






3 架构
“The architecture of our network is summarized in Figure 2. It contains eight learned layers five convolutional and three fully-connected. Below, we describe some of the novel or unusual features of our network’s architecture. Sections 3.1-3.4 are sorted according to our estimation of their importance, with the most important first.” (Krizhevsky 等, 2017, p. 2) (pdf)
我们的网络架构如图2所示。它包含8个学习层,5个卷积层和3个全连接层。下面,我们描述我们的网络架构的一些新颖或不寻常的特征。3.1 - 3.4节是根据我们对其重要性的估计进行排序,其中最重要的是第一节。

“3.1 ReLU Nonlinearity” (pdf)
3.1 Relu非线性
“The standard way to model a neuron’s output f as a function of its input x is with f (x) = tanh(x) or f (x) = (1 + e^−x)−1. In terms of training time with gradient descent, these saturating nonlinearities are much slower than the non-saturating nonlinearity f (x) = max(0, x). Following Nair and Hinton [20], we refer to neurons with this nonlinearity as Rectified Linear Units (ReLUs). Deep convolutional neural networks with ReLUs train several times faster than their equivalents with tanh units.This is demonstrated in Figure 1, which shows the number of iterations required to reach 25% training error on the CIFAR-10 dataset for a particular four-layer convolutional network. This plot shows that we would not have been able to experiment with such large neural networks for this work if we had used traditional saturating neuron models.” (Krizhevsky 等, 2017, p. 3) (pdf)
将神经元的输出f建模为其输入x的函数的标准方式是f ( x ) = tanh ( x )或f ( x ) = ( 1 + e^-x) - 1。在梯度下降的训练时间方面,这些饱和非线性比非饱和非线性f ( x ) = max( 0 , x)要慢得多。根据Nair和Hinton [ 20 ],我们将具有这种非线性的神经元称为整流线性单元( Rectified Linear Units,ReLUs )。使用ReLUs的深度卷积神经网络的训练速度比使用tanh单元的深度卷积神经网络快几倍。如图1所示,该图显网络,在CIFAR - 10数据集示了对于特定的4层卷积上达到25 %训练误差所需的迭代次数。该图表明,如果我们使用传统的饱和神经元模型,我们将无法为这项工作使用如此大的神经网络进行实验。
解读
(1)饱和非线性函数比非饱和非线性函数达到同样损失率所需的时间要多
“We are not the first to consider alternatives to traditional neuron models in CNNs. For example, Jarrett et al. [11] claim that the nonlinearity f (x) = |tanh(x)| works particularly well with their type of contrast normalization followed by local average pooling on the Caltech-101 dataset. However, on this dataset the primary concern is preventing overfitting, so the effect they are observing is different from the accelerated ability to fit the training set which we report when using ReLUs. Faster learning has a great influence on the performance of large models trained on large datasets.” (Krizhevsky 等, 2017, p. 3) (pdf)
我们并不是第一个在卷积神经网络中考虑替代传统神经元模型的方法。例如,雅雷等人[ 11 ]声称非线性项f ( x ) = |tanh ( x )|在加州理工学院- 101数据集上的对比度归一化和局部平均池化后效果特别好。然而,在这个数据集中,主要的问题是防止过拟合,所以他们所观察到的效果与我们在使用ReLUs时报告的训练集的加速能力不同。快速学习对在大型数据集上训练的大型模型的性能有很大影响。
解读
(1)对于非线性f(x)=|tanh(x)|在101数据集的对比度归一化和平均池化效果好
*对比度归一化:过减去均值并除以标准差的方式对输入进行标准化
步骤: 1.对于每个通道计算像素值的均值
2.每个通道减去均值
3.对于每个通道计算像素标准差
4.每个通道除去方差
对比度归一化有助于消除图像之间的光照差异,使模型更加关注图像的内容而不是亮度变化。一般用作预处理阶段
局部平均池化:定义一个固定大小的窗口(也称为池化窗口)在输入上滑动,计算每个窗口的像素平均值。局部平均池化有助于保留更多的细节信息*
(2)ReLU函数在ImageNet防止过拟合上效果好

“Figure 1: A four-layer convolutional neural network with ReLUs (solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons (dashed line). The learning rates for each network were chosen independently to make training as fast as possible. No regularization of any kind was employed. The magnitude of the effect demonstrated here varies with network architecture, but networks with ReLUs consistently learn several times faster than equivalents with saturating neurons.” (Krizhevsky 等, 2017, p. 3) (pdf)
