







很长时间没有写博客了。Java学的过程中许多零碎的知识是很有必要写博客记录下来的。尤其对于初学者。
这里介绍利用Heritrix1.14.4对数据进行采集。
当下知名的网络爬虫有Heritrix和Nutch。两者各有利弊:
Nutch 只获取并保存可索引的内容。Heritrix则是照单全收。力求保存页面原貌
Nutch 可以修剪内容,或者对内容格式进行转换。
Nutch 保存内容为数据库优化格式便于以后索引;刷新替换旧的内容。而Heritrix 是添加(追加)新的内容。
Nutch 从命令行运行、控制。Heritrix 有 Web 控制管理界面。
Nutch 的定制能力不够强,不过现在已经有了一定改进。Heritrix 可控制的参数更多。
使用Heritrix更加灵活,可以便利的定制我们自己的爬取逻辑。
我们通过官网下载到Heritrix的源码,部署到我们的MyEclipse上。具体的操作:
将src-->Java-->下的三个文件夹,拷贝到MyEclipse下的工程的src目录下。
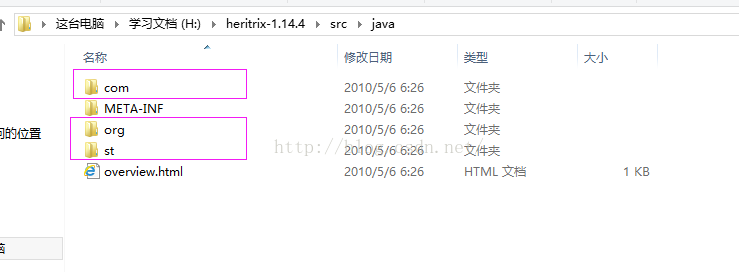
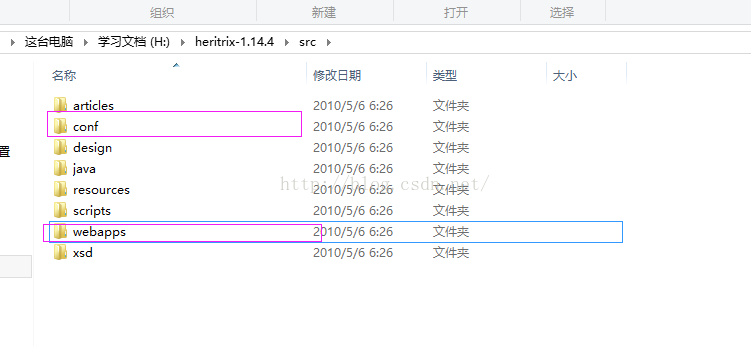
将src目录下的conf和webapps拷贝到工程根目录下。
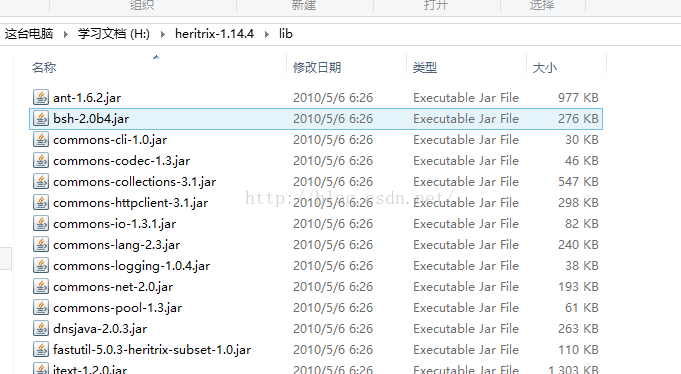
将src-->lib-->下的所有jar包导入工程的lib下:
