







最近学习了tcmalloc机制,它是go里面用到的内存分配机制。本文参考tcmalloc,加上一部分自己的理解。
tcmalloc VS ptmalloc(glibc 2.3 malloc)
对于小内存来说,tcmalloc提供线程级别的内存分配,这样就减少了线程之间的竞争,ptmalloc2也提供线程级别分配,但是它的内存被分配到某个线程后就不能重新分配给别的线程,这造成了较大的资源浪费。对于大内存来说,tcmalloc也采用了细粒度且高效的分配策略。
在2.8 GHz P4环境下,tcmalloc执行小内存malloc/free的时间大约为50ns,小于ptmalloc2的300ns。
另外在空间利用上,tcmalloc额外空间比较少,N个8字节的对象占用的总空间大概为8N*1.01,而ptmalloc2用4个字节管理每个对象,造成的空间利用率较小。
小内存分配和回收
线程维护了一个cache,用于小内存分配,当需要申请内存时,先从线程cache中进行分配,如果不够再从Central Heap的central free lists进行分配;此外,tcmalloc还会执行定期垃圾回收,将线程cache中过多的内存进行回收,放入central free lists中。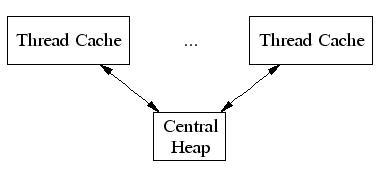
tcmalloc有大约88种大小的内存块(size-class),如果不足一块大小则会造成一定的碎片浪费,但是由于tcmalloc不是完全按2的指数倍进行分配的,所以浪费的空间不会很大。举个例子,内存块大小有8, 16, 32, 48, 64, 80,那么如果申请空间为70,分配块大小为80的即可,而不需要分配128造成较大的碎片浪费。所有的空闲块(class)以单链表进行维护,那么用到时直接从对应链表中取即可。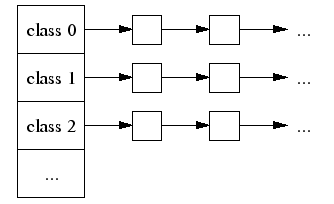
大体分配策略如下:
- 根据申请的大小,找到对应的块大小size-class。
- 如上图所示,从线程缓存链表中寻找对应块大小的空闲内存块
- 如果链表为非空,则直接返回,由于是线程内部没有竞争,所以不需要加锁。
如果链表为空,则
- 从central free lists中找到对应size-class的链表空闲块(结构跟上图线程缓存中链表一致)
- 将从central free lists空闲链表中找到的空闲块放入到线程缓存的链表中
- 从线程缓存的链表中返回一个
如果central free lists中对应size-class的链表也为空,则
- 则分配一个页
- 然后将该页划分出多个需要的size-class的块
- 将块放入central free lists空闲链表
- 将central free lists空闲链表空闲块一部分移入到线程缓存的链表中
- 从线程缓存的链表中返回一个
这种多级分配的好处在于,第一级是线程内部资源,不需要进行加锁抢占影响性能。
那么线程内部链表的长度到底应该为多少,如果小了将会导致不断从Central free list中进行申请,造成竞争;如果大了则会造成浪费。分配策略采取了慢启动增长的方式,防止系统因为大批量申请分配造成抖动,伪代码如下。
Start each freelist max_length at 1.
Allocation
if freelist empty {
fetch min(max_length, num_objects_to_move) from central list;
if max_length < num_objects_to_move { // slow-start, 每次只+1
max_length++;
} else { // 如果超过num_objects_to_move则快增长
max_length += num_objects_to_move;
}
}
Deallocation
if length > max_length {
// Don't try to release num_objects_to_move if we don't have that many.
release min(max_length, num_objects_to_move) objects to central list
if max_length < num_objects_to_move { // 尝试继续增长max_length长度
// Slow-start up to num_objects_to_move.