图1:具有ReLUs (实线)的四层卷积神经网络在CIFAR - 10上达到了25 %的训练错误率,比具有tanh神经元(虚线)的等效网络快6倍。每个网络的学习率是独立选择的,以使训练尽可能快。没有使用任何类型的正则化。这里展示的效果的大小因网络结构而异,但具有ReLUs的网络比具有饱和神经元的网络学习速度快几倍。
解读
(1)在四层卷积神经网络上,ReLU到达25%的错误率比tanh要快6倍
(2)在训练过程中学习率是可以根据网络情况动态调整的
(3)没有使用正则化项(L1,L2),通过使用正则化可以用来防止过拟合
“3.2 Training on Multiple GPUs” (Krizhevsky 等, 2017, p. 3) (pdf)
3.2多Gpu训练
“A single GTX 580 GPU has only 3GB of memory, which limits the maximum size of the networks that can be trained on it. It turns out that 1.2 million training examples are enough to train networks which are too big to fit on one GPU. Therefore we spread the net across two GPUs. Current GPUs are particularly well-suited to cross-GPU parallelization, as they are able to read from and write to one another’s memory directly, without going through host machine memory. The parallelization scheme that we employ essentially puts half of the kernels (or neurons) on each GPU, with one additional trick: the GPUs communicate only in certain layers. This means that, for example, the kernels of layer 3 take input from all kernel maps in layer 2. However, kernels in layer 4 take input only from those kernel maps in layer 3 which reside on the same GPU. Choosing the pattern of connectivity is a problem for cross-validation, but this allows us to precisely tune the amount of communication until it is an acceptable fraction of the amount of computation.” (Krizhevsky 等, 2017, p. 3) (pdf)
单个GTX 580 GPU只有3GB的内存,这限制了在其上可以训练的网络的最大尺寸。事实证明,120万个训练样本足以训练网络,这些网络太大,不适合在一个GPU上运行。因此,我们将网络扩展到两个GPU上。当前的GPU特别适合于跨GPU并行化,因为它们可以直接从彼此的内存中读出和写入,而不必经过宿主机内存。我们采用的并行化方案实质上是将一半的内核(或神经元)放在每个GPU上,并增加了一个技巧:GPU之间只在某些层进行通信。选择连通性的模式是一个交叉验证的问题,但这允许我们精确地调整通信量,直到它是计算量的一个可接受的分数。
解读
(1)单个GPU会限制网络的尺寸
(2)120万个训练样本会使网络太大,不适合在单GPU上运行
解决方案:采用GPU并行化,同时加了一个技巧,GPU之间只在某些层上通信
每个 GPU 可以专注于处理部分网络,而不必在每个训练步骤中都进行全局通信
“The resultant architecture is somewhat similar to that of the “columnar” CNN employed by Cire ̧ san et al. [5], except that our columns are not independent (see Figure 2). This scheme reduces our top-1 and top-5 error rates by 1.7% and 1.2%, respectively, as compared with a net with half as many kernels in each convolutional layer trained on one GPU. The two-GPU net takes slightly less time to train than the one-GPU net2.” (Krizhevsky 等, 2017, p. 3) (pdf)
所得到的结构与Cire ,san等人[ 5 ]所使用的"柱状" CNN有一定的相似性,只是我们的列不是独立的(见图2)。与在一个GPU上训练的每个卷积层有一半核的网络相比,该方案将top - 1和top - 5错误率分别降低了1.7 %和1.2 %。双GPU网络的训练时间略少于单GPU网络2。
解读
(1)采用双GPU进行训练top-1和top-5的错误率分别降低,训练时间也降低
“3.3 Local Response Normalization
3.3局部响应归一化
ReLUs have the desirable property that they do not require input normalization to prevent them from saturating. If at least some training examples produce a positive input to a ReLU, learning will happen in that neuron. However, we still find that the following local normalization scheme aids generalization. Denoting by aix,y the activity of a neuron computed by applying kernel i at position (x, y) and then applying the ReLU nonlinearity, the response-normalized activity bix,y is given by the expression” (Krizhevsky 等, 2017, p. 4)
ReLUs具有不需要输入归一化以防止其饱和的理想特性。如果至少有一些训练样本对一个ReLU产生正的输入,那么学习将在该神经元中发生。然而,我们仍然发现以下局部归一化方案有助于泛化。用aix,y表示在( x , y)处施加核i后再施加ReLU非线性计算得到的神经元活性,响应归一化的活性bix,y由表达式给出

