







推荐模型分类
目前最流行的推荐系统所应用的算法是协同过滤,这项技术填补了关联矩阵的缺失项,从而实现了更好的推荐效果,它是利用大量已有用户偏好,来估计用户对其未接触的物品的喜好程度。
它包含两个分支:
1 基于物品的推荐(itemCF)
基于物品的推荐是利用现有用户对物品的偏好或是评级情况,计算物品之间的某种相似度,以用户接触过的物品来表示这个用户,然后寻找出和这些物品相似的物品,并将这些物品推荐给用户。
2 基于用户的推荐(userCF)
对用户历史行为的数据分析,如购买,收藏的商品,评论内容或搜索内容,通过某种算法将用户喜好的物品进行打分。根据不同用户对相同物品或内容数据的态度和偏好程度来计算用户之间的关系程度,在有相同喜好的用户之间进行商品推荐。
spark MLlib实现了交替最小二乘(ALS),它是机器学习的协同过滤推荐算法,机器学习的协同过滤推荐算法是通过观察所有用户给产品的评分来腿短每个用户的喜好,并向用户推荐合适的产品。
准备数据
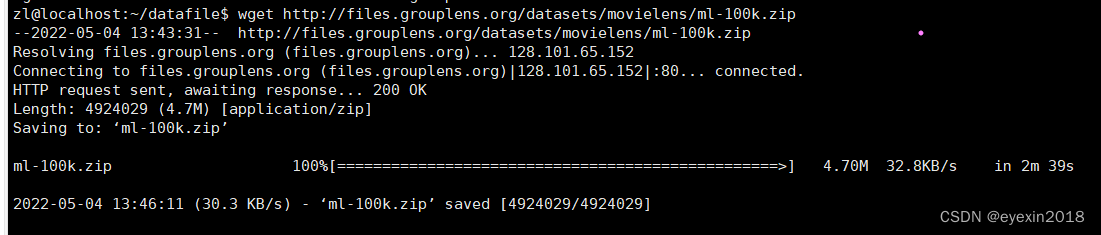
movieLens是一个推荐系统,以研究为目的,非商业性的,我们可以从上面下载实验数据ml-100k.zip进行学习
网址:https://grouplens.org/datasets/movielens/
也可以在Linux系统上输入命令下载
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip
上传数据到hdfs中
hadoop fs -put ml-100k /spark/
spark读取数据,生成RDD
val dataRdd=sc.textFile("/spark/ml-100k/u.data")
取出一行看看
dataRdd.first()
res0: String = 196 242 3 881250949
可以用take方法取前三个字段进行训练,先map拆分
val dataRdd3=dataRdd.map(_.split("\t").take(3))
dataRdd3.first()
res1: Array[String] = Array(196, 242, 3)
可以看到原先的一个string字段,变成了包含三个数字的数组。
这就是spark弹性数据集的机制,它的每一个数据都是由上游数据计算产生的,所以想要恢复只需做一次计算即可。
下面使用spark MLlib训练模型,首先导入MLlib实现ALS算法模型库
import org.apache.spark.mllib.recommendation.ALS
train训练,其模型如下
def train(ratings:RDD[Rating],
rank:Int,
iterations:Int,
lambda:Double): MatrixFactorizationModel
因此可以知道它所需的参数
训练模型需要Rating格式的数据,可以将dataRdd3使用map()方法进行转换
import org.apache.spark.mllib.recommendation.Rating
val ratings=dataRdd3.map{case Array(user,movie,rating)=> Rating(user.toInt,movie.toInt,rating.toDouble)}
ratings.first()
使用case语句来提取各属性对应的变量名,dataRdd3是从u.data文本中得到的数据,因此需要把string换成相应的数据类型,提取简单特征后,就可以调用train()函数训练模型了
val model=ALS.train(ratings,50,10,0.01)
#然后你可能会看到这些悲伤的学习,那就是在提醒你无法访问github,所以你需要做一件事才行
2022-05-04 14:22:56,523 WARN netlib.BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS
2022-05-04 14:22:56,524 WARN netlib.BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS
2022-05-04 14:22:56,784 WARN netlib.LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK
2022-05-04 14:22:56,785 WARN netlib.LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK
model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel = org.apache.spark.mllib.recommendation.MatrixFactorizationModel@14f9fce0