max_length++;
} else if max_length > num_objects_to_move {
// If we consistently go over max_length, shrink max_length. 计数策略,只有计数超过给定阈值,才会对max_length进行收缩,同样防止抖动。
overages++;
if overages > kMaxOverages {
max_length -= num_objects_to_move;
overages = 0;
}
}
}
中内存分配
中内存指的是大小为256KB到1MB的大小,将会分配多个页,Central Heap以8k为一个页。Central Heap有一个包含128个链表的heap,链表大小从1个页到128个页。那么,如果申请的空间需要多少个page则从heap对应项中的链表中取出一个,如果该链表为空,则从下一个链表寻找(将会导致重新划分,比如需要4个页,但是4 pages链表为空,则从5pages中拿一个,但是5pages应该拆分为2部分,一个为4page,一个为1page)。如果都不满足需求,则视为“大内存”分配。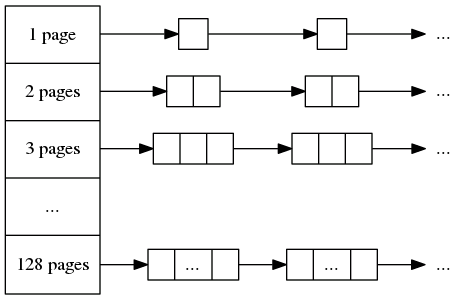
注意,中内存不是从线程缓存中分配,而是直接在CentralHeap。
大内存分配
大内存指的是大于1MB的块,这个将会从红黑树中进行分配。tcmalloc维护了一个红黑树用于标记不同的span,如果需要则从树种找到一个满足条件的最小的span进行分配。这可能导致span进行重新划分,一部分用于分配申请的大小,另外多出的部分可能重新放入到红黑树,也可能放入全局Centeral Heap的center free-lists(上图所示)。如果红黑树中找不到满足的span,则从系统中进行申请(tcmalloc采用sbrk和mmap)
Span
span对象负责管理连续的多个页,比如下图,a,b,c,d是4个span,管理不同大小的连续页。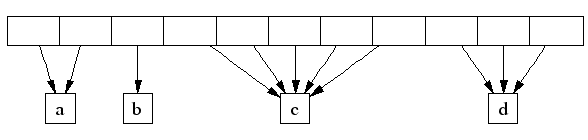
所有span组成一个span lists,span内部划分给多个对象使用,参加下图,图来自图解 TCMalloc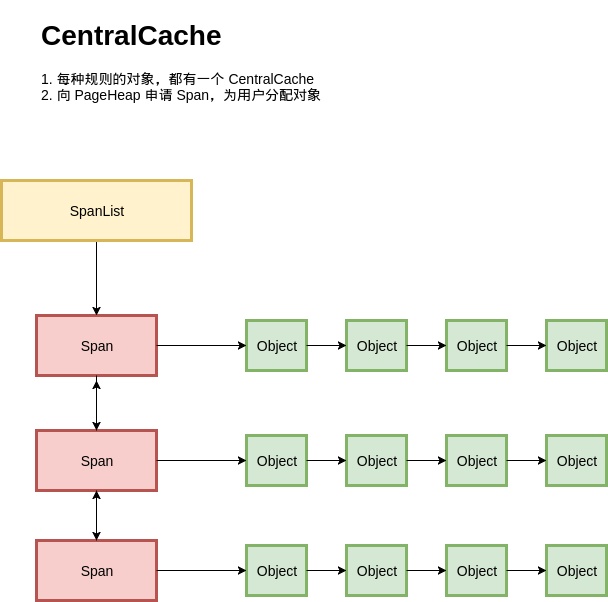
一个span可能被分配或者释放。如果释放了,挂入到page heap的链表中。如果申请了,可能作为大内存被分配,也可能被划分后进行分配,比如划分为多个小内存。如果被划分成小内存,则内部会记录各个size-class的分配情况。
同样还是上面第一个图,可以用一个数组记录各个页分别属于哪个span。但是这样对空间消耗比较大,每一块内存都需要一个数组元素表示,tcmalloc用基数radix tree(前缀树/字典树trie tree的一种压缩优化)记录映射情况,这样可以对前缀相同部分进行压缩。如果是32位系统,则树高2层,根节点包含了32项,叶子节点包含2^14项,则对32位系统来说,可以记录2^19个页(2^19 * 8k=2^32)。如下图所示,采用基数而不是前缀树的原因是为了空间压缩,如果是前缀树,则需要2^32 * 2 - 1=2^33-1个结点,就算结点内只有一个值和一个指针,存储这么多指针也需要浪费很多的空间。下图是手绘的radix tree示意图。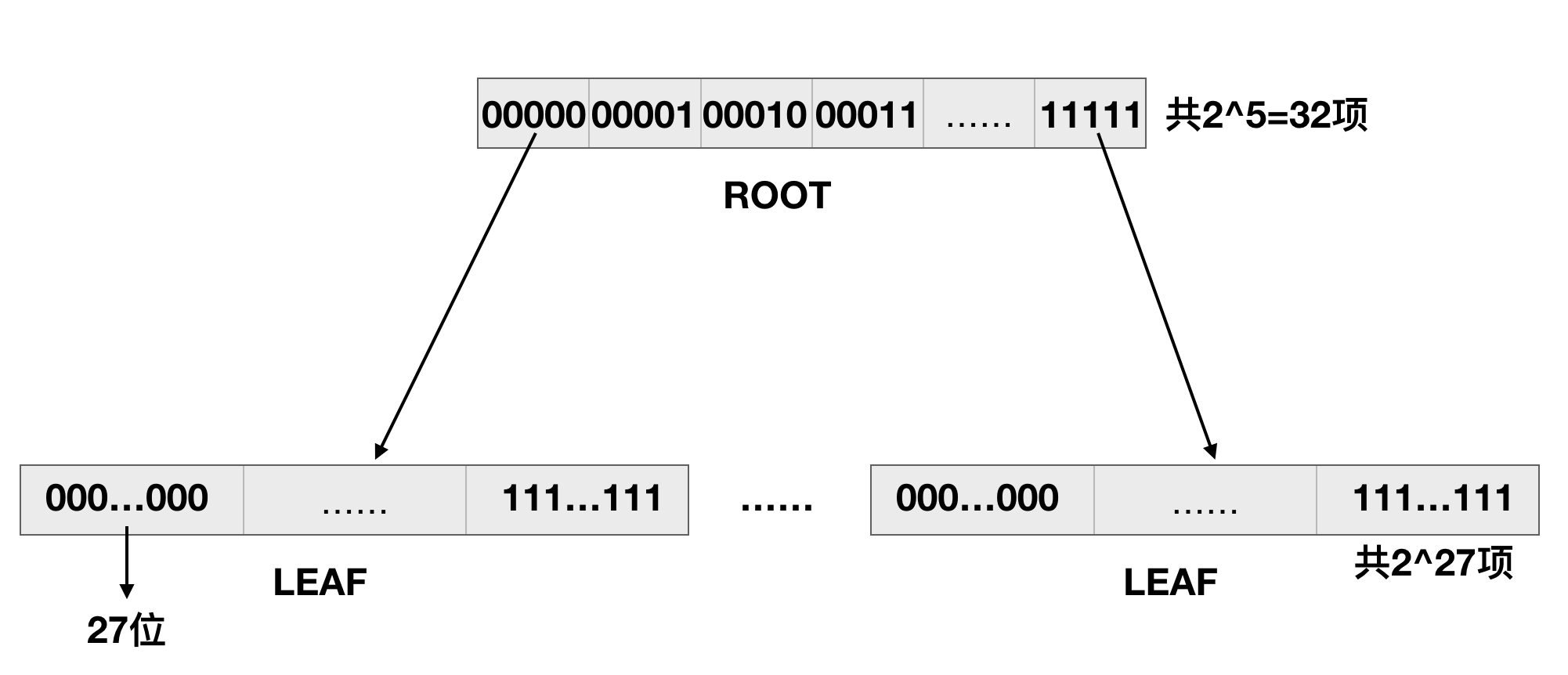