“where the sum runs over n “adjacent” kernel maps at the same spatial position, and N is the total number of kernels in the layer. The ordering of the kernel maps is of course arbitrary and determined before training begins. This sort of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activities amongst neuron outputs computed using different kernels. The constants k, n, α, and β are hyper-parameters whose values are determined using a validation set; we used k = 2, n = 5, α = 10−4, and β = 0.75. We applied this normalization after applying the ReLU nonlinearity in certain layers (see Section 3.5).” (Krizhevsky 等, 2017, p. 4) (pdf)
其中,sum在相同的空间位置上遍历n个’相邻’的内核映射,N是层中的内核总数。当然,核映射的排序是任意的,并且在训练开始之前确定。这种响应归一化实现了一种由实际神经元中发现的类型所激发的侧抑制形式,在使用不同内核计算的神经元输出之间创造了对大型活动的竞争。常数k、n、α和β是超参数,其值使用验证集确定;我们取k = 2,n = 5,α = 10-4,β = 0.75。我们在特定层(见第3.5节)中施加ReLU非线性后应用了这种归一化。
解读
(1)ReLU函数与sigmod、tanh这些函数相比不需要进行归一化
(2)响应归一化:当神经元的输出较大时,归一化的过程将抑制其他神经元的活动,使得只有最强烈的信号能够在网络中脱颖而出。目前归一化方式:batch normalization
“This scheme bears some resemblance to the local contrast normalization scheme of Jarrett et al. [11], but ours would be more correctly termed “brightness normalization”, since we do not subtract the mean activity. Response normalization reduces our top-1 and top-5 error rates by 1.4% and 1.2%, respectively. We also verified the effectiveness of this scheme on the CIFAR-10 dataset: a four-layer CNN achieved a 13% test error rate without normalization and 11% with normalization3.” (Krizhevsky 等, 2017, p. 4) (pdf)
该方案与雅雷等人[ 11 ]的局部对比度归一化方案有一定的相似之处,但由于我们没有减去平均活跃度,所以我们的方案更准确地称为"亮度归一化"。响应规范化将我们的top - 1和top - 5错误率分别降低1.4 %和1.2 %。我们还在CIFAR - 10数据集上验证了该方案的有效性:一个4层的CNN在未归一化的情况下取得了13 %的测试错误率,在归一化的情况下取得了11 %的测试错误率。
解读
(1)与对比度归一化不同的是,采用了响应归一化,其没有减去平均像素值,top-1和top-5的错误率下降
(2)在一个4层cnn的网络中分别取得了13%的未归一化的测试错误率以及11%的归一化的测试错误率
对于3.1和3.3分别提到的对比度归一化和响应归一化使用较少,目前流行的有批量归一化以及组归一化
“3.4 Overlapping Pooling” (Krizhevsky 等, 2017, p. 4) (pdf)
3.4重叠池化
“Pooling layers in CNNs summarize the outputs of neighboring groups of neurons in the same kernel map. Traditionally, the neighborhoods summarized by adjacent pooling units do not overlap (e.g., [17, 11, 4]). To be more precise, a pooling layer can be thought of as consisting of a grid of pooling units spaced s pixels apart, each summarizing a neighborhood of size z × z centered at the location of the pooling unit. If we set s = z, we obtain traditional local pooling as commonly employed in CNNs. If we set s < z, we obtain overlapping pooling. This is what we use throughout our network, with s = 2 and z = 3. This scheme reduces the top-1 and top-5 error rates by 0.4% and 0.3%, respectively, as compared with the non-overlapping scheme s = 2, z = 2, which produces output of equivalent dimensions. We generally observe during training that models with overlapping pooling find it slightly more difficult to overfit.” (Krizhevsky 等, 2017, p. 4) (pdf)
CNN中的池化层汇总了同一核映射中相邻组神经元的输出。传统上,相邻池化单元汇总的邻域不重叠(例如, [ 17,11,4 ])。更准确地说,一个池化层可以被认为是由间隔s个像素的池化单元组成的网格,每个池化单元汇总一个以池化单元位置为中心的大小为z × z的邻域。如果我们设定s = z,我们得到了CNN中常用的传统局部池化。如果我们设定s < z,我们可以得到重叠池化。这就是我们在整个网络中使用的,其中s = 2,z = 3。与不重叠方案s = 2,z = 2相比,该方案的top - 1和top - 5错误率分别降低了0.4 %和0.3 %,从而产生了等效维度的输出
解读
(1)池化层对一组神经元的信息进行压缩和提取最重要的特征
(2)传统网络使用不重叠的池化层,当前网络使用重叠池化层,top-1和top-5的错误率降低
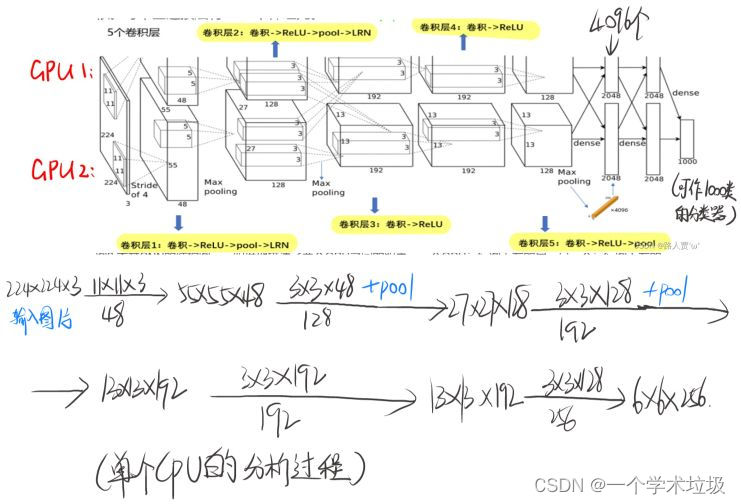
