均值相差并不是很大,虽然我们相信,这其中肯定还是存在着很大的误差,现实的情况也更加复杂,但是当前我们算是补全了这部分数据。
数据补全后,可能大家又要问了:这回我们可以开始正式地进行训练了吧。。。额。。。答案当然还是NO。因为我们这次训练的手段是运用逻辑回归来对数据进行处理。因为逻辑回归建模时,需要输入的特征都是数值型特征,我们通常会先对类目型的特征因子化/one-hot编码。这里有困惑的小伙伴可以参照这个了解一下什么事one-hot编码:http://blog.csdn.net/dulingtingzi/article/details/51374487
以Embarked为例,原本一个属性维度,因为其取值可以是[‘S’,’C’,’Q‘],而将其平展开为’Embarked_C’,’Embarked_S’, ‘Embarked_Q’三个属性原本Embarked取值为S的,在此处的”Embarked_S”下取值为1,在’Embarked_C’, ‘Embarked_Q’下取值为0。原本Embarked取值为C的,在此处的”Embarked_C”下取值为1,在’Embarked_S’, ‘Embarked_Q’下取值为0原本Embarked取值为Q的,在此处的”Embarked_Q”下取值为1,在’Embarked_C’, ‘Embarked_S’下取值为0。同理,我们对于我们的Cabin选项也做同样的处理。我们使用pandas的”get_dummies”来完成这个工作,并拼接在原来的”data_train”之上,如下所示。
dummies_Cabin = pd.get_dummies(data_train['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_train['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_train['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_train['Pclass'], prefix= 'Pclass')
df = pd.concat([data_train, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)完成后的情况是这样的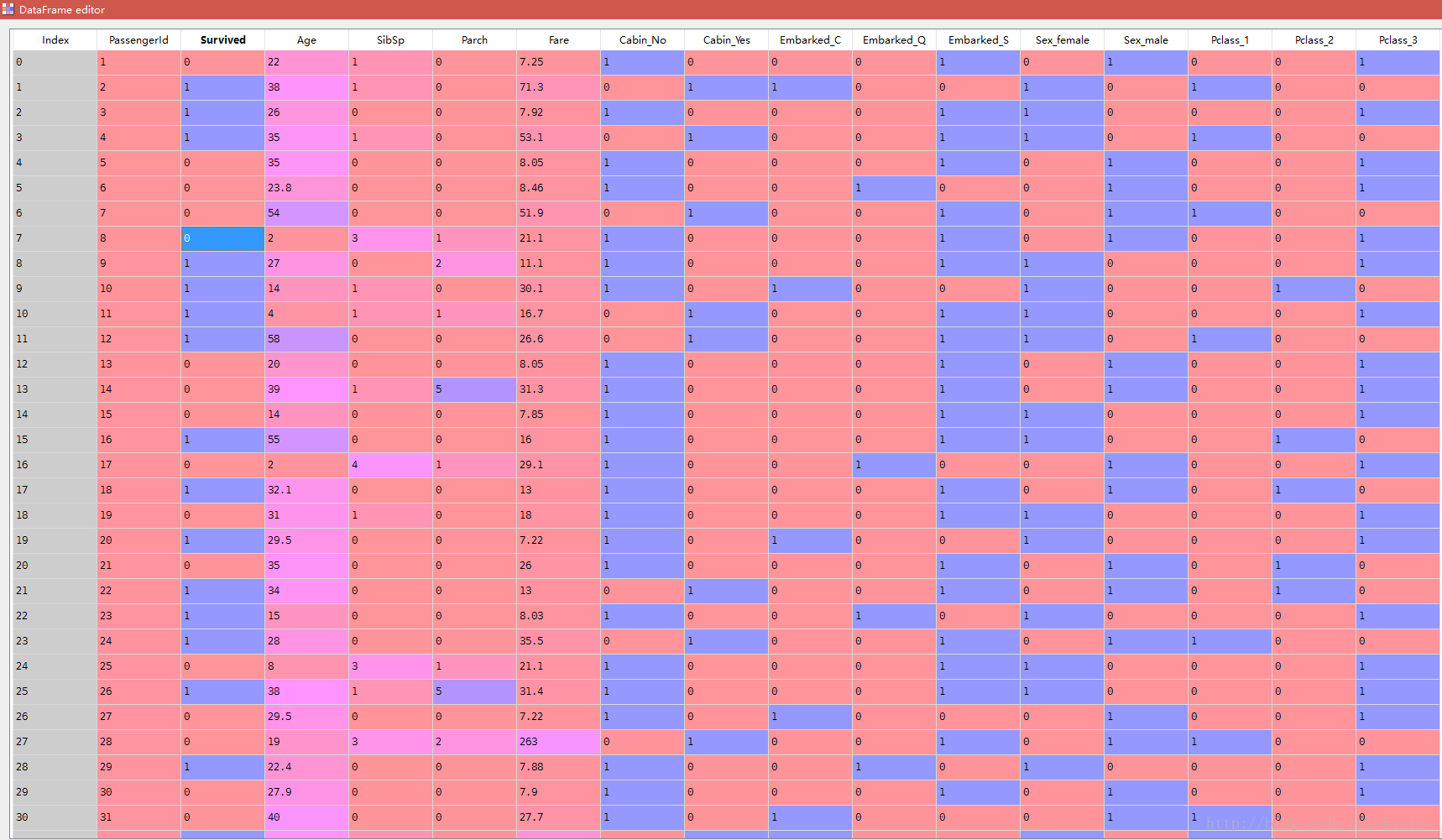
我们可以看到我们最后需要扔进去的特征值就全部在这里成为0和1了。
到了这里我们的简单预处理也差不多完成了,当然,如果看过hanxiaoyang大神那篇博文的童鞋,可能会发现大佬在这里进行了一次scaling.也就是我们所说的数据缩放。因为我们可以大概看一下我们当前处理的数据的情况,我们发现age和fare的数值变化有些大,如果大家了解逻辑回归与梯度下降的话,会知道,各属性值之间差距太大。这样对于我们最后的拟合会产生一些问题。严重的话会导致不拟合。如果看过我前面一篇逻辑回归介绍的同学可以知道,在梯度下降算法中,这个scaling的影响还是很大的。所以hanxiaoyang大佬采用的是scikit-learn里面的preprocessing模块。对我们的这两个数据进行一下scaling。就是将一些变化幅度较大的特征化到[-1,1]之内。
额,但是我在运行这一部分时发现了一些问题。也许是函数,也许是我的数据出现了问题。当然可能也是萌新的我不太懂。导致这里的数据不能很好的特征化,出现了报错。截止到目前,我还在研究相关代码,后期我会进行补上。因为后期我在处理的时候发现对拟合虽然产生了一定的影响,但是并不是很妨碍我们接下来的操作,所以我将这段代码省去,有兴趣的童鞋可以试一试加上这段代码。
import sklearn.preprocessing as preprocessing
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(df['Age'])
df['Age_scaled'] = scaler.fit_transform(df['Age'], age_scale_param)
fare_scale_param = scaler.fit(df['Fare'])
df['Fare_scaled'] = scaler.fit_transform(df['Fare'], fare_scale_param)
df建模
终于,终于。同志们我们终于要建模了。
首先,我们把需要的feature字段取出来,转成numpy格式,使用scikit-learn中的LogisticRegression建模。
from sklearn import linear_model
#用正则匹配出特征项
train_df=df.filter(regex='Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
train_np = train_df.as_matrix()
# y即Survival结果
y = train_np[:, 0]
# X即特征属性
X = train_np[:, 1:]
# fit到RandomForestRegressor之中
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
然后我们来看看我们最终训练出的是个什么东西了

