







通过上篇文章的介绍,对Heritrix有了一定的了解。今天自己定义爬取逻辑,对土木在线网的图纸信息进行了爬取。我讲的不是很详细,大家可以去看看视频:
首先,在后台定义爬取的逻辑,通过观察土木在线网(www.co188.com)的网页链接,我们发现,同一类目下,仅仅尾部不同,因此用正则表达式去代替。
\\d+ :代表多了数字
\\w+ :代表字符
.*(/|\.html)$| :html的正则表达式。
因此我们对于要下载的网页进行一个过虑:
。
在这个包下面定义一个类,继承FrontierScheduler,重写schedule方法。这里有个JAVASE的基础。你去继承
FrontierScheduler这个类时,会发现,必须要有个带参数的构造方法。原因是父类的无参构造方法被一个参数的构造方法覆盖。这里必须有一个有参构造方法。JAVASE基础扎实的同学,可能知道,这里也算一个知识的积累吧。
只有从未入队列的URL集合中抽取出来的URL满足匹配http://ziliao.co188.com/drawing9258/p\\d+.html的URL即可放到URL队列,对其进行下载。
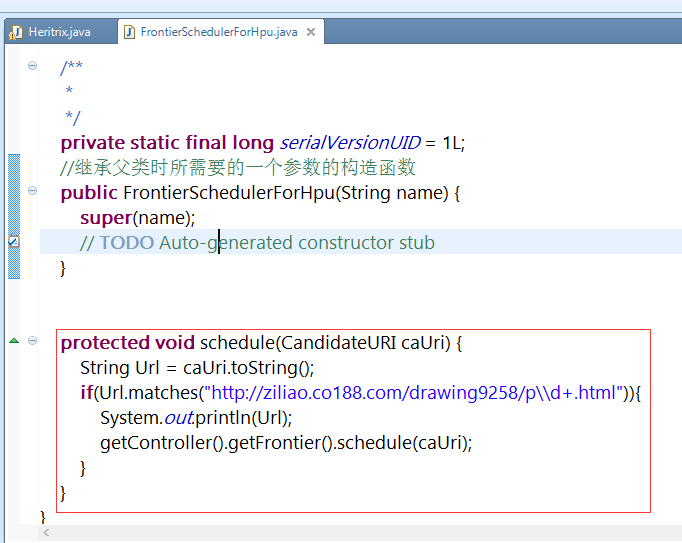
package org.archive.crawler.postprocessor;
import org.archive.crawler.datamodel.CandidateURI;
public class FrontierSchedulerForHpu extends FrontierScheduler {
/**
*
*/
private static final long serialVersionUID = 1L;
//继承父类时所需要的一个参数的构造函数
public FrontierSchedulerForHpu(String name) {
super(name);
// TODO Auto-generated constructor stub
}
protected void schedule(CandidateURI caUri) {
String Url = caUri.toString();
if(Url.matches("http://ziliao.co188.com/drawing9258/p\\d+.html")){
System.out.println(Url);
getController().getFrontier().schedule(caUri);
}
}
}
在这边定义完毕之后,启动Heritrix。
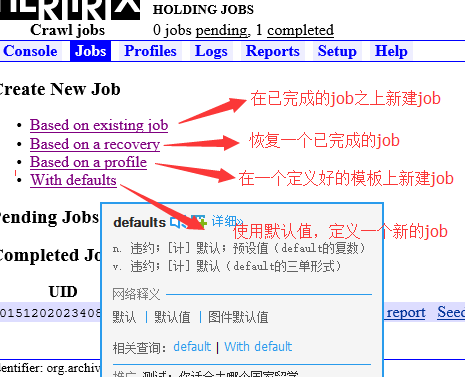
在WEBUI界面,去新建我们的job。若是第一次新建job,可以使用默认值新建job。
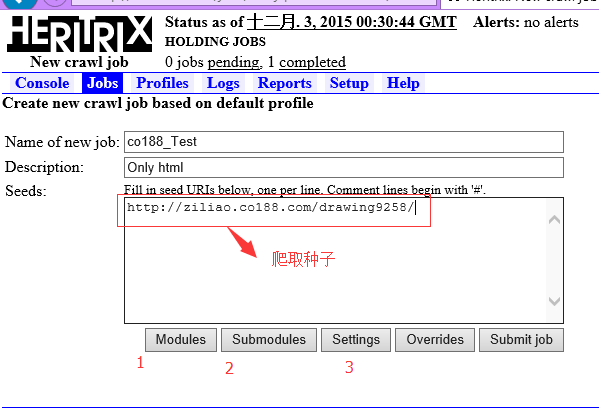
接下是对各项的定义。由于我们只需要抽取html即可,一些css、js可以去除,不对其进行抽取,既可以加快爬取速度,亦可以方便接下来的数据的保存工作。
接着配置Modules的选项。
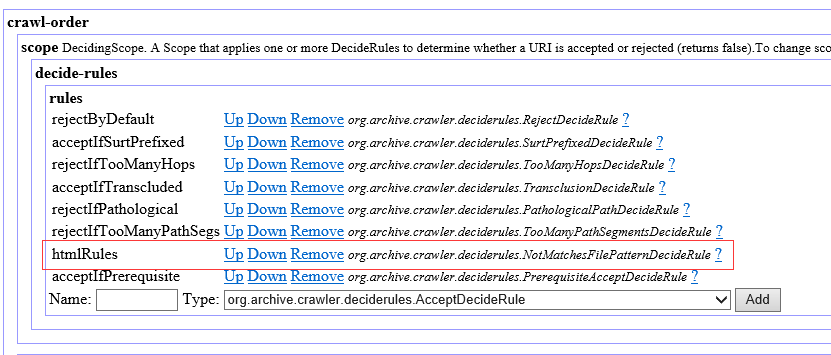
1.Select Crawl Scope,选择org.archive.crawler.deciderules.DecidingScope。 这个配置是为了只抓取html
2.Select URI Frontier,默认值
3.Select Pre Processors,默认值
4.Select Fetchers,默认值
5.Select Extractors,将css,js,remove掉。提升爬取效率。

6.
Select Writers,选择 org.archive.crawler.writer.MirrorWriterProcessor,并将 org.archive.crawler.writer.ARCWriterProcessor移除。
这里是选择下载下来是以什么格式存储,选择镜像模式。
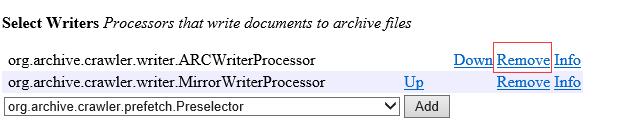
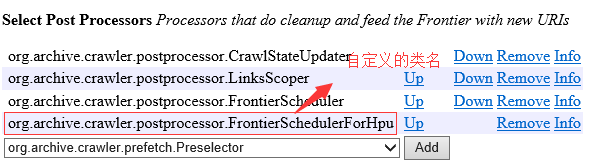
7.Select Post Processors,添加自定义的逻辑 org.archive.crawler.postprocessor.FrontierSchedulerForHpu。后缀是自己的类名,每个人都不相同。
8.Select Statistics Tracking,默认值。
接下来是对Setting的设置:
直接上图:


至此,即可启动job,完成网络爬取。
最终爬取结果:















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