“3.5 Overall Architecture” (Krizhevsky 等, 2017, p. 4) (pdf)
3.5总体架构
“Now we are ready to describe the overall architecture of our CNN. As depicted in Figure 2, the net contains eight layers with weights; the first five are convolutional and the remaining three are fullyconnected. The output of the last fully-connected layer is fed to a 1000-way softmax which produces a distribution over the 1000 class labels. Our network maximizes the multinomial logistic regression objective, which is equivalent to maximizing the average across training cases of the log-probability of the correct label under the prediction distribution.” (Krizhevsky 等, 2017, p. 4) (pdf)
现在我们已经准备好描述我们CNN的整体架构。如图2所示,该网络包含8层带权重的层;前5个为卷积,其余3个为全连接。最后一个全连接层的输出被馈送到一个1000路softmax,它在1000个类标签上产生一个分布。我们的网络最大化多项式逻辑回归目标,这相当于最大化在预测分布下正确标签的对数概率的跨训练案例的平均值。
解读

“The kernels of the second, fourth, and fifth convolutional layers are connected only to those kernel maps in the previous layer which reside on the same GPU (see Figure 2). The kernels of the third convolutional layer are connected to all kernel maps in the second layer. The neurons in the fullyconnected layers are connected to all neurons in the previous layer. Response-normalization layers follow the first and second convolutional layers. Max-pooling layers, of the kind described in Section 3.4, follow both response-normalization layers as well as the fifth convolutional layer. The ReLU non-linearity is applied to the output of every convolutional and fully-connected layer.” (Krizhevsky 等, 2017, p. 4) (pdf)
第二层、第四层和第五层卷积层的内核仅连接到位于同一GPU (见图2)上的前一层的内核映射。第三个卷积层的内核连接到第二层的所有内核映射。全连接层中的神经元与上一层的所有神经元相连。响应归一化层跟随第一和第二卷积层。最大池化层是第3.4节中描述的类型,它遵循响应归一化层和第五卷积层。ReLU非线性被应用于每个卷积层和全连接层的输出。
“Figure 2: An illustration of the architecture of our CNN, explicitly showing the delineation of responsibilities between the two GPUs. One GPU runs the layer-parts at the top of the figure while the other runs the layer-parts at the bottom. The GPUs communicate only at certain layers. The network’s input is 150,528-dimensional, and the number of neurons in the network’s remaining layers is given by 253,440–186,624–64,896–64,896–43,2644096–4096–1000.neurons in a kernel map). The second convolutional layer takes as input the (response-normalized and pooled) output of the first convolutional layer and filters it with 256 kernels of size 5 × 5 × 48. The third, fourth, and fifth convolutional layers are connected to one another without any intervening pooling or normalization layers. The third convolutional layer has 384 kernels of size 3 × 3 × 256 connected to the (normalized, pooled) outputs of the second convolutional layer. The fourth convolutional layer has 384 kernels of size 3 × 3 × 192 , and the fifth convolutional layer has 256 kernels of size 3 × 3 × 192. The fully-connected layers have 4096 neurons each.” (Krizhevsky 等, 2017, p. 5) (pdf)
图2:展示了我们的CNN的架构,明确显示了两个GPU之间的职责划分。一个GPU运行图形顶部的层部分,另一个GPU运行图形底部的层部分。GPU仅在某些层进行通信。网络的输入为150,528维,网络剩余层的神经元个数为253,440 - 186,624 - 64,896 - 64,896 - 43,264-4096 - 4096 - 1000。第二个卷积层将第一个卷积层的(响应归一化和池化)输出作为输入,使用256个大小为5 × 5 × 48的核进行滤波。第三层、第四层和第五层卷积层相互连接,没有任何中间的池化或归一化层。第三个卷积层有384个大小为3 × 3 × 256的核连接到第二个卷积层的(归一化,合并)输出。第四个卷积层有384个3 × 3 × 192大小的核,第五个卷积层有256个3 × 3 × 192大小的核。全连接层有4096个神经元。
解读
















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