ok这就是我们最终得到的式子了。是不是很兴奋!
接下来,有童鞋可能要问了,下面是不是直接把test扔进这个函数就Ok了?emmmmm当然不是。因为我们对于test还没有处理,乱哄哄扔进去,函数知道你整了个什么鬼东西。因此我们对我们的test做同样的数据处理。当然,分析就不需要了。
data_test = pd.read_csv("test.csv")
data_test.loc[ (data_test.Fare.isnull()), 'Fare' ] = 0
# 接着我们对test_data做和train_data中一致的特征变换
# 首先用同样的RandomForestRegressor模型填上丢失的年龄
tmp_df = data_test[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
null_age = tmp_df[data_test.Age.isnull()].as_matrix()
# 根据特征属性X预测年龄并补上
X = null_age[:, 1:]
predictedAges = rfr.predict(X)
data_test.loc[ (data_test.Age.isnull()), 'Age' ] = predictedAges
data_test = set_Cabin_type(data_test)
dummies_Cabin = pd.get_dummies(data_test['Cabin'], prefix= 'Cabin')
dummies_Embarked = pd.get_dummies(data_test['Embarked'], prefix= 'Embarked')
dummies_Sex = pd.get_dummies(data_test['Sex'], prefix= 'Sex')
dummies_Pclass = pd.get_dummies(data_test['Pclass'], prefix= 'Pclass')
df_test = pd.concat([data_test, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1)
df_test.drop(['Pclass', 'Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1, inplace=True)
#同理下面这段依然是缩放的scaling部分。如果前面出现错误 就先省去这一部分。
df_test['Age_scaled'] = scaler.fit_transform(df_test['Age'], age_scale_param)
df_test['Fare_scaled'] = scaler.fit_transform(df_test['Fare'], fare_scale_param)
激动人心的时刻到了,让我们把它扔进去。
test = df_test.filter(regex='Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*')
predictions = clf.predict(test)
result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':predictions.astype(np.int32)})
result.to_csv("logistic_regression_predictions.csv", index=False)最终生成了的就是我们的预测结果了。然后最终把它上传即可。

这是我的最终结果。到此,我们这一次初次尝试到这里就结束了么?当然还不是。。。。这只是一个最基本最基本最基本的结果。我们还没有对它进行任何的优化,优化的部分我们把它放到下一部分来记录。
end
PS:如果有问题的地方欢迎各位童鞋留言,共同学习共同进步是我的目标。当然,如果有大佬看过这篇文章有何意见也请留言,同时,对于我省略的那一部分的缩放 代码 有了解的童鞋请指导一下萌新谢谢了!!!
Thank you!














 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









