







前面陆续分享了基于policy gradient和DQN实现的深度强化学习任务调度仿真,上次的DQN没有实现fix-qtarget和experience replay,这次再分享实现了这两个方法的DQN任务调度仿真。
经验重放,定义存储和存放次序,这里也可以自行修改
def store_transition(self, s, a, r, s_):
#经验重放
one_hot_action = np.zeros(self.n_actions)
one_hot_action[a] = 1
self.replay_buffer.append((s, one_hot_action, r, s_))
if len(self.replay_buffer) > self.memory_size:
self.replay_buffer.popleft()
在学习过程定期更新网络
def learn(self):
# 定期替换网络参数
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
# print('-------------target_params_replaced------------------')
# sample batch memory from all memory: [s, a, r, s_],采样学习,批量学习
minibatch = random.sample(self.replay_buffer, self.batch_size)
state_batch = [data[0] for data in minibatch]
action_batch = [data[1] for data in minibatch]
next_state_batch = [data[3] for data in minibatch]
# calculate target q-value batch
q_next_batch = self.sess.run(self.q_next, feed_dict={self.s_: next_state_batch})
q_real_batch = []
for i in range(self.batch_size):
q_real_batch.append(minibatch[i][2] + self.gamma * np.max(q_next_batch[i]))
# train eval network
self.sess.run(self._train_op, feed_dict={
self.s: state_batch,
self.action_input: action_batch,
self.q_target: q_real_batch
})
# increasing epsilon
if self.epsilon < self.epsilon_max:
self.epsilon = self.epsilon + self.epsilon_increment
else:
self.epsilon = self.epsilon_max
# print('epsilon:', self.epsilon)
self.learn_step_counter += 1
运行效果
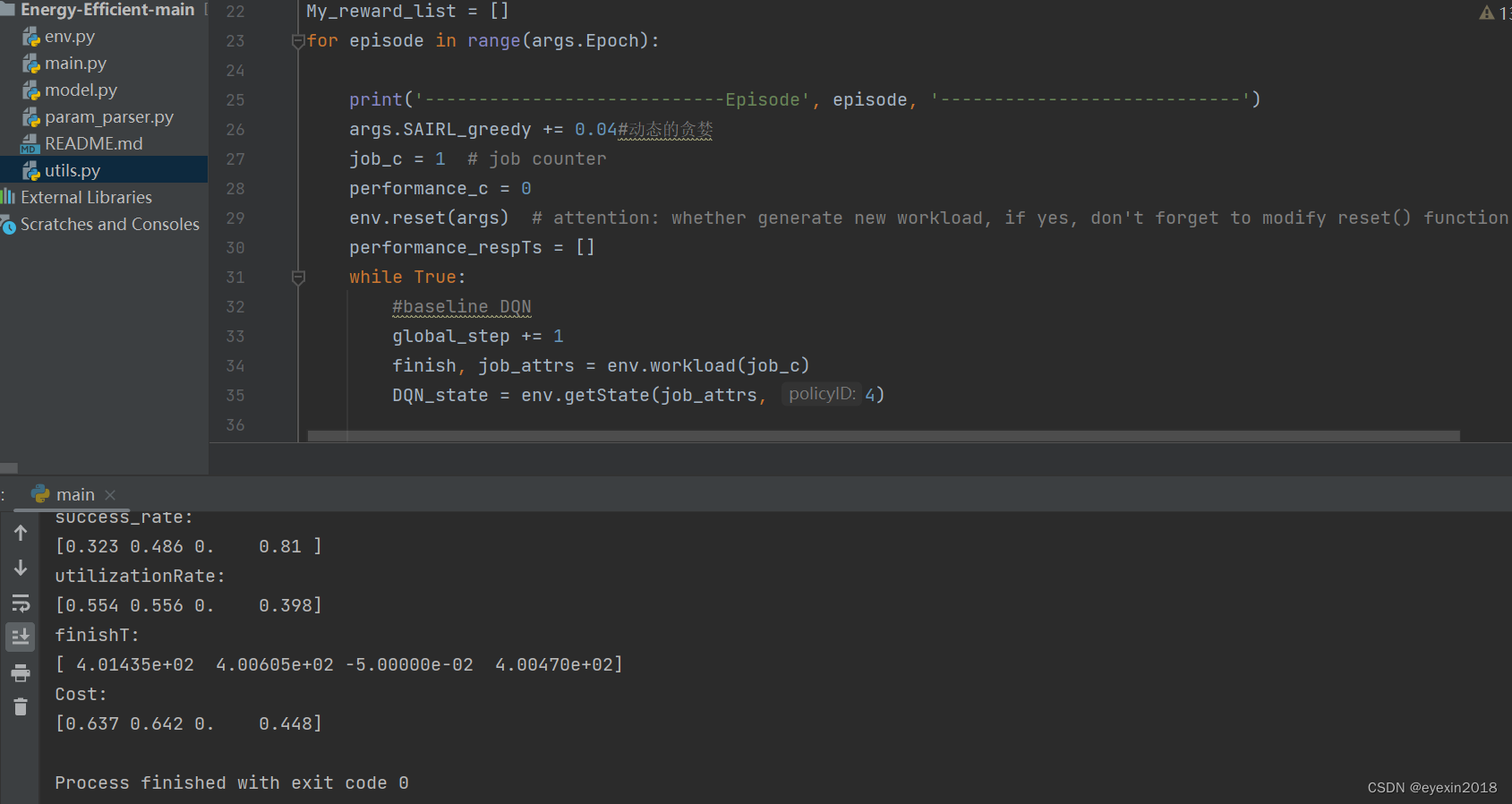
还有一些对比算法
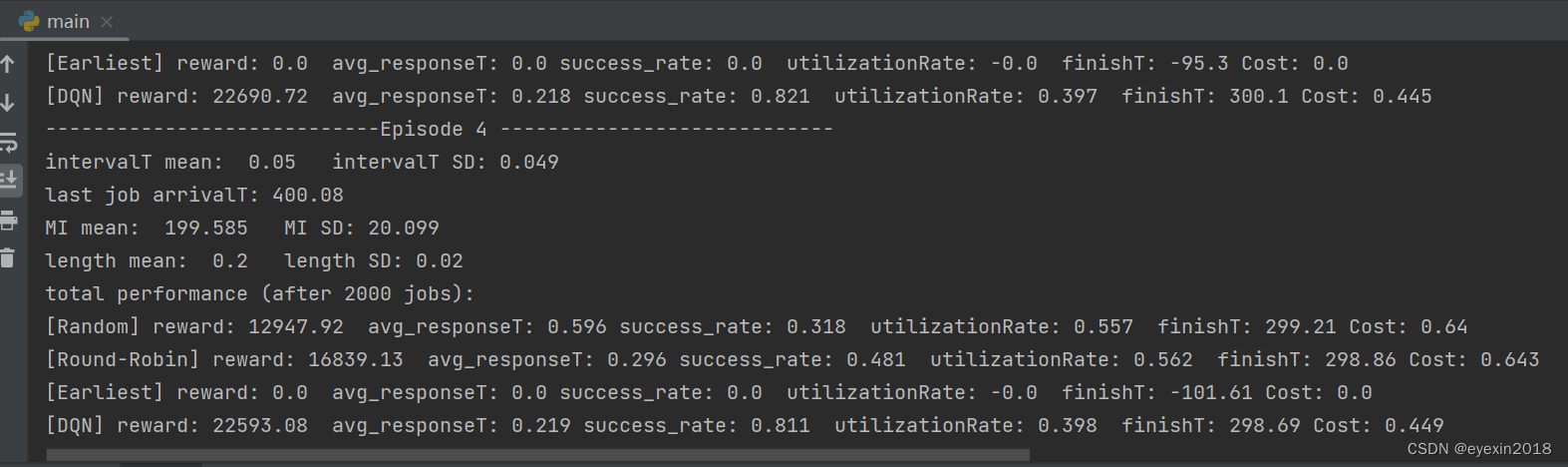
代码是基于TensorFlow1.x实现的,可以在此基础上再修改优化,完整的代码可根据名字去GitHub上下载获取。














 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