完成那件事情后结果是这样的
scala> val model=ALS.train(ratings,50,10,0.01)
model: org.apache.spark.mllib.recommendation.MatrixFactorizationModel = org.apache.spark.mllib.recommendation.MatrixFactorizationModel@41f1feae
调用train训练数据集后,就会创建推荐引擎模型MatrixFactorizationModel矩阵分解对象,
然后实验predict()函数
scala> val predictedRating=model.predict(100,200)
predictedRating: Double = 2.2492681780689963
从上述执行结果可以看到,该模型预测用户id=100对电影id=200的评级约为2.25
根据用户推荐电影
如果要为某个用户推荐多个物品,可以调用MatrixFactorizationModel对象所提供的recommendProducts(user:Int,num:Int)函数来实现,返回值即为预测得分当前最高的前num个物品,
它就是通过这种排名的方式给用户推荐的,取前num个
定义用户以及推荐数量
val userid=100
val num=10
val topRecoPro=model.recommendProducts(userid,num)
或val topRecoPro=model.recommendProducts(100,10)
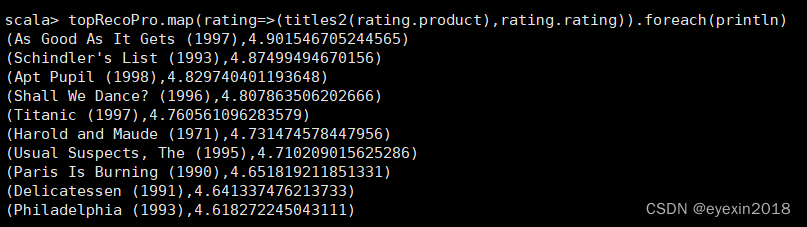
topRecoPro: Array[org.apache.spark.mllib.recommendation.Rating] = Array(Rating(100,316,4.901546705244565), Rating(100,318,4.87499494670156), Rating(100,315,4.829740401193648), Rating(100,251,4.807863506202666), Rating(100,313,4.760561096283579), Rating(100,428,4.731474578447956), Rating(100,12,4.710209015625286), Rating(100,645,4.651819211851331), Rating(100,171,4.641337476213733), Rating(100,735,4.618272245043111))
为了更加直观的检测推荐效果,可以将u.item文件中的电影id与电压名称进行映射,因此要先读取u.item文件并转换为RDD。
val moviesRdd=sc.textFile("/spark/ml-100k/u.item")
对数据格式进行分析,从中提取出电影ID和名称并建立映射关系
val titles=moviesRdd.map(line=>line.split("\\|").take(2)).map(array=>(array()).toInt,array(1))).collectAsMap()
其实这里可以分两步的,先截取并拿前两个:ID和名称
然后再做一次map,将其转换为映射关系
对于100个用户,可以通过Rating对象的rating属性来对推荐的电影名称进行匹配,
简单来说,基于物品和基于用户的推荐,其实就纵向挖掘和横向拓展的区别,基于物品就是一个劲挖掘这个人的特点,然后再给其推荐它喜欢的 产品的同类
基于用户的就是横向开拓,去分析大家都喜欢什么,然后在这群人中进行推荐,这个人喜欢什么,另一个人也可能会喜欢
将物品推荐给用户
如果要为某个物品推荐多个用户,可以调用MatrixFactorizationModel对象所提供的recommendUsers(product:Int,num:Int)函数来实现,其中第一个是物品id,第二个是要推荐给多少个人,其实就是取排名的前num个
scala> model.recommendUsers(100,5)
res19: Array[org.apache.spark.mllib.recommendation.Rating] = Array(Rating(322,100,6.380674684258108), Rating(291,100,6.328806858019871), Rating(495,100,6.306025072991043), Rating(565,100,6.258462719559364), Rating(836,100,6.179792730000435))














 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