对于64位系统,则树高3层。
回收
当一个对象被释放后,通过计算页号,再通过radix tree得知所在的span,span可以知道是否为小内存,如果是的话还知道size-class(span内部维护该信息)。当然,在开始的时候说过,如果是小内存,释放会挂入线程内部的缓存链表,知道链表大小超过了阈值则会回收到central free lists。当然central free lists也可能发生回收,属于一个span的内存全部空闲后,将会触发回收。
如果是大内存,则通过span获取页跨度,假设为[p,q],那么寻找p-1和q+1所在的span是否为空,如果都为空,则进行合并后放入page heap(上面提到的红黑树)。
central free lists
上面我们提过,我们在central free lists中保存了不同size-class小内存用于二次分配。每个central free lists由二级结构组成,第一级是span,第二级是span内空闲空间组成的链表,保存小内存地址。如果线程内部小内存不够用,就从这里进行分配。如果线程内部小内存过多就行回收,也挂入这里的链表。如果一个span内的内存全都回收后,该span也将进行回收,放入到全局的page heap中。
线程缓存的垃圾回收
在开始讲小内存的伪代码中已经介绍过垃圾回收的机制。当线程缓存超过max_size以后,将会触发回收。垃圾回收只有在对象释放的时候才会发生。用户可以通过控制tcmalloc_max_total_thread_cache_bytes来控制num_objects_to_move的大小。每次垃圾回收,线程将尝试将自己的max_size变大。如果回收时max_size小于tcmalloc_max_total_thread_cache_bytes,那么max_size将会直接增长;反之,则会促使从别的线程中偷取max_size。
此处存在一个疑问:这种机制将会导致max_size超过tcmalloc_max_total_thread_cache_bytes,和上面伪代码中的收缩机制有什么区别?什么时候用收缩,什么时候从别的线程进行偷取?
说明
转载请注明链接:http://vinllen.com/tcmallocqian-xi/
参考:
https://gperftools.github.io/gperftools/tcmalloc.html
https://github.com/gperftools/gperftools/blob/master/src/tcmalloc.cc
https://zhuanlan.zhihu.com/p/29216091

















 7765
7765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