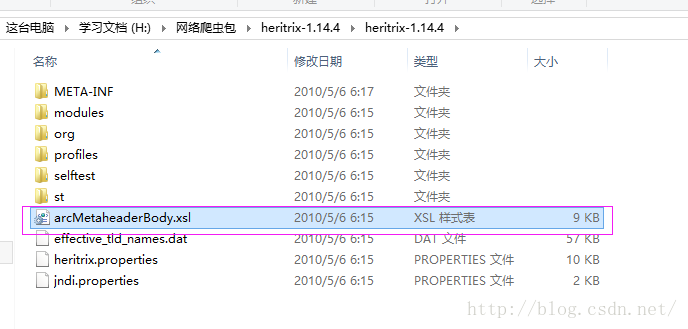
将Heritrix的自带的一个jar解压得到一个arcMetaheaderBody.xsl,文件,该文件存放许多顶级域名:(放到工程下的src目录里)
同样一个配置域名的文件,也要放到相应位置:
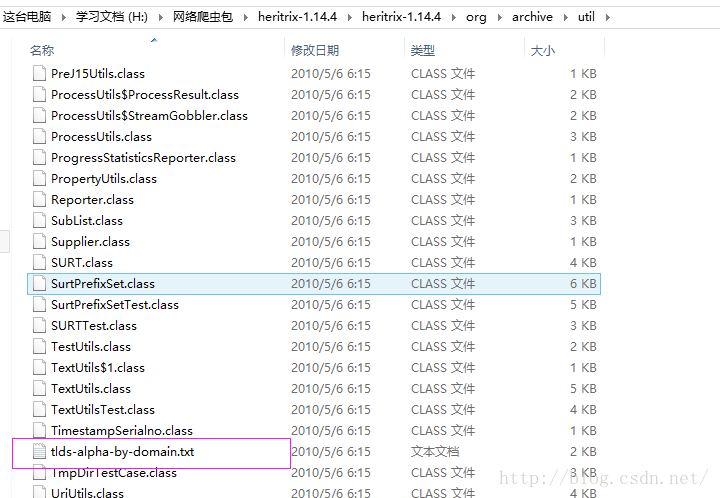
对应工程的位置:扔到util目录下即可:
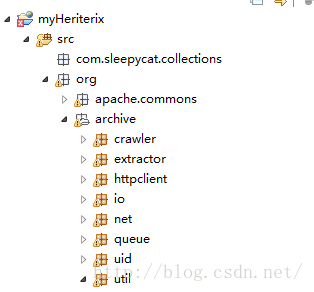
准备工作基本完成,下面对一些配置文件进行配置:
找到Heritrix的配置文件:
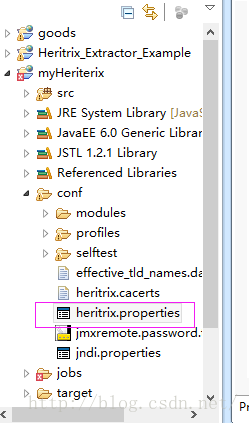
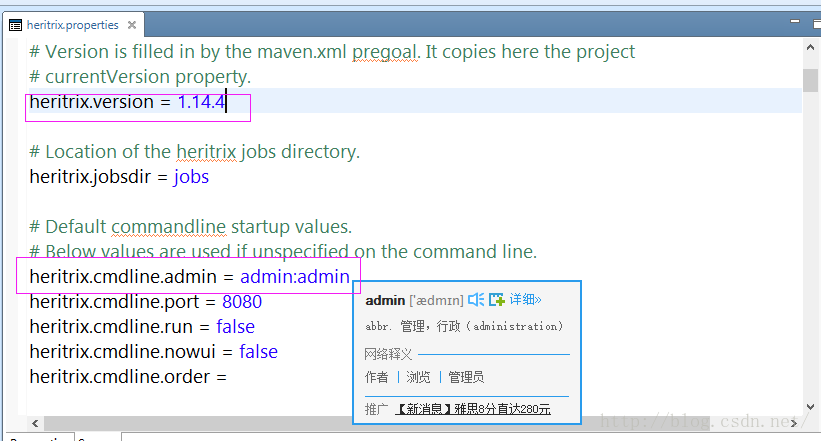
只需添加版本信息和登录WEBUI的用户名和密码即可:
找到Heritrix.java类,就可以启动WEBUI了:当出现以下信息就认为是配置并启动成功了:
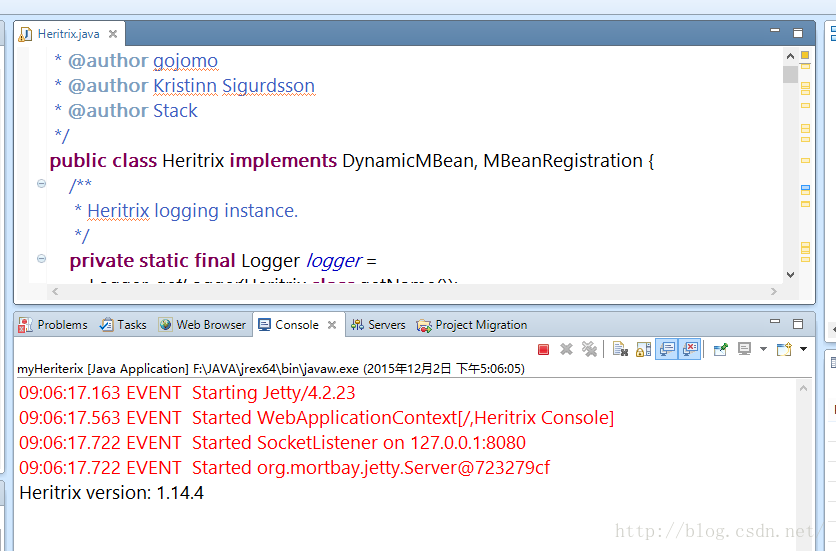
在浏览器中登录进入UI界面:

登录成功:
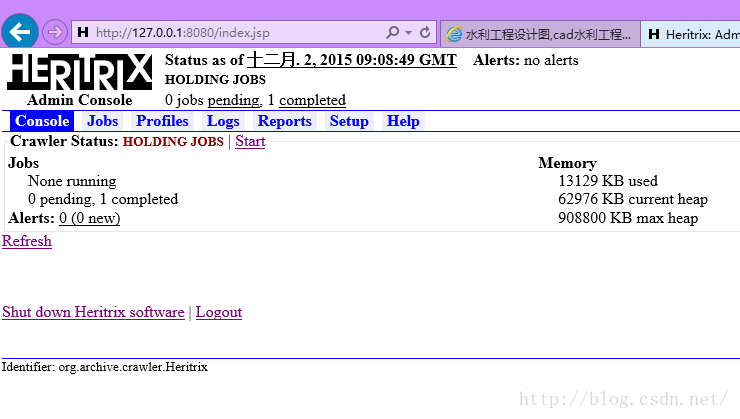
好了,Heritrix1.14.4的配置就完成了,接下来是如何定义并抓取信息。















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









